范数、稀疏与过拟合合集(1)范数的定义与常用范数介绍
范数、稀疏与过拟合合集(2)有监督模型下的过拟合与正则化加入后缓解过拟合的原理
范数、稀疏与过拟合合集(3)范数与稀疏化的原理、L0L1L2范数的比较以及数学分析
范数、稀疏与过拟合合集(4)L2范数对condition number较差情况的缓解
范数、稀疏与过拟合合集(5)Dropout原理,操作实现,为什么可以缓解过拟合,使用中的技巧
1、背景介绍:分布式特征表达
分布式表征(Distributed Representation),是人工神经网络研究的一个核心思想。简单来说,就是当我们表达一个概念时,神经元和概念之间不是一对一对应映射(map)存储的,它们之间的关系是多对多。具体而言,就是一个概念可以用多个神经元共同定义表达,同时一个神经元也可以参与多个不同概念的表达,只不过所占的权重不同罢了。
举例,对于“小红汽车”这个概念,如果用分布式特征地表达,那么就可能是一个神经元代表大小(形状:小),一个神经元代表颜色(颜色:红),还有一个神经元代表车的类别(类别:汽车)。只有当这三个神经元同时被激活时,就可以比较准确地描述我们要表达的物体。
分布式表征表示有很多优点,其中一点是当部分神经元发生故障时,信息的表达不会出现覆灭性的破坏。比如,我们常在影视作品中看到这样的场景,仇人相见分外眼红,一人(A)发狠地说,“你化成灰,我都认识你(B)!”这里是说,当事人B外表变了很多(对于识别人A来说,B在其大脑中的信息存储是残缺的),但没有关系,只要B的部分核心特征还在,那A还是能够把B认得清清楚楚、真真切切!
利用神经网络的分布式特征表达**(只要能保留核心特征)**,既可以实现成功完成任务(例如成功识别图片为猫),还可以用来阻止过拟合的发生,分布式特征表达可称为Dropout的来源。
2、Overfitting举例
Overfitting 也被称为过度学习,过度拟合。 它是机器学习中常见的问题。 举个Classification(分类)的例子。
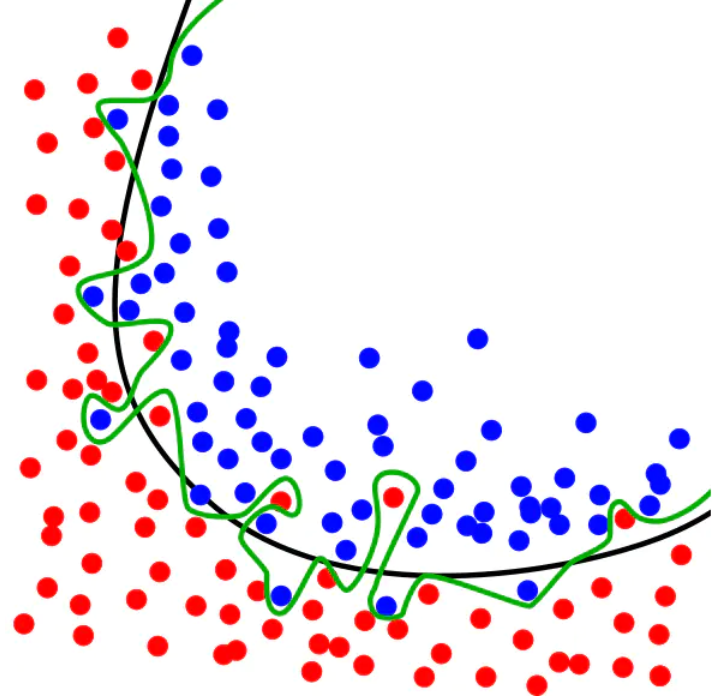
图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差。
3、对过拟合的解决方法
方法一:
增加数据量, 大部分过拟合产生的原因是因为数据量太少了。如果我们有成千上万的数据, 更高维的、更加符合所有数据的规律会被发现,绿色的也会慢慢被拉直, 变得没那么扭曲 。
方法二:
运用正则化,L1, L2 regularization 等等。 前几篇blog中有叙述。
方法三:
专门用在神经网络的正规化的方法, 叫作dropout。在训练的时候,我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”。每次都用一个不完整的神经网络训练。
4、Dropout
4.1 相关论文
Srivastava等大牛在2014年的论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》提出了Dropout正则化。
4.2 Dropout的效果:
网络对某个神经元的权重变化更不敏感,以至于达到防止参数过分依赖训练数据的目的,增加参数对数据集的泛化能力。减少过拟合,增加泛化能力。
4.3 Dropout实现操作说明
Dropout的意思是:每次训练时随机忽略一部分神经元,这些神经元dropped-out了。换句话讲,这些神经元在正向传播时对下游的启动影响被忽略,反向传播时也不会更新权重。
神经网络的所谓“学习”是指,让各个神经元的权重符合需要的特性。不同的神经元组合后可以分辨数据的某个特征。每个神经元的邻居会依赖邻居的行为组成的特征,如果过度依赖,就会造成过拟合。
如果一次训练中随机拿走一部分神经元,那么剩下的神经元就需要补上消失神经元的功能。
到第二次再随机忽略另一些, 变成另一个不完整的神经网络。
整个网络变成很多独立网络(对同一问题的不同解决方法)的合集。
有了这些随机 drop 掉的规则,我们可以想象其实每次训练的时候,我们都让每一次预测结果都不会依赖于其中某部分特定的神经元。像 L 1 L_1 L1范数, L 2 L_2 L2范数正则化一样,过度依赖的 W W W,也就是训练参数的数值会很大, L 1 L_1 L1范数、 L 2 L_2 L2范数会惩罚这些大的 参数。Dropout 的做法是从根本上让神经网络没机会过度依赖。
假设我们要训练这样一个神经网络
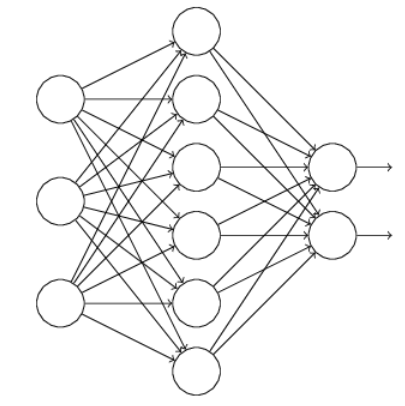
