来源公众号:有三AI https://mp.weixin.qq.com/s/Tuwg070YiXp5Rq4vULCy1w
深度学习模型中的Normalization
数据经过归一化和标准化后可以加快梯度下降的求解速度,这就是Batch Normalization等技术非常流行的原因,Batch Normalization使得可以使用更大的学习率更稳定地进行梯度传播,甚至增加网络的泛化能力。
1 什么是归一化/标准化
Normalization是一个统计学中的概念,可以称它归一化或者规范化,它并不是一个完全定义好的数学操作(如加减乘除)。它通过将数据进行偏移和尺度缩放调整,在数据预处理时是非常常见的操作,在网络的中间层也很频繁的被使用。
1. 线性归一化
最简单来说,归一化是指将数据约束到固定的分布范围,比如8位图像的0~255像素值,比如0~1。
在数字图像处理领域有一个很常见的线性对比度拉伸操作:
X=(x-xmin)/(xmax-mxin)
它常常可以实现下面的增强对比度的效果:

不过以上的归一化方法有个非常致命的缺陷,当X最大值或者最小值为孤立的极值点,会影响性能。
2. 零均值归一化/Z-score标准化
零均值归一化也是一个常见的归一化方法,被称为标准化方法,即每一变量值与其平均值之差除以该变量的标准差。
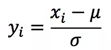
经过处理后的数据符合均值为0,标准差为1的分布,如果原始的分布是正态分布,那么z-score标准化就将原始的正态分布转换为标准正态分布,机器学习中的很多问题都是基于正态分布的假设,这是更加常用的归一化方法。
以上两种方法都是线性变换,对输入向量X按比例压缩再进行平移,操作之后原始有量纲的变量变成无量纲的变量。不过它们不会改变分布本身的形状,下面以一个指数分布为例:

如果想要改变分布本身的形状,下面介绍两种:
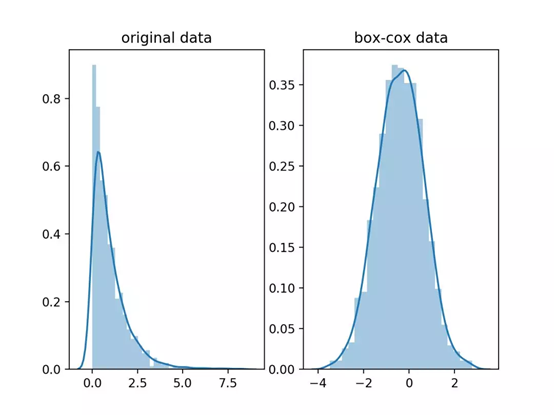
3.正态分布Box-Cox变换
box-cox变换可以将一个非正态分布转换为正态分布,使得分布具有对称性,变换公式如下:
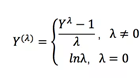
在这里lamda是一个基于数据求取的待定变换参数,Box-Cox的效果如下:
4. 直方图均衡化
直方图均衡也可以将某一个分布归一化到另一个分布,它通过图像的灰度值分布,即图像直方图来对图像进行对比度进调整,可以增强局部的对比度。
它的变换步骤如下:
(1)计算概率密度和累积概率密度;
(2)创建累积概率到灰度分布范围的单调线性映射T;
(3)根据T进行原始灰度值到新灰度值的映射。
直方图均衡化将任意的灰度范围映射到全局灰度范围之间,对于8位的图像就是(0,255),它相对于直接线性拉伸,让分布更加均匀,对于增强相近灰度的对比度很有效,如下图:
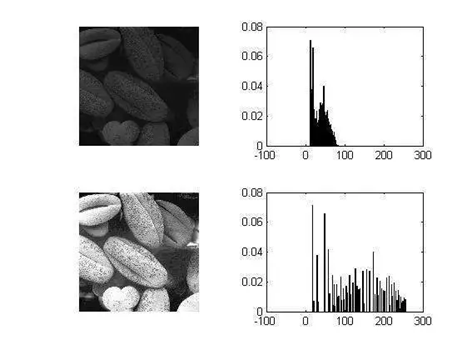
综上,归一化数据的目标,是为了让数据的分布变得更加符合期望,增强数据的表达能力。
在深度学习中,因为网络的层数非常多,如果数据分布在某一层开始有明显的偏移,随着网络的加深这一问题会加剧(这在BN的文章中被称之为internal covariate shift),进而导致模型优化的难度增加,甚至不能优化。所以,归一化就是要减缓这个问题。
2 Batch Normalization
1、基本原理
现在一般采用批梯度下降方法对深度学习进行优化,这种方法把数据分为若干组,按组来更新参数,一组中的数据共同决定了本次梯度的方向,下降时减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也下降了很多。
Batch Normalization(简称BN)中的batch就是批量数据,即每一次优化时的样本数目,通常BN网络层用在卷积层后,用于重新调整数据分布。假设神经网络某层一个batch的输入为X=[x1,x2,...,xn],其中xi代表一个样本,n为batch size。
首先,需要求得mini-batch里元素的均值:
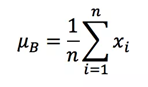
接下来,求取mini-batch的方差:
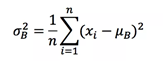
这样就可以对每个元素进行归一化:
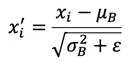
最后,进行尺度缩放和偏移操作,这样可以变换回原始的分布,实现恒等变换,这样的目的是为了补偿网络的非线性表达能力,因为经过标准化之后,偏移量丢失。具体的表达如下,yi就是网络的最终输出。
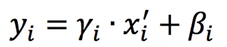
假如gamma等于方差,beta等于均值,就实现了恒等变换。
从某种意义上来说,gamma和beta代表的其实是输入数据分布的方差和偏移。对于没有BN的网络,这两个值与前一层网络带来的非线性性质有关,而经过变换后,就跟前面一层无关,变成了当前层的一个学习参数,这更加有利于优化并且不会降低网络的能力。
对于CNN,BN的操作是在各个特征维度之间单独进行,也就是说各个通道是分别进行Batch Normalization操作的。
如果输出的blob大小为(N,C,H,W),那么在每一层normalization就是基于N*H*W个数值进行求平均以及方差的操作。
2.BN带来的好处。
(1) 减轻了对参数初始化的依赖,这是利于调参;
(2) 训练更快,可以使用更高的学习率;
(3) BN一定程度上增加了泛化能力,dropout等技术可以去掉。
3.BN的缺陷
从上面可以看出,batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。这一特性,导致batch normalization不适合以下的几种场景:
