文章目录
目录
什么是数据不平衡问题?
在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的结果。因为实际数据往往分布得很不均匀,都会存在“长尾现象”,也就是所谓的“二八原理”。
在处理机器学习等数据科学问题时,经常会碰到不均衡种类分布的情况,即在样本数据中一个或多个种类的观察值明显少于其他种类的观察值的现象。在我们更关心少数类的问题时这个现象会非常突出,例如窃电问题、银行诈骗性交易、罕见病鉴定等。在这种情况下,运用常规的机器学习算法的预测模型可能会无法准确预测。这是因为机器学习算法通常是通过减少错误来增加准确性,而不考虑种类的平衡。这篇文章讲了不同的方法来解决这个不均衡分类问题,同时说明了这些方法的好处和坏处。

数据不平衡会造成什么影响?
不平衡程度相同(即正负样本比例类似)的两个问题,解决的难易程度也可能不同,因为问题难易程度还取决于我们所拥有数据有多大。比如在预测微博互动数的问题中,虽然数据不平衡,但每个档位的数据量都很大——最少的类别也有几万个样本,这样的问题通常比较容易解决;而在癌症诊断的场景中,因为患癌症的人本来就很少,所以数据不但不平衡,样本数还非常少,这样的问题就非常棘手。综上,可以把问题根据难度从小到大排个序:大数据+分布均衡<大数据+分布不均衡<小数据+数据均衡<小数据+数据不均衡。对于需要解决的问题,拿到数据后,首先统计可用训练数据有多大,然后再观察数据分布情况。经验表明,训练数据中每个类别有5000个以上样本,数据量是足够的,正负样本差一个数量级以内是可以接受的,不太需要考虑数据不平衡问题(完全是经验,没有理论依据,仅供参考)。

如何处理数据不平衡问题?
