Dropout理论与实现
一、前言
深度学习中为了防止过拟合有很多方法,如正则化、数据增强、Dropout、BatchNorm等等,其中Dropout是一种比较经典的算法,从2012年提出到现在依旧有着重要地位,经典就是经典。
对于Dropout,从开始学习深度学习就只知道它可以有效防止过拟合,对于为什么它可以一直模模糊糊,只知道在遇到问题的时候就慌慌忙忙地采用包括其在内的各种办法,但是却不知所以然,因此虽然是比较老的算法了,但是还是有必要理解清楚。网上有着很多关于Dropout的博客,还是有必要自己去理解并笔记的必要,毕竟如人饮水,冷暖自知……
二、理论
Dropout在2012的论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》和《Improving neural networks by preventing co-adaptation of feature detectors》有详细地讨论,现在对其做简单推导。
1、问题
如果一个较大的神经网络在很小的数据集上直接训练,很容易过拟合(在训练集表现优异,但是在测试集上表现很差),模型的泛化能力很差。通常可以通过搜集更多的样本,增大数据集量级来解决(毕竟深度学习是吃数据集的算法),然而现实中很那搜集到那么多的样本,另外到底数据集要大到什么程度有时候也不知道。
2、Dropout的提出
Hiton在《Improving neural networks by preventing co-adaptation of feature detectors》中提到造成过拟合的原因:由于大的神经网络的神经元之间有着复杂的共适应性(co- adaptation), co-adaptation的意思是每个神经元学到的特征,必须结合其它的特定神经元作为上下文,才能提供对训练的帮助。而Dropout的提出则是为了削弱这种复杂的共适应性,也可以理解为削弱神经元之间的依赖关系。
3、Dropout具体实现(How,具体如何做的呢?)

图 1
Dropout的思路,按照一定的概率随机丢弃一部分神经元(如图1所示),这样每次都会有一种新的组合,假设有某一层有N个神经元,就有2的N次方个组合(子网络),最后子网络的输出均值就是最终的结果,讲道理应该这样。但是如果同时训练这么子网络代价太大,而且测试时又要组合多个网络的输出结果,不可行。
Dropout的做法比较巧,在一个网络中就实现了。训练阶段在每个mini-batch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参与更新。而测试阶段则又让所有神经元都参与计算,那么究竟如何实现的呢,总结下来就是下面的公式:
标准的神经网络计算公式(学了BP神经网络就比较熟悉,这是其中一层的神经元计算公式):
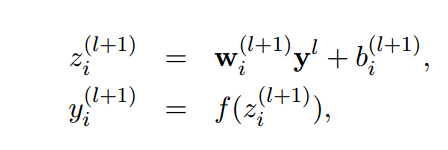
f是激活函数。Dropout是这么干的,

r是依伯努利概率分布(0-1分布)随机产生的mask向量,向量元素取值0或1,取1的概率为P,取0的概率为1-P ,向量维度与某一层的输入神经元维度一致。这就比较明显了,r向量与神经元对应元素相乘,r中元素为1的被保留,为0的则置0,那么只有被保留的神经元对应的参数得到训练(强迫神经元和其他随机挑选出来的神经元共同工作,减弱了神经元节点间的联合适应性)。
训练的时候是这样操作的,很好理解,要知道测试的时候我们没有丢弃的操作,所有神经元都参与计算,为什么就一步到位了呢?
论文《Dropout: A Simple Way to Prevent Neural Networks fromOver-fitting》 截图:

