SVM全称支持向量机,为什么起这么个名字,这是因为数据集中有些样本被称为支持向量,在后面你就会知道。SVM是目前为止小编觉得较难的一个模型,因为这里面涉及带约束条件的最优化问题,小编也是看了一定的资料、视频才能理解一二。为了帮助更多的人更好的理解SVM,小编尽量使用通俗的文字、较少的数学公式来写这篇文章。
一、SVM的目标
讲解一个模型,最首要的是阐明模型的目标。SVM也是在二分类问题中找到一个超平面来划分数据集。
对于找到一个超平面来划分数据集,我相信各位一定不陌生,逻辑回归、感知机的目标也是找到一个超平面来划分数据集。那么问题就来了,使用不同的模型能找到不同的划分超平面,甚至使用同一种模型不同的设置也能找到不同的划分超平面,那么到底哪种超平面好呢,我们能不能通过一种方法直接找到最好的划分超平面。
下面我们通过图来直观的感受下哪个超平面最好。
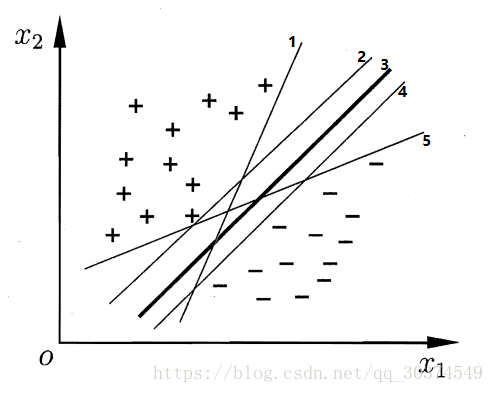
上面有5条直线能正确的划分数据集,但直观的看,我们觉得中间的3号粗线是最好的一条直线。为什么我们认为中间的粗线是最好的呢?因为它对数据集局部扰动的“容忍”性最好。下面我们来看下这幅图。
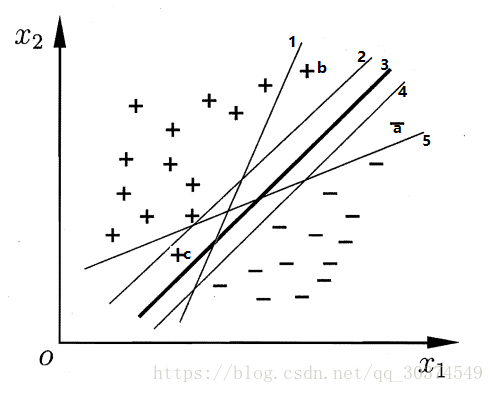
当出现负样本a时,直线5将分类出错,出现正样本b时,直线1将分类出错,出现正样本c时,直线2将分类出错。通过上面的例子,我们可以形象的描述,如果一个划分平面太接近数据样本时,它对数据样本的扰动很敏感,也就是“容忍”性低。所以SVM的目标就是找到一个划分平面,这个平面到数据样本的距离最大,也就保证了它对数据样本扰动的“容忍”性最好。
二、SVM的优化函数
上一节,我们了解到SVM的目标就是找到一个距离数据样本最远的划分超平面,那么超平面到数据样本的距离怎么度量呢?我们先来看下面一幅图。

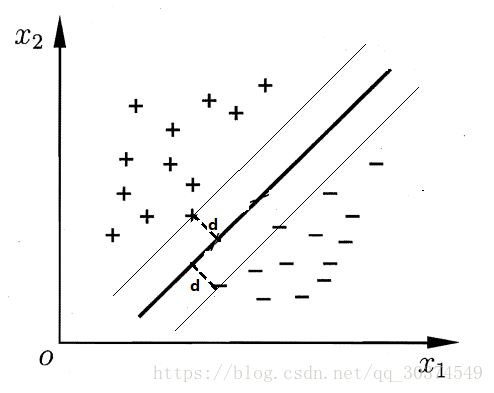
通过上图可以发现,超平面到数据样本的距离就是离超平面最近的样本到超平面的距离。还记得文章开头提到的支持向量吗,离超平面最近的那些样本就被称为支持向量。有了这些知识,我们就可以推导出SVM的优化函数,具体如下。
在一批数据样本 {},其中
,
{-1,+1},找到一个超平面,此平面能正确划分数据集,并到数据集的距离最大。
超平面可通过 来描述,所以超平面到数据样本的距离d的计算公式如下。
其中
为支持向量。
我们的优化目标就是 max d。但我们不要忘记,最大化d的前提是超平面能正确划分数据集,故超平面要满足如下条件。
任意的
= 1
任意的
= -1
上式两边同除d,结果如下。
任意的
= 1
任意的
= -1
其中 ,
。
我们知道一个超平面方程的法向量和截距同时除以一个常数,超平面不变,所以 和
描述的是同一个超平面。并且,通过这个变换,我们知道支持向量
有
或
,利用这个我们有如下结论。
因此SVM的优化目标就是在正确分类的条件下最大化d,其中最大化d等价于最小化 ,所以SVM的优化函数如下。
s.t.
