目录
问题:百度防爬虫机制:动态加载图片,当值无法读取 html源码中的图像src。后续用go语言实现2种爬虫方法
解决方案:
acjson 方法
使用动态加载时候的acjson方法,就是原生百度图片搜索,临时出现的acjson文件,通过一些规律自己编写acjson,方法就是修改keywords 和pn的值,看下面例子
url = "http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord="+keyworlds +
"&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word="+keyworlds +"&face=0&istype=2nc=1&pn="+ strconv.Itoa(page)+"&rn=60"如下图,不停请求上图url,其中keyworlds是关键字,如下面例中 “周杰伦”,page则是从0开始每次加一。请求得到的html中,过滤出 objectURL=“http://.....jpg”等,然后去下载。
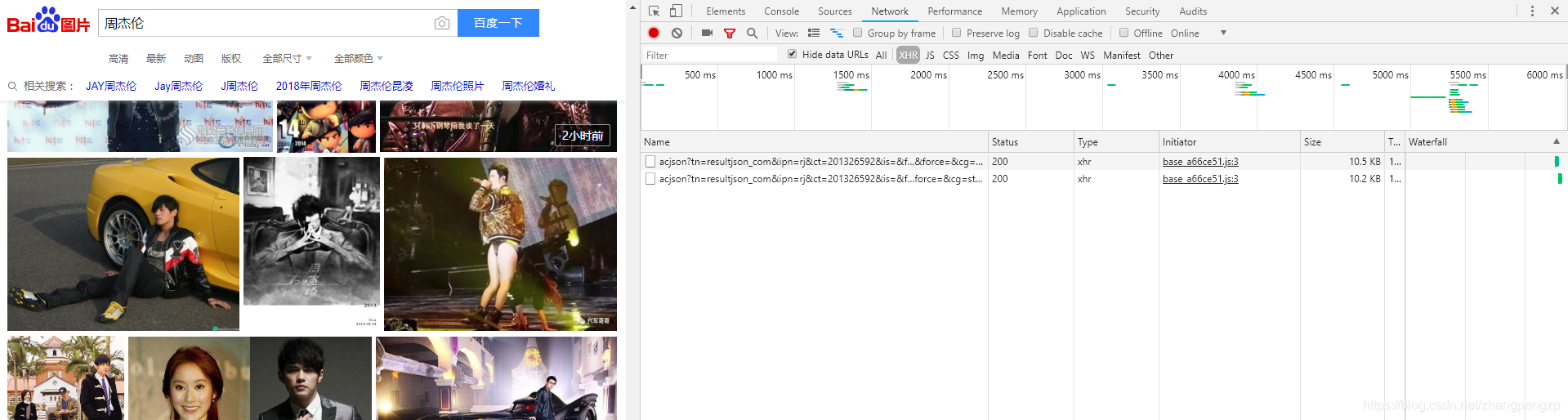
下面是在google百度搜索周杰伦,滚动页面时候产生的acjson文件 (方法,F12 , network XHR,然后滚动鼠标,下滑页面)
flip方法
就是采用flip网站代替,这是百度检索图片的另一种方式,改变其中的page,每一页有20图片,其实大家可以打开这个网站,将page置为0,关键字置为“周杰伦”,如下( pn每次加20即可到下一页)
http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=周杰伦&pn=0&gsm=140&ct=&ic=0&lm=-1&width=0&height=0url = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+keyworlds +"&pn="
+ strconv.Itoa(page*20)+"&gsm=140&ct=&ic=0&lm=-1&width=0&height=0"当然,第一种动态链接,会有很多图片无法下载,虽然经过判断,但仍然会得到一些警告图片,如下图,且效率不如第二种方法

方法代码
package main
import(
"fmt"
"net/http"
"os"
"regexp"
"io/ioutil"
"strconv"
"strings"
)
var word = "周杰伦"
var downloadNumber int
var imageDir string
func makeDir(savePath string){
err := os.MkdirAll(imageDir ,0766)
if err != nil{
fmt.Println("create dir error")
}else{
fmt.Println("create dir success")
}
}
var page = 0
func Pa( keyworlds string , number int , savePath string){
downloadNumber = number
imageDir = savePath
makeDir(savePath)
var url string
for page<100 && i < downloadNumber {
// 第一种方式,acjson
//url = "http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord="+keyworlds +"&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word="+keyworlds +"&face=0&istype=2nc=1&pn="+ strconv.Itoa(page)+"&rn=60"
//第二种方式,flip
url = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+keyworlds +"&pn="+ strconv.Itoa(page*20)+"&gsm=140&ct=&ic=0&lm=-1&width=0&height=0"
page++
html := getHtmlBody(url)
downloadImages(html)
}
}
func getHtmlBody(url string)string{
resp, err := http.Get(url)
if err != nil {
fmt.Println("err = ",err)
}
defer resp.Body.Close()
fmt.Println("body" , resp.Body)
buf := make([]byte, 4 *1024)
var tmp string
for{
n, err := resp.Body.Read(buf)
if err != nil{
fmt.Println("read over", err)
break
}
tmp += string(buf[:n])
}
return tmp
}
func downloadImages(body string) {
// 第一种方法,匹配的正则表达式,主要是 objURL的 o的大小写问题
//reg :=regexp.MustCompile(`\"ObjURL\":\"(.*?)\"\,`)
// 第二种方法,匹配的正则表达式
reg :=regexp.MustCompile(`\"objURL\":\"(.*?)\"\,`)
result := reg.FindAllStringSubmatch(body, -1)
fmt.Println()
for _,data := range result{
//fmt.Println(data[0])
//fmt.Println(data[1])
url := strings.Replace(data[1] ,`\` , "" , -1)
if i >= downloadNumber {
return
}
download(url)
}
}