输入是 x x x输出是 y y y,正常的流程是:我们首先把 x x x通过网络前向传播,然后与 y y y进行计算出误差,后把误差反向传播以决定 如何更新参数让网络进行学习。使用dropout之后过程变成:
首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(下图中虚线为部分临时被删除的神经元)
然后把输入 x x x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后就按照随机梯度下降法更新,只更新没有被删除的神经元中对应的参数 ( w , b ) (w,b) (w,b)。
然后继续重复这一过程:
恢复被删掉的神经元(此时 被删除的神经元 保持原样(即为更新前的数值),而没有被删除的神经元已经有所更新)
从隐藏神经元的参数集合中随机圈定的一个一定大小的子集(这个子集的大小是根据参数自己设置的)临时删除掉(备份被删除神经元的参数,他们只是不参加本次训练)。
对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数 ( w , b ) (w,b) (w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果
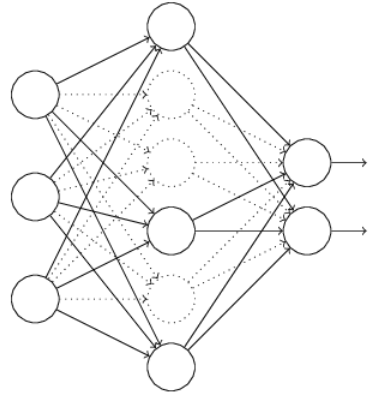
5、Dropout为什么可以解决过拟合呢?
角度1:数据扩充层面
对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation。
对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,也就相当于说对于后面的层来说,多训练了这种情况下的数据。这样每一次dropout其实都相当于增加了样本。
角度2:模型层面
在较大程度上减小了网络的大小:在这个“残缺”的网络中,让神经网络学习数据中的局部特征(即部分分布式特征),但这些特征也足以进行输出正确的结果。相当于说减少了参数试图获得一样的性能。减少了过拟合的可能。
角度3:取平均的思路
先回到正常的模型(没有dropout),我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如 3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。
Dropout思想类似于集成学习中的Bagging思想:由学习阶段可知,每一次训练都会按一定的比例来随机保留部分神经元,这意味着每次迭代过程中,会随机删除一些神经元,也就相当于说训练多个"残缺"的神经网络中,并且每次都是进行随机的参数选择(这里随机参数选择也就意味着随机选择表达的特征)。整个dropout过程就相当于对很多个不同的神经网络取平均。
这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些互为“反向”的拟合相互抵消,这样在整体上就会减少过拟合。
角度4:减少共适应关系
减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高)
角度5:优胜劣汰,进化适应
Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。 当地球都是海洋时,人类是不是也进化出了再海里生活的能力呢?
6、使用Dropout正则化的技巧
原论文对很多标准机器学习问题做出了比较,并提出了下列建议:
- Dropout概率不要太高,从20%开始,试到50%。太低的概率效果不好,太高有可能欠拟合。
- 网络要大。更大的网络学习到不同方法的几率更大。
- 每层都做Dropout,包括输入层。效果更好。
- 学习率(带衰减的)和动量要大。直接对学习率乘10或100,动量设到0。9或0。99。
- 限制每层的权重。学习率增大会造成权重增大,把每层的模限制到4或5的效果更好。
LAST、参考文献
drop解决过拟合的情况 - 。Tang - 博客园
Neural networks and deep learning
Deep learning:四十一(Dropout简单理解)
深度学习:Dropout解决过拟合问题_Vermont_的博客-CSDN博客
drop解决过拟合的情况_weixin_30839881的博客-CSDN博客
drop out为什么能够防止过拟合 - simple_wxl - 博客园
Dropout如何防止过拟合 - 知乎
过拟合(Overfitting) 与 Dropout