1、偏差与方差
偏差:预测值的期望与真实值之间的差距,偏差越大,越偏离真实数据集。
方差:预测值的变化范围,离散程度,方差越大,预测结果数据的分布越散。
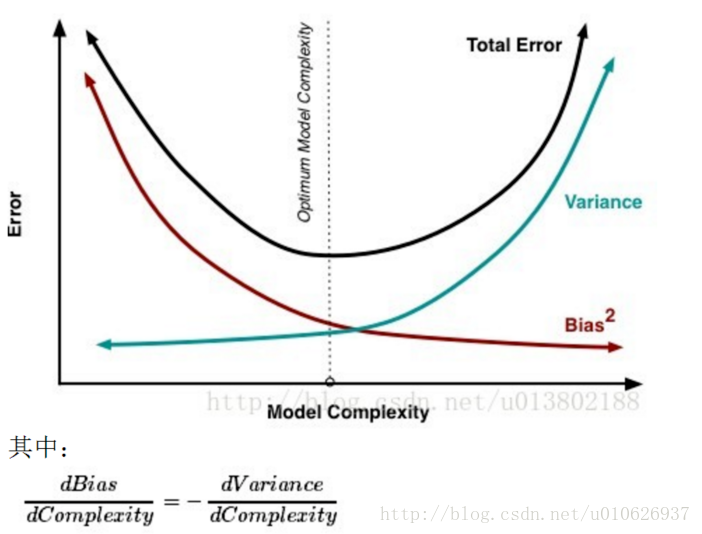
- 获得更多的训练实例——解决高方差
- 增加正则化程度λ————解决高方差
- 减少特征数量————解决高方差
- 增加特征数量————解决高偏差
- 增加多项式特征————解决高偏差
- 减少正则化程度λ—————解决高偏差
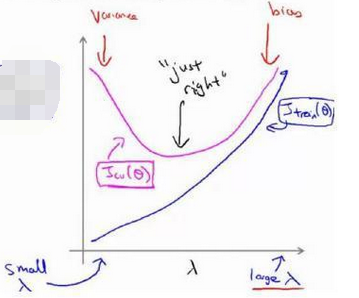
2、过度拟合和正则化
正则化是一种非常实用的减少方差的方法,正则化会出现偏差方差权衡问题,偏差可能会略有增加,但如果网络足够大的话,增幅通常不会太大。

随着 λ 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
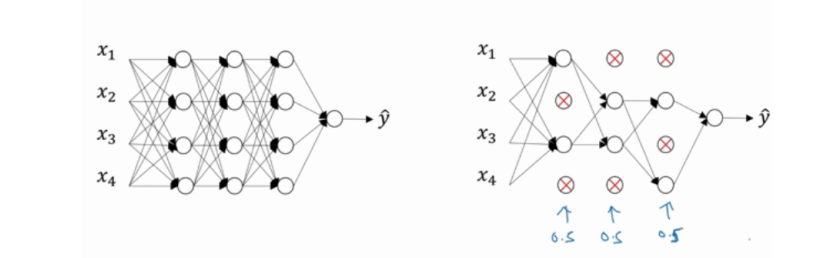
- 弃权降低过拟合(dropout)
dropout 会遍历网络的每一层,并概率性地设置消除神经网络中的节点,假设每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是 0.5;设置完节点概率,我们会消除一些节点,然后删掉从该节点进出的连线,最后得到一个节点更少、规模更小的网络,然后用bcakprop 方法进行训练,这是网络节点精简后的一个版本。
- early stopping :是提早停止训练神经网络,一旦校验数据集上分类准确率已经饱和,就停止训练
3、mini batch

