类别不平衡问题指分类任务中不同类别的训练样本数目差别很大的情况。
下面介绍几种缓解类别不平衡的方法:
1、欠采样
即去除多余的样本,使得正负样本数目基本一致。
注意:(1)由于丢弃了一些样本,训练速度相对加快了。
(2)但是简单的随机丢失样本,会造成信息丢失。欠采样的代表算法是EasyEnsemble,是利用集成学习机制,将数目多的一类划分成若干个集合供不同学习器使用,这样虽然对每个学习器丢失了一部分信息,但全局上看不会丢失重要信息。
2、过采样
即增加少的一类的样本数目,使得正负样本数目基本一致。
注意:(1)由于多了一些样本,训练速度相对减慢了。
(2)但是简单的重采样会带来严重的过拟合,过采样的代表性算法是SMOTE,是通过对少的一类进行插值得到额外的样本。
3、阈值移动
阈值移动主要是用到“再缩放”的思想,以线性模型为例介绍“再缩放”。
我们把大于0.5判为正类,小于0.5判为负类,即

即令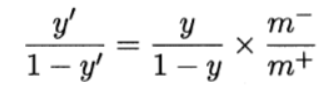 然后代入上上式。这就是“再缩放”。
然后代入上上式。这就是“再缩放”。
阈值移动方法是使用原始训练集训练好分类器,而在预测时加入再缩放的思想,用来缓解类别不平衡的方法。