var i = 0
func download(url string){
res,err := http.Get(url)
if err != nil || res.StatusCode != 200{
//fmt.Printf("下载失败:%s", err)
return
}
data ,err2 := ioutil.ReadAll(res.Body)
if err2 != nil {
fmt.Printf("读取数据失败")
}
fmt.Printf("开始下载:%d ,%s\n",i, url)
ioutil.WriteFile(imageDir+"/"+ strconv.Itoa(i)+".jpg", data, 0644)
i++
}
func main() {
Pa("周杰伦", 100,"周杰伦")
}代码2种方法的切换:
修改url 和 reg 正则表达式匹配规则,主要是2种方法种objURL种‘o’ 的大小写问题,
切换第二种:将第一种方法url 注销 打开第二种,同时打开 第二种reg正则表达式部分的reg 注销第一种。
切换第一种:和上面相反
正则化部分:
reg :=regexp.MustCompile(`\"objURL\":\"(.*?)\"\,`)
result := reg.FindAllStringSubmatch(body, -1)
fmt.Println()
for _,data := range result{
fmt.Println(data[0])
fmt.Println(data[1])
url := strings.Replace(data[1] ,`\` , "" , -1)
if i >= downloadNumber {
return
}
download(url)
}MustCompile函数返回的是正则化匹配规则 和 FindAllStringSubmatch是返回 参数中所有匹配字符串,并且返回(.*?) 中的值,并且把匹配的整个字符串 和 括号里匹配的字符串 2个值作为一个数组,存放在result中以[][]string返回。如下:每个匹配的字符串返回2个值,因此取第二个,data[1]就是图片的url。 url := strings.Replace(data[1] ,`\` , "" , -1) 是防止获得的http中的 为了转义字符,如"http:\/\/baidu", 将“\"去掉,成为正常的 http:// ,当然不一定会出现这种情况,加着不碍事。
"objURL":"http://n.sinaimg.cn/ent/transform/150/w630h1120/20190314/6OHk-hufnxfn1652478.jpg",
http://n.sinaimg.cn/ent/transform/150/w630h1120/20190314/6OHk-hufnxfn1652478.jpg
"objURL":"http://cms-bucket.ws.126.net/2019/03/14/f8abcdc31b424a67815ba56c60fdc10f.jpg",
http://cms-bucket.ws.126.net/2019/03/14/f8abcdc31b424a67815ba56c60fdc10f.jpg
"objURL":"http://inews.gtimg.com/newsapp_bt/0/8136620832/1000",
http://inews.gtimg.com/newsapp_bt/0/8136620832/1000
"objURL":"http://inews.gtimg.com/newsapp_bt/0/8135586389/1000",
http://inews.gtimg.com/newsapp_bt/0/8135586389/1000
"objURL":"http://img.miaosong.cn/2019/03/1-xde.jpg?x-oss-process=image/resize,m_fill,h_300,w_480",
http://img.miaosong.cn/2019/03/1-xde.jpg?x-oss-process=image/resize,m_fill,h_300,w_480
"objURL":"http://p1.music.126.net/tVm1TleAL7ft_GxrKjmjnQ==/109951162848244069.jpg",
http://p1.music.126.net/tVm1TleAL7ft_GxrKjmjnQ==/109951162848244069.jpg
"objURL":"http://gss0.baidu.com/-4o3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/29381f30e924b8997556762668061d950a7bf642.jpg",
http://gss0.baidu.com/-4o3dSag_xI4khGko9WTAnF6hhy/zhidao/pic/item/29381f30e924b8997556762668061d950a7bf642.jpg
"objURL":"http://t-1.tuzhan.com/62a2d5c06d24/c-2/l/2013/08/15/04/2abbdf590cc44575aa87e4f0f036086e.jpg",
http://t-1.tuzhan.com/62a2d5c06d24/c-2/l/2013/08/15/04/2abbdf590cc44575aa87e4f0f036086e.jpg
"objURL":"http://img.12584.cn/images/3718642-20170112230345230.jpg",
http://img.12584.cn/images/3718642-20170112230345230.jpg
调用方法
在main 函数中调用:
Pa("周杰伦", 100,"周杰伦") // 表示 在百度中搜索周杰伦的图片,下载100张,存储在 周杰伦文件夹下(如果没有文件,则创建)page<100 其中就是请求100次,当然,可以更大,比如1000,最终是根据你下载的number数量来停止的。