(1) batch非常小,比如训练资源有限,无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
(2) rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。
4.BN的改进
针对BN依赖于batch的这个问题,BN的作者亲自现身提供了改进,即在原来的基础上增加了一个仿射变换。
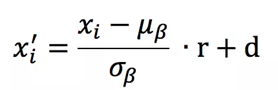
其中参数r,d就是仿射变换参数,它们是通过如下的方式进行计算:
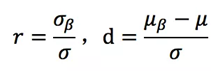
其中参数都是通过滑动平均的方法进行更新
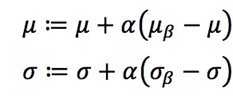
所以r和d就是一个跟样本有关的参数,通过这样的变换来进行学习,这两个参数在训练的时候并不参与训练。
在实际使用的时候,先使用BN进行训练得到一个相对稳定的移动平均,网络迭代的后期再使用刚才的方法,称为Batch Renormalization,当然r和d的大小必须进行限制。
3 Batch Normalization的变种
Normalization思想非常简单,为深层网络的训练做出了很大贡献。因为有依赖于样本数目的缺陷,所以也被研究人员进行改进。说的比较多的就是Layer Normalization与Instance Normalization,Group Normalization。
前面说了Batch Normalization各个通道之间是独立进行计算,如果抛弃对batch的依赖,也就是每一个样本都单独进行normalization,同时各个通道都要用到,就得到了Layer Normalization。
与Batch Normalization仅针对单个神经元不同,Layer Normalization考虑了神经网络中一层的神经元。如果输出的blob大小为(N,C,H,W),那么在每一层Layer Normalization就是基于C*H*W个数值进行求平均以及方差的操作。
Layer Normalization把每一层的特征通道一起用于归一化,如果每一个特征层单独进行归一化,也就是限制在某一个特征通道内,那就是instance normalization了。
如果输出的blob大小为(N,C,H,W),那么在每一层Instance Normalization就是基于H*W个数值进行求平均以及方差的操作。对于风格化类的图像应用,Instance Normalization通常能取得更好的结果,它的使用本来就是风格迁移应用中提出。
Group Normalization是Layer Normalization和Instance Normalization 的中间体, Group Normalization将channel方向分group,然后对每个Group内做归一化,算其均值与方差。
如果输出的blob大小为(N,C,H,W),将通道C分为G个组,那么Group Normalization就是基于G*H*W个数值进行求平均以及方差的操作。
在Batch Normalization之外,有人提出了通用版本Generalized Batch Normalization,有人提出了硬件更加友好的L1-Norm Batch Normalization等。
另一方面,以上的Batch Normalization,Layer Normalization,Instance Normalization都是将规范化应用于输入数据x,Weight normalization则是对权重进行规范化。
Normalization如何使用?有以下基本建议:
(1) 正常的处理图片的CNN模型都应该使用Batch Normalization。只要保证batch size较大(不低于32),并且打乱了输入样本的顺序。如果batch太小,则优先用Group Normalization替代;
(2) 对于RNN等时序模型,有时候同一个batch内部的训练实例长度不一(不同长度的句子),则不同的时态下需要保存不同的统计量,无法正确使用BN层,只能使用Layer Normalization;
(3) 对于图像生成以及风格迁移类应用,使用Instance Normalization更加合适。
4 Batch Normalization的思考
关于Batch Normalization的思考,normalization机制至今仍然是一个非常open的问题,最关心的是Batch Normalization为什么有效。
Batch Normalization(其他方法的差异主要在于计算normalization的元素集合不同)是N*H*W,Layer Normalization是C*H*W,Instance Normalization是H*W,Group Normalization是G*H*W。
关于Normalization的有效性,有以下几个主要观点:
(1) 主流观点,Batch Normalization调整了数据的分布,不考虑激活函数,它让每一层的输出归一化到了均值为0方差为1的分布,这保证了梯度的有效性,比如BN的原始论文认为的缓解了Internal Covariate Shift(ICS)问题;
(2) 可以使用更大的学习率,BN有效是因为用上BN层之后可以使用更大的学习率,从而跳出不好的局部极值,增强泛化能力,在它们的研究中做了大量的实验来验证;
(3) 损失平面平滑,BN有效的根本原因不在于调整了分布,因为即使是在BN层后模拟ICS,也仍然可以取得好的结果。BN有效的根本原因是平滑了损失平面。Z-score标准化对于包括孤立点的分布可以进行更平滑的调整。