在使用梯度下降法训练神经网络时,C是在整个训练样本的代价函数,当样本数量很大时,∂C/∂ω计算代价很大,因为我们需要在整个数据集上的每个样本上计算。在实践中,我们可以从数据集中随机采取少量样本,然后计算这些样本上的平均值,用来估计整体样本的值。
假设训练集样本个数为n,随机采样个数为m。
1.使用整个训练集的优化算法成为批量(batch)或者确定性(deterministic)梯度算法。(m=n)
2.每次使用单个样本的优化算法被成为随机(stochastic)或者在线(online)算法。(m=1)
3.大多数用于深度学习的方法介于以上两者之间,使用一个以上而且又不是全部的训练样本,传统上,这些会被称为小批量(minibatch)或小批量随机(minibatch stochastic)方法,现在通常简单将他们成为随机(stochastic)算法。(1<m<n)
一般选为2的幂数,16,32,64,128,256等。
#将训练集数据打乱,然后将它分成多个适当大小的小批量数据 random.shuffle(training_data) mini_batches = [training_data[k:k+mini_batch_size] for k in range(0,n,mini_batch_size)]
4、超参数调试
- 指数加权

梯度下降法:通过优化成本函数J,不停的更新w和b的值,让函数移动到最下面的哪个红色的点,也就是全局最优解。可以发现纵轴上下波动的太大导致我们在横轴上的移动速度不是很快,需要增加迭代次数或者调大学习率来达到最优解的目的,但是调大学习率会导致每一步迭代的步长过大,摆动过大,误差较大。,出现指数加权:
- 动量
对梯度下降算法进行一些优化,利用Momentum梯度下降法可以在纵向减小摆动的幅度在横向上加快训练的步长,基本思想:计算梯度的指数加权平均数并利用该梯度更新你的权重

其中β就是加权。这也是我们的超参数之一。一般设置为0.9。
- RMSprop
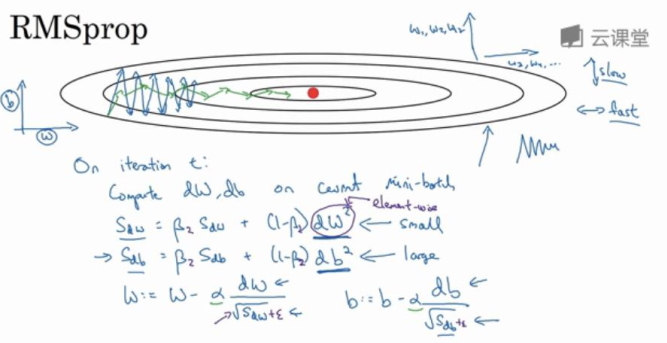
接着RMSprop会这样更新参数值
w = w - α / sqrt( Sdw)
b = b - α / sqrt( Sdb)
主要目的是为了减缓参数下降时的摆动,并允许使用一个更大的学习率。
- Adam(Adapitve Moment Estimation):通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
Adam算法的提出者描述其为两种随机梯度下降扩展式的优点集合:
- 适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
- 均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点。Adam 不仅如 RMSProp 算法那样基于一阶矩均值计算适应性参数学习率,它同时还充分利用了梯度的二阶矩均值(即有偏方差/uncentered variance)。具体来说,算法计算了梯度的指数移动均值(exponential moving average),超参数 beta1 和 beta2 控制了这些移动均值的衰减率
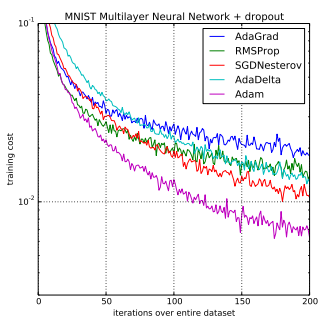
Adam的参数配置:
- alpha:同样也称为学习率或步长因子,它控制了权重的更新比率(如 0.001)。较大的值(如 0.3)在学习率更新前会有更快的初始学习,而较小的值(如 1.0E-5)会令训练收敛到更好的性能。
- beta1:一阶矩估计的指数衰减率(如 0.9)。
- beta2:二阶矩估计的指数衰减率(如 0.999)。该超参数在稀疏梯度(如在 NLP 或计算机视觉任务中)中应该设置为接近 1 的数。
- epsilon:该参数是非常小的数,其为了防止在实现中除以零(如 10E-8)。
测试机器学习问题比较好的默认参数设定为:alpha=0.001、beta1=0.9、beta2=0.999 和 epsilon=10E−8。
TensorFlow:learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08.