=======================================================================
Machine Learning notebook
Python机器学习基础教程(introduction to Machine Learning with Python)
https://github.com/amueller/introduction_to_ml_with_python/blob/master/02-supervised-learning.ipynb
=======================================================================
集成(ensemble)是合并多个机器学习模型来构建更强大模型的方法。在机器学习文献中有许多模型都属于这一类,但已证明有两种集成模型对大量分类和回归的数据集都是有效的,二者都以决策树为基础,分别是随机森林(random forest)和梯度提升决策树(gradient boosted decision tree)。
1、随机森林
决策树的一个主要缺点在于经常对训练数据过拟合。随机森林是解决这个问题的一种方法。随机森林本质上是许多决策树的集合,其中每棵树都和其它树略有不同。
随机森林背后的思想是,每棵树的预测可能相对较好,但可能对部分数据过拟合。如果构造很多树,并且每棵树的预测都很好,但都以不同的方式过拟合,那么我们可以对这些树的结果取平均值来降低过拟合。既能减少过拟合又能保持树的预测能力,这可以在数学上严格证明。
为了实现这一策略,我们需要构造许多决策树。每棵树都应该对目标值做出可以接受的预测,还应该与其他树不同。随机森林的名字来自于将随机性添加到树的构造过程中,以确保每棵树都个不相同。随机森林中树的随机化方法有两种:
一种是通过选择用于构造树的数据点。
另一种是通过选择每次划分测试的特征。
构造随机森林。想要构造一个随机森林模型,你需要确定用于构造的树的个数(RandomForestRegressor或RandomForestClassifier的n_estimators参数)。这些树在构造时彼此完全独立,算法对每棵树进行不同的随机选择,以确保树和树之间是有区别的。想要构造一棵树,首先对每棵树进行自助采样(bootstrap sample)。也就是说,从n_samples个数据点中有放回地(即同一样本可以被多次抽取)重复随机抽取一个样本,共抽取n_samples次。这样会创建一个与原数据集大小相同的数据集,但有些数据点会缺失(大约三分之一),有些会重复。
基于这个新创建的数据集来构造决策树。但是,需要对单决策树时描述的算法稍作修改。在每个结点处,算法随机选择特征的一个子集,并对其中一个特征寻找最佳测试,而不是对每个结点都寻找最佳测试。选择的特征个数由max_features参数来控制。每个结点中特征子集的选择是相互独立的,这样树的每个结点可以使用特征的不同子集来做出决策。
由于使用了自助采样,随机森林中构造每颗决策树的数据集都略有不同。由于每个结点的特征选择,每颗树中的每次划分都是基于特征的不同子集。这两种方法共同保证随机森林中所有树的不同。
在这个过程中的一个关键参数是max_features。
如果我们设置max_features等于n_features,那么每次划分都要考虑数据集的所有特征,在特征选择的过程中没有添加随机性(不过自助采样依然存在随机性)。
如果设置max_features等于1,那么在划分时将无法选择对哪个特征进行测试,只能对随机选择的某个特征搜索不同的阈值。
因此,如果max_features较大,那么随机森林中的树将十分相似,利用最独特的特征可以轻松拟合数据。
如果max_features较小,那么随机森林中的树将会差异很大,为了很好的拟合数据,每棵树的深度都要很大。
想要利用随机森林进行预测,算法首先对森林中的每颗树进行预测。
