Mini-batch SGD的步骤:
1.Sample a batch of data
2.Forward prop it through the graph,get loss
3.backprop to calculate the gradient
4. updata the parameters using the gradient
The initialization of weights is important. 如果 初始化过小, 经过激活后网络中权值的update就会
趋于0;如果过大,就可能出现梯度爆炸;尝试xavier initialization
main loop:
while True: data_batch = dataset.sample_data_batch() loss = network.forward(data_batch) loss = network.backward() x += -learning_rate * dx
不同的参数更新方案有不同的优化途径和优化速度,SGD方法是所有方法中最慢的。
The problems of SGD and why SGD is slow?
假设一个损失函数空间,损失函数的垂直方向非常陡峭,水平方向非常shallow

水平方向上的梯度非常小,垂直方向上梯度很大。
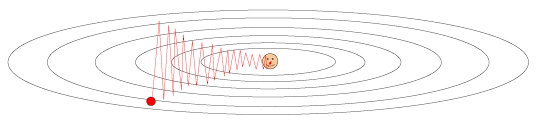
更新方式如上,补救的一种方式是动量更新:
x += -learning_rate * dx #改为 v = mu*v - learning_rate * dx # v => integrate velocity x += v
SGD根据梯度矫正W,而momentum不是通过计算到的梯度直接update。增加变量v,将其定义为速度,我们的增值速度变量V,而不是过去建立在的信用指数上,这就是整合的位置,mu是一个超参数。
可以理解为一个球滚动着接近中间这个笑脸,在这种情况下梯度可以视为一种动力,这种动力相当于加速度(dx),这里的mu倍(通常取0.5-0.99)的v,可以视作一个摩擦力,他每一次作用都有轻微的减速,直观的说如果公式的mu倍v不在,那么小球将会永远不会停下来,会在平面上滚动,不会有能力的损失,损失函数将会很难最小化。
因此动量更新是采取物理化解释,随着时间的推移逐渐放慢了速度,因为你最终确定了速度,特别是在比较浅的方向上,他们的方向一致,动量更新将会建立在这个方向上的速度矢量上,最终会加快这个比较浅的方向上的速度;但在陡峭的空间中,球开始做圆周运动,然后你的力的方向总是朝着中心前进的过程中,并利用阻尼和某种震荡到达中心,在陡峭的方向上削弱这些震荡,而在shallow的方向上激励此过程,这就是为什么结果比较收敛的原因,
如何初始化v?
通常初始化为0,因为在最开始的步骤中会构建它,得到式子。你会发现得到的梯度会以指数衰减,所以初始化为0.
特殊的动量更新 Nesterov Momentum update

原始的momentum update 是gradient step(l_r * dx) (指向损失函数减小方向)和 momentum step (v*mu)(某一确定方向上的动量)的向量和(实际step方向)
而Nesterov Momentum update 是在得到momentum step方向和未知梯度方向上,来预测结果。它想让我们使用箭头端这一点的梯度来作为代替,我们要沿着这个方向进行,为什么不直接到达这一目标呢?并计算这一点的梯度,当然你得到的结果有些不同,因为你是在损失函数中的不同位置,得到了和之前细微不同的更新结果
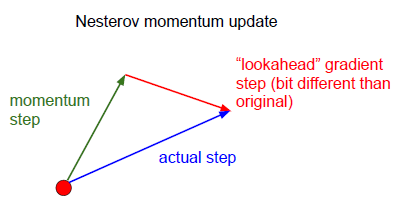
优点:对于收敛率有更好的保证。
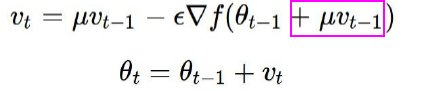
如上式所示,唯一的不同就是mu乘以Vt-1,这里计算梯度的时候选择一个和之前不同的位置,这个预测位置(look ahead position),效果很好。
Nesterov Momentum update的公式和代码实现:


扩大神经网络的规模,可以减小局部最小值得影响。
AdaGrad updata

添加一个附加变量来放缩梯度,cache由梯度的平方和构成,初始化cache为0
每个参数自适应调整的原因:参数的每一维,都有自己的学习率动态调整,垂直方向上由更大的梯度,这些梯度加到cache就会很大,减小步长。水平方向上梯度变小,则增大步长加快速度。相比垂直方向,在梯度较小的水平方向你可以有更大的学习率。
但是也有问题AdaGrad 更新步长会衰减到0,停止训练,但是我们需要网络不断的变化,保持更新的活力而不是停止。
RMSProp update
1 cache = decay_rate * cache + (1-decay_rate) * dx**2 2 x +=-learning_rate*dx/(np.sqrt(cache)+ 1e-7)
和AdaGrad区别在于不在每一维度计算平方和而是变成一个衰减函数,最后利用衰减率这个超参数(0.99),接着计算引入衰减率缓慢发生泄漏的平方和,仍然保持了在梯度较大或较小方向上,对于更新步长的补偿效应,也不会再发生停止更新情况。
AdaGrad 和RMSProp 相比停止得更早一些,在梯度大的地方减小更新速度是十分合理的;cache不再考虑很久以前的梯度值,它关于时间的表达式是最近几个梯度的函数,以衰减率为指数展开和的形式。
Adam updata
结合momentu 速度的优势和 AdaGrad 的自适应学习率的优势
#Adam
t<-iteration numbers m = beta1*m + (1-beta1)*dx v = beta2*v + (1-beta2)*(dx**2)
m/= 1-beta1**t #correct bias
v/= 1-bata2**t x += -learning_rate *m/(np.sqrt(v)+1e-7)
动量m,他是梯度的一阶矩,把它用指数和展开的形式表示。beta1 和beta2为超参数,beta1为0.9,beta2通常为0.995.
AdaGrad记录的是梯度的二阶矩,并按指数和形式表示,看起来像是带有动量的RMSprop算法,需要求动量参数,也要进行自适应的尺度变化。
Adam的理解:通过小批量的抽样处理,在forward获得很多随机值,you will get 这些带有噪声的梯度,所以相比于每一步都用各自梯度值运算,实际上利用了前面几个梯度的衰减和,这样有稳定的梯度方向,这就是动量的作用。
AdaGrad的理解:确保梯度大和梯度小的方向步长相关。
偏置矫正的理解:只在迭代次数很小的时候才会有作用,是针对m、v初始为0的补偿措施;所以刚开始你的数据可能不正确,在刚开始将m、v变大,后面不会影响m、n.
Learning Rate对update algorithem的影响
1.应该开始阶段使用高学习速率
2.之后以较低的学习速率到达损失更低的点
引入学习率的衰减,随着训练。
二阶优化方法,对于损失函数有一个更详细的近似分析:
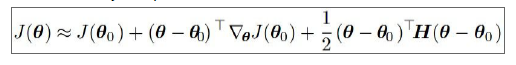
它们不仅仅估计了超参数来确定哪个方向下降得快,还通过Hessian矩阵描述了平面的弯曲程度,所以你不仅需要梯度,还需要把Hessian矩阵算出来。
牛顿法
当目标有了像Hessian近似的碗,可以通过牛顿法达到目标,采用这个方法可以直接到这个近似方案的最低点。
二阶方法的优势?
更新中没有学习速率、没有超参数,因为如果你得到损失函数的梯度,还知道这个地方的曲率,所以对这个碗进行近似计算时,知道怎么走,就能够到达近似的最低值,不需要学习率。
1. 通过二阶特性可以更快的收敛
2.Hessian矩阵的求解,你有一亿个参数,则Hessian矩阵是一亿行和一亿列的方阵,然后你想要求解逆运算,不可能发生。