论文中说在测试阶段通过一种近似逼近的方法完成,即在测试阶段与Dropout层神经元对应参数W乘以该神经元被保留下来的概率P(P=1-Dropout ratio),因为每个神经元被保留下来的概率为P,那么对应参数scale-down,即乘上概率P。我们知道测试阶段前想过程要尽可能和要和训练阶段基本一致,所以,为了使得dropout layer 下一层的输入和训练时具有相同的“意义”和“数量级”,我们要对测试时的dropout layer的输出(即下层的输入)做 rescale: 乘以一个P,表示最后的sum中只有这么大的概率,或者这么多的部分被保留,这个是经验意义上的等价,那么数学意义呢?怎么和平均意义等价呢?可不可以这样解释:
如果按照之前的笨办法, Dropout层中每个神经元被保留的概率服从伯努利分布,在N(N趋于无穷大)次训练中,假设某个神经元在这被保留下来的此数目为n,那么
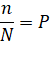
需要注意的是测试阶段所有神经元都会参与计算(不丢弃),不同的是训练时需要按概率(1-P)丢弃的神经元对应参数要乘以P.我们知道训练阶段每个minibatch都会丢弃N(1-P)的神经元,只留下PN的神经元。来看一个公式:
测试阶段没有Dropout,我们希望一次完成计算:
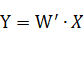
按照论文说法,测试阶段有
![]()
那么训练如果直接训练![]() '就可以直接在测试阶段权值乘参数而不需要额外的乘以保留概率
'就可以直接在测试阶段权值乘参数而不需要额外的乘以保留概率![]() ,又
,又

则在训练阶段Dropout层做通过乘scale的操作等价地训练![]() ,训练阶段公式
,训练阶段公式

其中X是经过Dropout之后的X,即按概率P保留部分神经元值,丢弃部分(1-P)置零,这样的话训练阶段就等价的完成了对W'的训练,测试阶段不丢弃神经元直接运下面的式子逼近平均化结果

很多深度学习框架的源码都是按照这个思路实现的。算法流程总结如下:
1)在训练阶段,每个mini-batch中,按照伯努利概率分布随机的丢弃一部分神经元(即神经元置零)。用一个mask向量与该层神经元对应元素相乘,mask向量维度与输入神经一致,元素为0或1。
2)然后对神经元rescale操作,即每个神经元除以保留概率P,也即乘上1/P。
3)反向传播只对保留下来的神经元对应参数进行更新。
4)测试阶段,Dropout层不对神经元进行丢弃,保留所有神经元直接进行前向过程。
三、实现
1、Caffe实现源码
Caffe对Dropout实现对应于dropout_layer的实现,详细的实现代码在dropout_layer.hpp、dropout_layer.cpp和dropout_layer.cu中。dropout_layer.cpp的cpp写了具体初始化与实现流程。
threshold即为Dropout ratio(被丢弃的概率),因此scale就是
1.0/(1.0-threshold)。

Mask向量维度与输入该层的神经元向量一样。
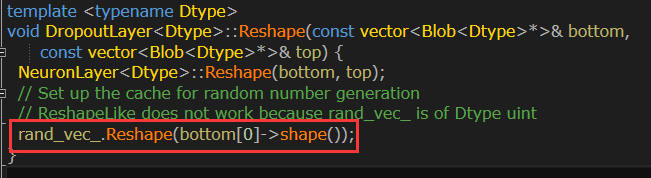
训练阶段,按伯努利分布产生mask向量,其中每一个元素等于1 的概率为1.0-threshold,即被保留的概率。然后对应元素相乘在乘上一个scale。测试阶段不用做任何操作,直接输出与输入一样,不丢弃。

2、python实现
python实现就更简单了,就几行搞定。
#!encoding=utf-8
import numpy as np
def dropout(x, drop_out_ratio,type="train"):
if drop_out_ratio < 0. or drop_out_ratio>= 1: # drop_out_ratio是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1[.')
if type=="train":
scale = 1. / (1. - drop_out_ratio)
mask_vec = np.random.binomial(n=1, p=1. - drop_out_ratio,size=x.shape) # 即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print mask_vec
x *= mask_vec # 0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0
x*=scale #再乘上scale系数
print x
return x
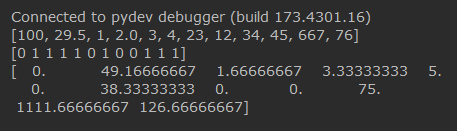
x=[100,29.5,1,2.0,3,4,23,12,34,45,667,76]
dratio=0.4
xnp=np.array(x)
print x
dropout(xnp,dratio,"train")
输出:
参考博客:
1、https://blog.csdn.net/hjimce/article/details/50413257
2、https://blog.csdn.net/u012702874/article/details/45030991
3、《Improving neural networks by preventing co-adaptation of feature detectors》
4、《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》