i = 1,2,...,m。
做到这里,我们知道SVM的优化问题是一个凸二次规划问题,能直接用现成的优化计算包求解,但我们还可以用更高效的方法,这就是利用原问题的对偶函数来求解,下面我们就来看看对偶问题。
三、对偶问题。
关于带不等式约束优化的对偶问题,可以看吴立德教授的 约束优化理论。下面我将直接就求解问题进行展开讨论。

知道了原问题的对偶问题,下面我们就一步一步解决对偶问题。解决对偶问题分两步走。
1.首先固定,求解无约束条件的最小化问题,即
。
2.再接着求解带约束条件的优化问题。
求解无约束条件的最小化问题,即,函数分别对w,b的偏导为0.
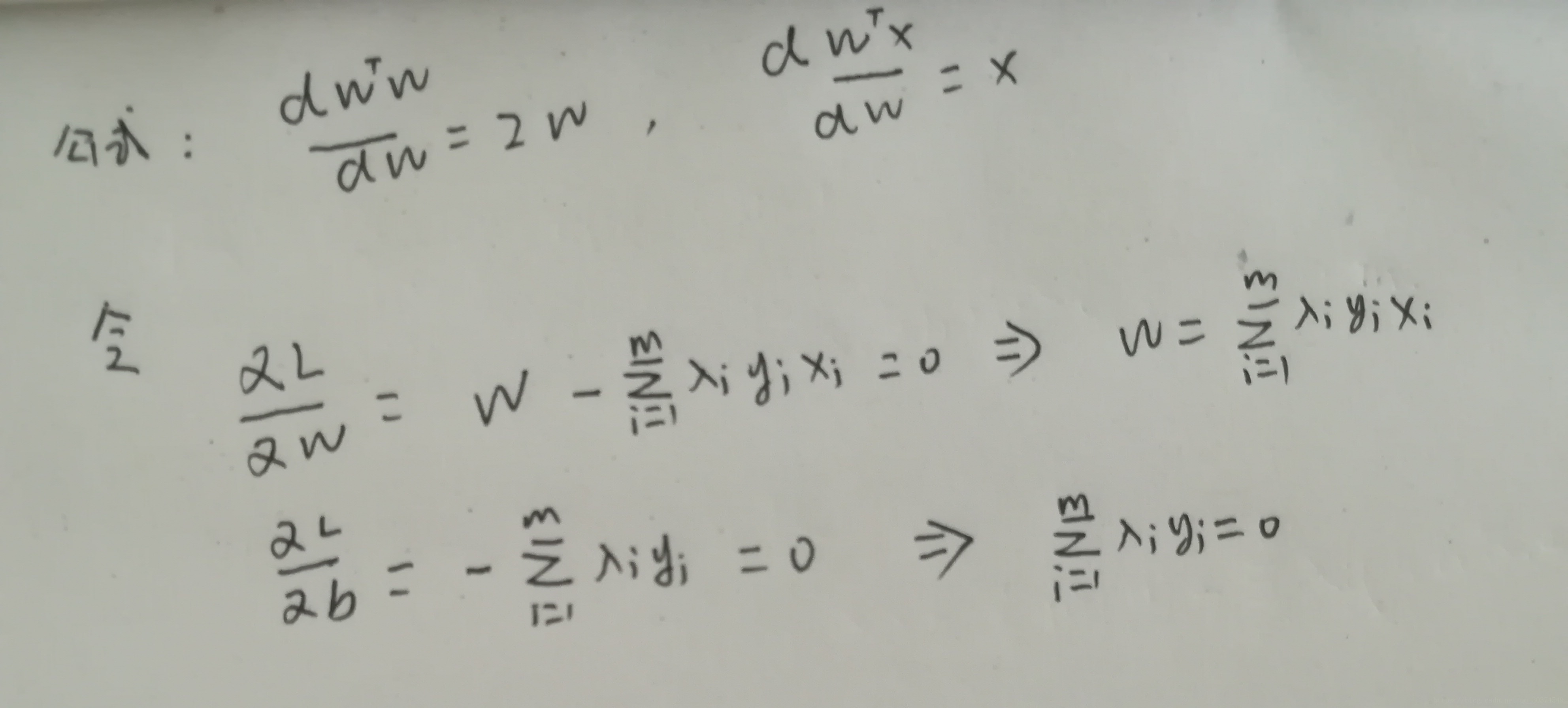
将w代回L函数,得到L函数如下。
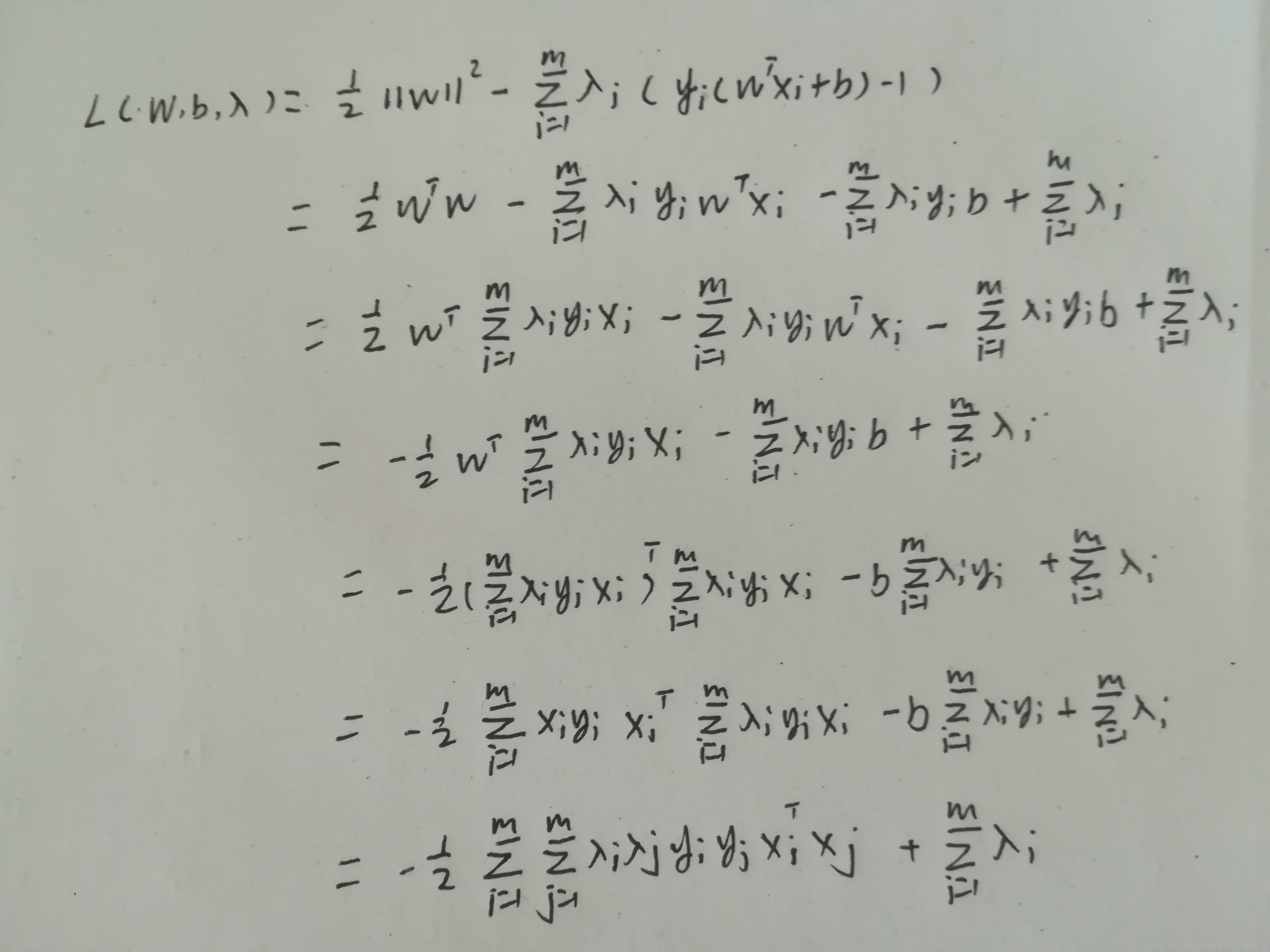
接着我们就要求解一个带约束条件的优化问题。
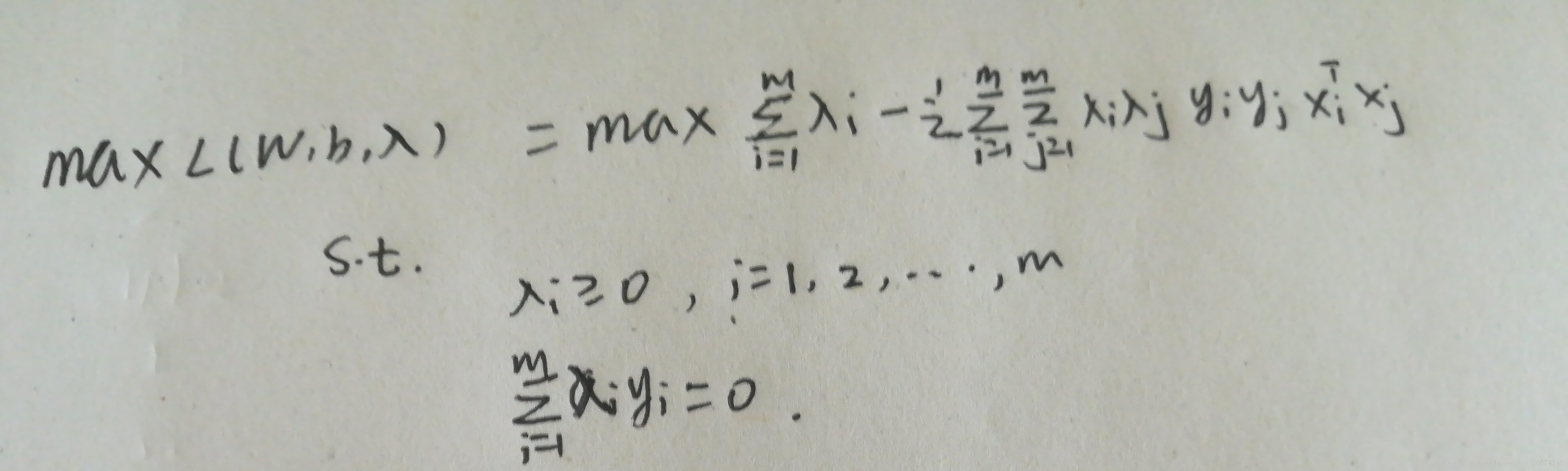
可以利用高效的SMO算法来求解,解出之后,w,b的表达式如下。