在将数据用于建模之前,先运用重抽样技术使数据变平衡。平衡数据主要通过两种方式达到:增加少数类的频率或减少多数类的频率。通过重抽样来改变两个种类所占的比例。
1、重新采样训练集
1.1随机欠抽样

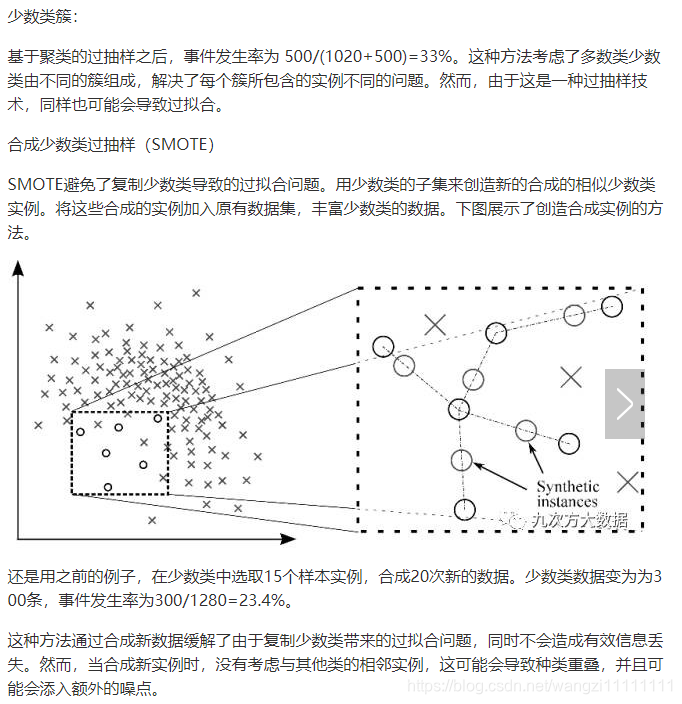
1.2.基于聚类的过采样


2.使用K-fold交叉验证
值得注意的是,使用过采样方法来解决不平衡问题时应适当地应用交叉验证。这是因为过采样会观察到罕见的样本,并根据分布函数应用自举生成新的随机数据,如果在过采样之后应用交叉验证,那么我们所做的就是将我们的模型过拟合于一个特定的人工引导结果。这就是为什么在过度采样数据之前应该始终进行交叉验证,就像实现特征选择一样。只有重复采样数据可以将随机性引入到数据集中,以确保不会出现过拟合问题。
