filter的用法:
在Python内建函数中,有一个和map()函数用法类似,却可以用来过滤元素的迭代函数,这个函数就是filter()。
函数原型:filter(function,iterable)
filter返回的是一个filter对象,可以通过list()或者for循环取出内容。注意:传入的函数返回值必须是布尔类型。若是真则保留元素,假则过滤掉这元素。


从这个函数中我们可以看出 s.strip()函数可以去掉一个字符串的空 制表符 换行符。("" ' ' \n \t " ")
reduce():
reduce()函数原型是reduce(function,sequence),它的作用是用function对序列进行累计操作。它返回值可以直接输出,不想map和filter返回一个迭代对象,还得去转化。
所谓的累计操作就是第1,2个元素用function 函数运算,得到的结果再与第三个数据用function函数运算,然后得到的结果再与第四个进行运算,一次类推

注意:reduce 函数是存放再functiontools 模块中的,使用前要导入

接着“Python学习笔记06-python的核心数据类型2”我们继续:
不存在的健:if测试:
尽管我们能够通过新的健赋值来扩展字典,但是获取一个不存在的键值时仍然是一个错误.

不过我在python3.6中实验了一下,是不会报错的。获取的值是None,但是字典的长度依然是2
![]()
虽然不会报错,但是如果我们事先能够判断一个字典中健是否存在就可以避免这些操作:那就是先进行测试,用in关系表达式即可查询字典中的健是否存在


注意:出上面说的in + if来判断的方法之外,我们可以使用get方法来获取。

get方法如果不指定第二个参数,当key值不存在时,返回None,反之则返回设定的第二个参数值。
- 元组
元组对象(tuple)基本上就像一个不可以改变的列表。不过也是序列的一种,但是它具有不可改变行。可以说元组是不可变的序列
在python3.0中,元组还是有两个专有的可调用方法,但它的专用方法不想列表所拥有的那么多:

T.index()函数是获取元素1的在元组中的位置
T.count()函数是获取元素4在元组中的个数。
为什么要用元组:
正因为元组的不可变性,所以我们在函数或者传递其他对象时通常都用tuple。避免传递过程中被修改。也就是说,元组提供了一种完整性的约束,这对于比我们这里所编写的更大型的层序来说是方便的。

通过上面的例子我们就知道Python中的数据类型是多么牛了,只要知道类型,我们就可以理所当然的使用其对应的操作。虽然元组不可变,但是因为第一个元素是一个列表,所以我可以使用列表的方法进行添加元素。
- 文件
文件对象是Python代码对电脑上外部文件的主要接口。要创建文件可以使用内置函数open(),传递一个文件名和一个处理模式的字符串。

该错误是你用open打开一个文件,此时调用的是w写入模式。看到的提示信息是不支持读操作,所以我们得使用w+读写模式
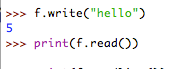
这个问题是虽然我们使用write写入一个字符串"hello",但是此时并没有真正的写入,而是还存在在内存中。此时执行read读取的为空字符串。我们需要执行a.close()以后,再使用a.read()才能读取到数据。
In [1]: data = open('1.txt', 'w+') # 以读写模式打开文件
In [2]: data.read() # 如果我们执行读操作,是没有内容的,这种模式打开之前会先清空文件
Out[2]: ''
In [3]: data.write('abcd') # 我们进行写操作,写操作是一直追加在文本末尾的
In [4]: data.read() # 读的时候也是读不到的,需要移动文件指针才能读取
Out[4]: ''
In [5]: data.seek(0) # 把文件指针移到最前面
In [6]: data.read() # 再读取就有了
Out[6]: 'abcd'