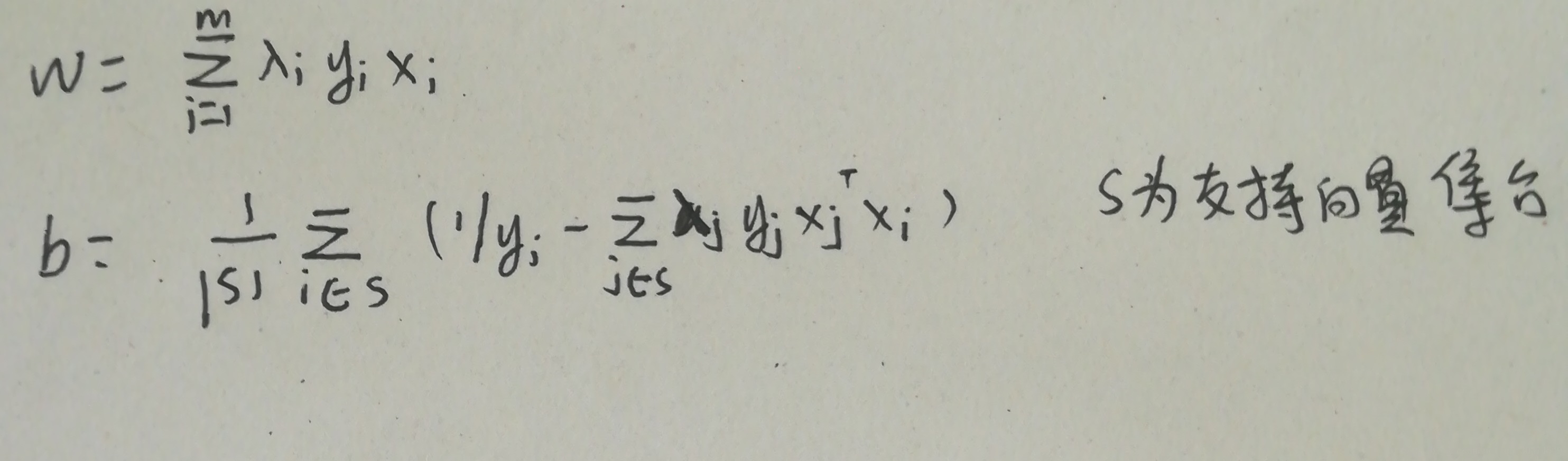
到此,我们的任务就完成了,模型 也构建完成。
四、核函数
到了这里,我们再总结下SVM实现了什么。SVM的目标也是找到一个能正确划分数据样本的超平面,不过这个超平面到数据样本的距离最大,这使得这个超平面对数据样本的扰动“容忍”性最好。由于SVM的目标也是找到一个超平面,所以SVM在数据样本不是线性可分的情况下性能很不理想,那有什么方法能解决这个问题吗?