K-fold交叉验证就是把原始数据随机分成K个部分,在这K个部分中选择一个作为测试数据,剩余的K-1个作为训练数据。交叉验证的过程实际上是将实验重复做K次,每次实验都从K个部分中选择一个不同的部分作为测试数据,剩余的数据作为训练数据进行实验,最后把得到的K个实验结果平均。
3.转化为一分类问题

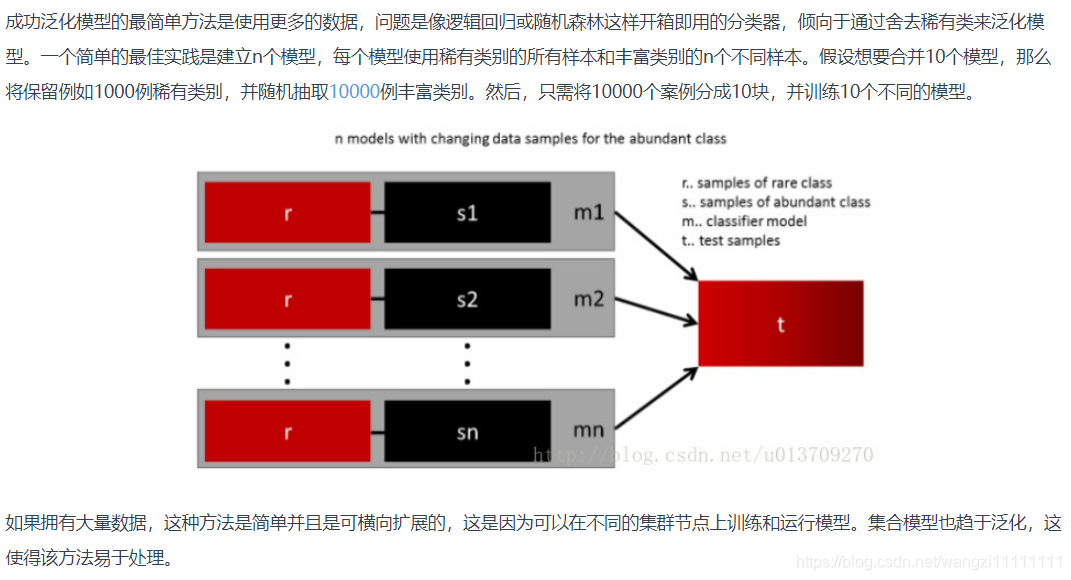
4.组合不同的重采样数据集
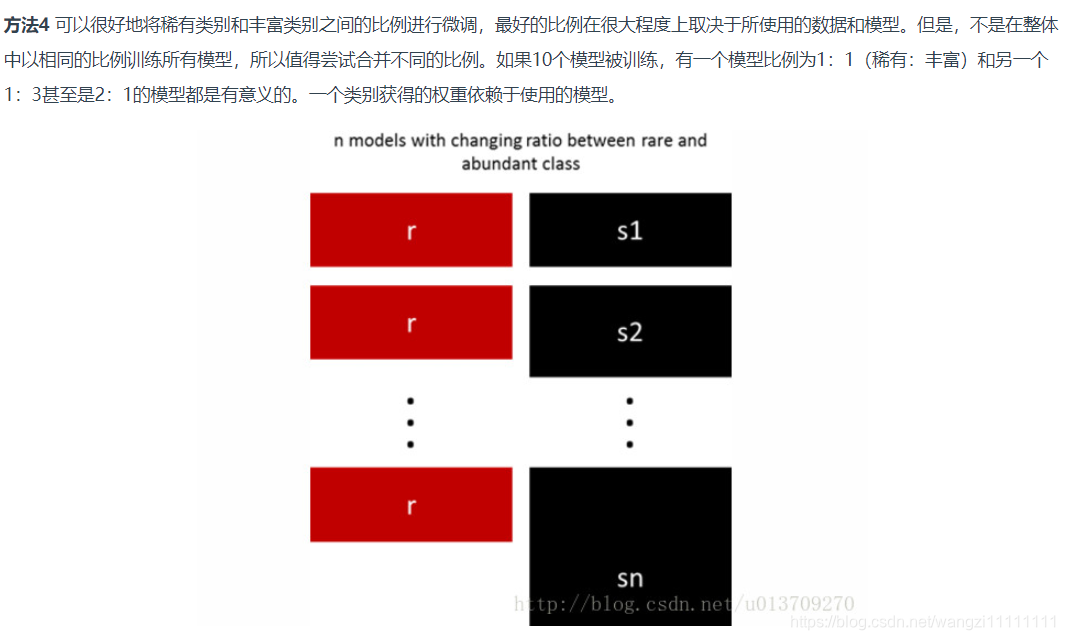
5.用不同比例重新采样
6.多模型Bagging


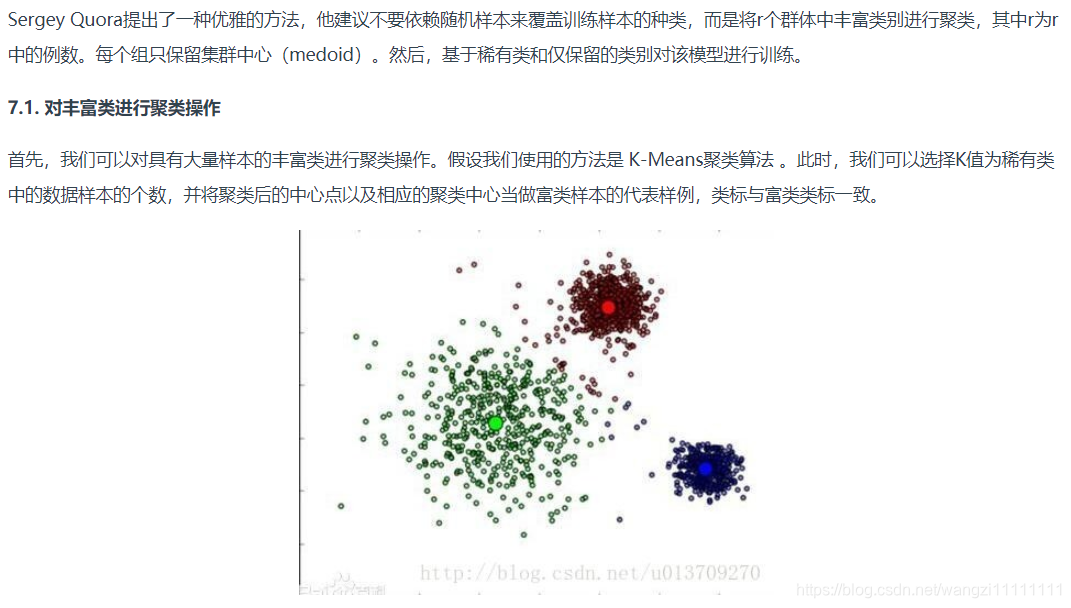
7.集群丰富类
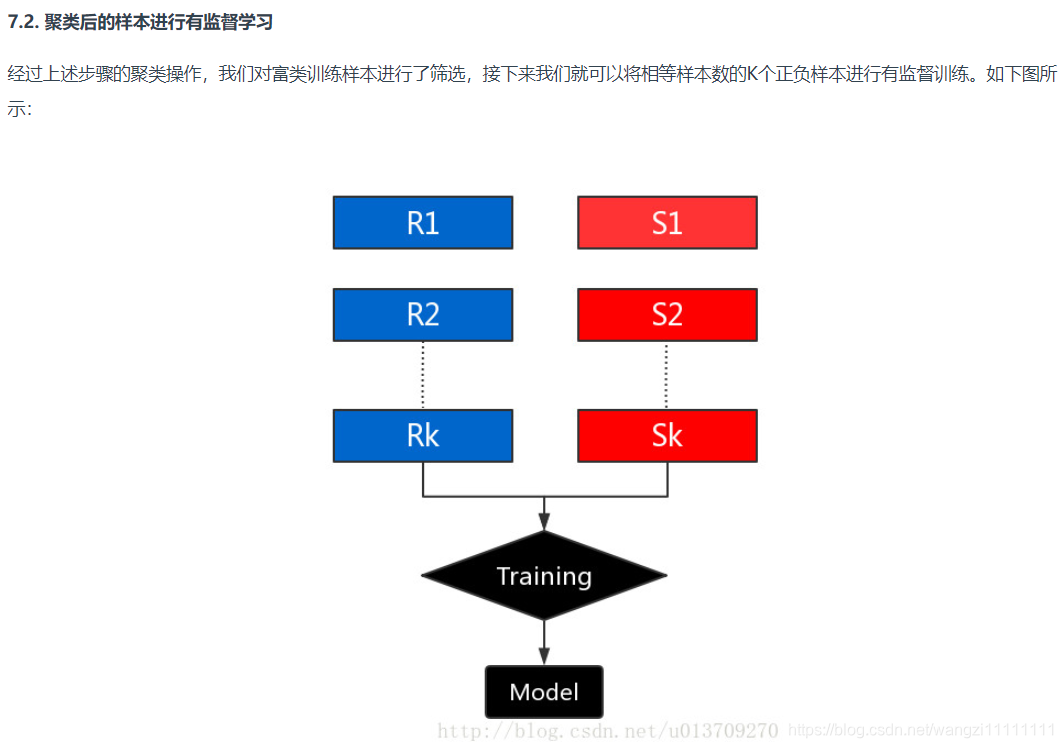
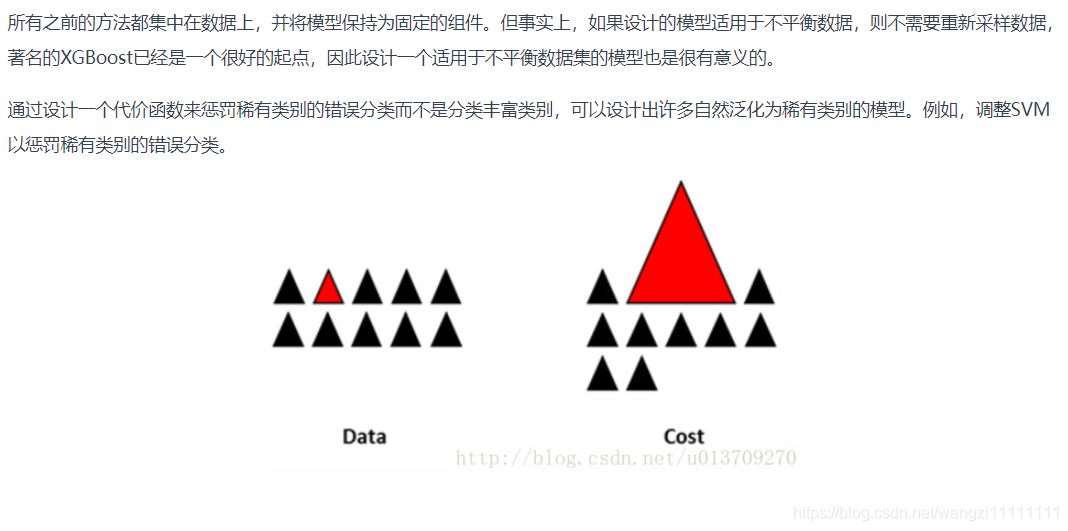
8.设计适用于不平衡数据集的模型
总结:

