1.Spark Streaming是什么
Spark Streaming用于流式数据的处理,SparkStreaming支持的数据源很多,例如Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等,数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。

2.Spark Streaming特点
1)易用
2)容错
3)易整合到Spark体系
3.Spark Streaming架构
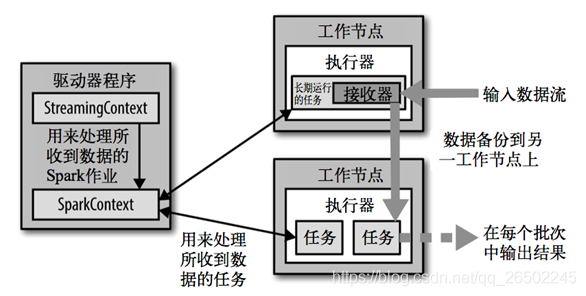
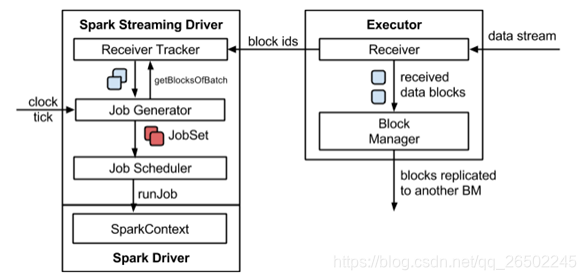
4.Spark Streaming入门案例实操
wordcount案例:使用net cat工具向9999端口不断的发送数据,通过spark Streaming读取端口数据并统计出不同单词出现的次数
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
代码:
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
object StreamWordCount{
def main(args:Array[String]):Unit={
//初始化spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WC")
//初始化SparkStreamcontext
val ssc = new StreamingContext(sparkConf,Second(5))
//通过监控端口创建Dstream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("hadoop102",9999)
//将每一行的数据做切分,形成一个个的单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射为元组
val wordAndOneStreams = wordStreams.map((_,1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印结构
wordAndCountStreams.print()
//一定要启动Spark Streaming Context
ssc.start()
ssc.awaitTermination()
}
}
启动程序并通过net Cat发送数据
nc -lk 9999
案例解析
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原理操作后的结果数据流,在内部实现上,DStream是一系列连续的RDD来表示,每个RDD含有一段时间间隔内的数据,如下图
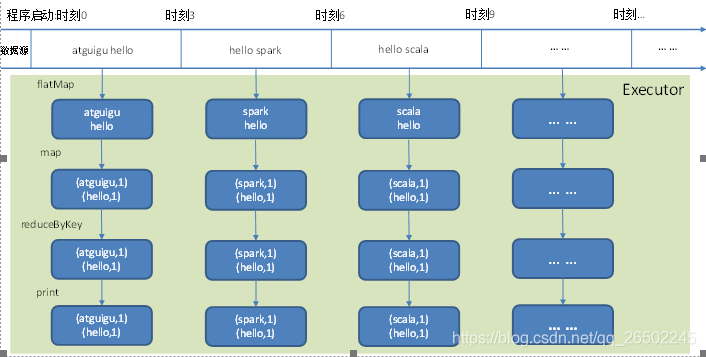
5.Dstream创建
1.RDD队列
用法及说明:测试过程中,可以使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
案例实操:
循环创建几个RDD,将RDD放入队列,通过Spark Stream创建Dstream,计算word count
编写代码:
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object RDDStream{
//1.初始化spark配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
//2.初始化SparkStreamContext
val ssc = new StreamingContext(conf,Second(5))
//3.创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//创建QueueInputStream
val inputStream = ssc.queueStream(rdddQue,oneAtATime = false)
//处理队列中的RDD数据
val mappedStream: DStream[(Int, Int)] = inputStream.map((_,1))
val reduceStream: DStream[(Int, Int)] = mappedStream.reduceByKey(_+_)
//打印结果
reduceStream.print()
//启动任务
ssc.start()
//循环创建并向RDD队列中放入RDD
for (i <- 1 to 5){
rdddQue += ssc.sparkContext.makeRDD(1 to 300,10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
结果
-------------------------------------------
Time: 1552791436000 ms
-------------------------------------------
(84,2)
(96,2)
(120,2)
(180,2)
(276,2)
(156,2)
(216,2)
(300,2)
(48,2)
(240,2)
...
-------------------------------------------
Time: 1552791440000 ms
-------------------------------------------
(84,2)
(96,2)
(120,2)
(180,2)
(276,2)
(156,2)
(216,2)
(300,2)
(48,2)
(240,2)
...
2.自定义数据源
用法及说明:需要继承Receiver,并实现onStart以及onStop方法来自定义数据源采集
案例实操:
自定义数据源,实现监控某个端口号,获取该端口号的内容
1.首先需要自定义数据源
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
//自定义数据源
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
//最初启动的时候,调用该方法,作用为:读取数据并将数据发送给spark
override def onStart(): Unit = {
new Thread("Socket Receiver") {
override def run(): Unit = {
receive()
}
}.start()
}
//读取数据并将数据发送给spark
def receive(): Unit = {
//创建一个socket
var socket: Socket = new Socket(host, port)
//定义一个变量,用来接收端口传过来的数据
var input:String = ""
//创建一个BufferReader用于读取端口传来的数据
val reader: BufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
input = reader.readLine()
//当receiver没有关闭并且输入数据不为空,则循环发送数据给Spark
while (!isStopped() && input !=null) {
store(input)
input = reader.readLine()
}
//跳出循环则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {}
}
2.使用自定义的数据源采集数据
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FileStreamTest {
def main(args: Array[String]): Unit = {
//初始化信息
val sparkConf: SparkConf = new SparkConf().setAppName("App").setMaster("local[*]")
//初始化sparkStream
val ssc: StreamingContext = new StreamingContext(sparkConf,Seconds(5))
//创建自定义的receiver的Streaming
val lineStream: ReceiverInputDStream[String] = ssc.receiverStream(new CustomerReceiver("hadoop102",9999))
//将每一行的数据切分,形成一个个的单词
val wordStream: DStream[String] = lineStream.flatMap((_.split("\t")))
//将单词映射成元组
val wordAndOneStream: DStream[(String, Int)] = wordStream.map((_,1))
//将相同的单词次数做统计
val wordCount: DStream[(String, Int)] = wordAndOneStream.reduceByKey(_+_)
//打印结果
wordCount.print()
//启动Spark StreamingContext
ssc.start()
ssc.awaitTermination()
}
}