对于回归问题,可以对这些结果取平均值作为最终预测。
对于分类问题,则用到了“软投票”(soft voting)策略。也就是说,每个算法做出“软”预测,给出每个可能的输出标签的概率。对所有树的预测概率取平均值,然后将概率最大的类别作为预测结果。
2、分析随机森林
作为随机森林的一部分,树被保存在estimator_属性中。将每棵树学到的决策边界可视化,也将它们的总预测(即整个森林做出的预测)可视化。这5棵树学到的决策边界大不相同。每棵树都犯了一些错误,因为这里画出的一些训练点实际上并没有包含在这些树的训练集中,原因在于自助采样。
随机森林比单独每一棵树的过拟合都要小,给出的决策边界也更符合直觉。在任何实际应用中,我们会用到更多棵树(通常是几百或上千),从而得到更平滑的边界。
在没有任何调节的情况下,随机森林的精度为97%,比线性模型或单颗决策树都要好。我们可以调节max_features参数,或者像单颗决策树那样进行预剪枝。但是,随机森林的默认参数通常就已经可以给出很好的结果。
在乳腺癌数据集上学到的决策树的特征重要性:
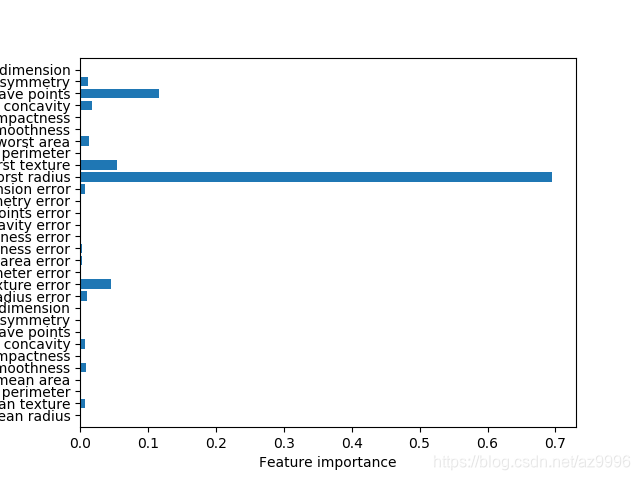
拟合乳腺癌数据集得到的随机森林特征的特征重要性:
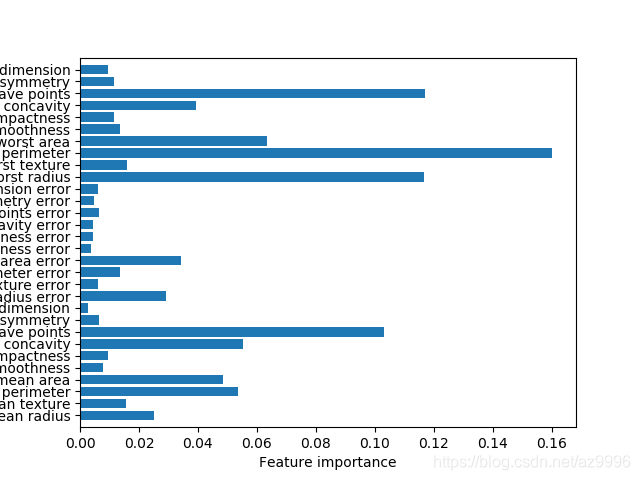
如图所见,与单颗树相比,随机森林中有更多特征的重要性不为零。由于构造随机森林过程中的随机性,算法需要考虑多种可能的解释,结果就是随机森林比单颗树更能从总体把握数据的特性。
3、优点、缺点和参数
用于回归和分类的随机森林是目前应用最广泛的机器学习方法之一。这种方法非常强大,通常不需要反复调节参数就可以给出很好的结果,也不需要对数据进行缩放。
从本质上看,随机森林拥有决策树的所有优点,同时弥补了决策树的一些缺陷。仍然使用决策树的一个原因是需要决策过程的紧凑表示。基本上不可能对几十颗甚至上百颗树做出详细解释,随机森林中树的深度往往比决策树还要大(因为用到了特征子集)。因此,如果你需要可以可视化的方式向非专家总结预测过程,那么选择单颗决策树可能更好。
虽然在大型数据集上构建随机森林可能比较费时间,但在一台一台计算机的多个CPU内核上并行计算也很容易。可以使用参数n_jobs参数来调节使用的内核个数。使用更多的CPU内核,可以让速度线性增加,但设置n_jobs大于内核个数是没有用的。你可以设置n_jobs=-1来使用计算机的所有内核。
随机森林本质上是随机的,设置不同的随机状态(或者不设置random_state参数)可以彻底改变构建的模型。森林中的树越多,它对随机状态选择的鲁棒性就越好。如果你希望结果可以重现,固定random_state是很重要的。
对于维度非常高的稀疏矩阵(比如文本数据),随机森林的表现往往不是很好。对于这种数据,使用线性模型可能更合适。即使非常大的数据集,随机森林的表现通常也很好,训练过程很容易并行在功能强大的计算机的多个CPU内核上。不过,随机森林需要更大的内存,训练和预测的速度也比线性模型要慢。对一个应用来说,如果时间和内存很重要的话,那么换用线性模型可能更为明智。
需要调节的重要参数有n_estimators和max_features,可能还包括预剪枝选项(如max_depth)。n_estimators总是越大越好。对更多的树取平均可以降低过拟合,从而得到鲁棒性更好的集成。不过收益是递减的,而且树越多需要的内存也越多,训练时间也越长。常用的经验法则就是“在你的时间/内存允许的情况下尽量多”。
max_features决定每棵树的随机性大小,较小的max_features可以降低过拟合。一般来说,好的经验就是使用默认值:对于分类,默认值是max_features=sqrt(n_features);对于回归,默认值是max_features=n_features。增大max_features或max_leaf_nodes有时也可以提高性能。它还可以大大降低用于训练和预测的时间和空间要求。