我们先看下面一幅图。
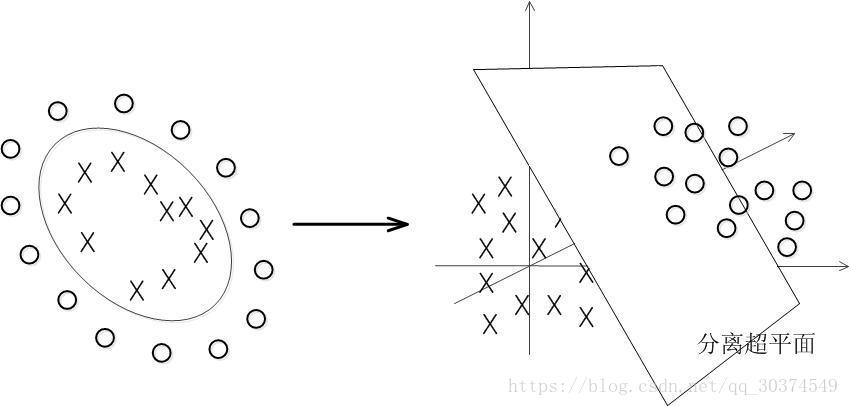
图的左边是数据样本在二维平面的分布情况,可以看到,数据样本不是线性可分的。图的右边是数据样本被映射到三维空间上的分布情况,可以看到,在三维空间存在一个超平面可以划分数据集。
所以,我们就有一个想法来解决数据样本不是线性可分的问题了,那就是在低维空间线性不可分的数据样本被映射到高维空间可能线性可分。幸运的是,如果数据样本原始空间是有限维,那么一定存在一个高维空间使得数据样本线性可分。
有了这个想法,似乎SVM解决数据样本线性不可分的情况就很简单了,大致分如下两步:
1.把数据样本映射到新的高维空间。
2.在高维空间执行SVM,找到一个超平面。
想法很不错,貌似也可行,但如果映射后的空间维度很大,甚至无穷维,那么在SVM求解的时候要计算两个向量的内积变得很困难,为了解决这个问题,于是SVM就引进了核函数。
核函数的作用是计算两个高维向量的内积不是在高维空间直接计算,而是通过一个函数在两个向量的原始空间进行计算。具体公式如下。
一般来说,我们要先知道低维空间是怎么映射到高维空间的才能构造出相应的核函数,但幸运的是,任何一个核函数总能找到对应的映射方式,这就是说我们只需关注核函数,而不需要关注空间是怎么映射的。
常用的核函数有如下:
1.线性核。,这相当于不使用核函数,也就是数据样本在原始空间就是线性可分的,不需要进行空间映射。
2.多项式核。。
3.高斯核。。
4.拉普拉斯核。。
五、sklearn上的用法
下面我们来看看在sklearn上怎么使用SVM。一个简单的例子如下。
from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict([[2., 2.]])
array([1])SVC类的参数说明。
Parameters:
C : float, optional (default=1.0)。
错误项的惩罚系数。C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
kernel : string, optional (default=’rbf’)。
算法中采用的核函数类型,可选参数有:
‘linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
degree : int, optional (default=3)
多项式核中的阶数d。
gamma : float, optional (default=’auto’)
高斯核中的参数。
本次文章就到这里,文中有纰漏之处,请多多指正。
