一,快速排序的思想
1,在一个无序的数组里随机找一个作为基准值。
2,然后让数组里的每一个数字和基准值比较,比基准值大的放在基准值右边,比基准值小的,放在基准值左边。
3,递归调用这个函数,使得整个数组有序。
二,快速排序的实现方法
方法一:交换法
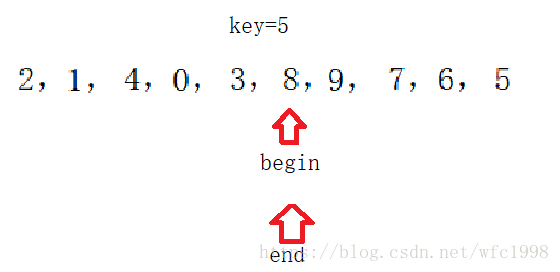
- 取最后一个数据为基准值,begin标记数组第一个数据,end标记数组最后一个数据
- begin++向后走,找到比基准值大的数停下来,end–向前走,找到比基准值小的数停下来,
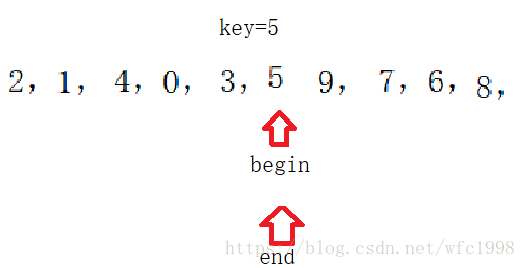
- 然后交换两个标记位置的数据,



-
继续此过程直到两个标记相遇,把标记点位置的数据和最后一个数据交换
-
现在使得基准值左边的数字都比基准值小,右边的数字都比基准值大,然后递归调用函数,根据传的参数不同,进行不同区间的排序,不断缩小区间,知道区间里面只有一个数据为止,排序结束
代码实现:
//交换函数
void Swap(int* left, int* right)
{
int temp = 0;
assert(left && right);
temp = *left;
*left = *right;
*right = temp;
}
int DealArray01(int* array, int left, int right)
{
int begin = left;
int end = right - 1;
int key = array[right - 1];
while (begin < end)
{
while (begin < end && array[begin] <= key)
begin++;
while (end > begin && array[end] >= key)
end--;
if (begin != end)
Swap(&array[begin], &array[end]);
}
if (begin != right)
Swap(&array[begin], &array[right - 1]);
return begin;
}
//快速排序
void QuickSort(int* array, int left, int right)
{
if (right - left > 1)
{
int ret = DealArray01(array, left, right);//找比基准值大的和小的交换
QuickSort(array, left, ret);//递归调用,排左边区间
QuickSort(array, ret + 1, right);/递归调用,左边的排完了,排右边区间
}
}
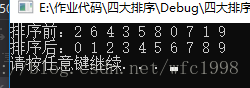
代码运行结果:
方法二:挖坑法
- 数组最后一个数据为基准值,并用key保存,begin标记数组第一个数据,end标记数组最后一个数据,
- begin++向后走,找到比基准值大的数,把end位置的数据覆盖
- end–向前走找到比基准值小的数,然后把begin位置的数覆盖
- 一直重复上两步,直到两个标记相遇,
- 相遇之后把key的值赋给标记点。
- 现在使得基准值左边的数字都比基准值小,基准值右边的数字都比基准值大,然后递归调用,根据传参不同,排序不同的区间,直到区间里只有一个数据时,排序结束。





代码实现
void QuickSort(int* array, int left, int right)
{
if (right - left > 1)
{
int ret = DealArray02(array, left, right);//挖坑,添坑,
QuickSort(array, left, ret);
QuickSort(array, ret + 1, right);
}
}
int DealArray02(int* array, int left, int right)//挖坑添坑
{
int begin = left;
int end = right - 1;
int key = array[right - 1];
while (begin < end)
{
while (begin < end && array[begin] <= key)
begin++;
array[end] = array[begin];
while (end > begin && array[end] >= key)
end--;
if (begin != end)
array[begin] = array[end];
begin++;
}
array[end] = key;
return end;
}
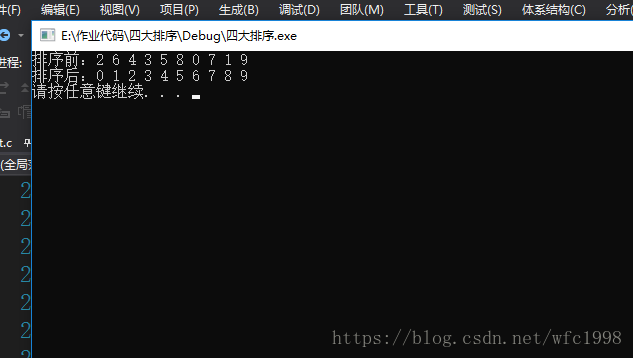
运行结果:
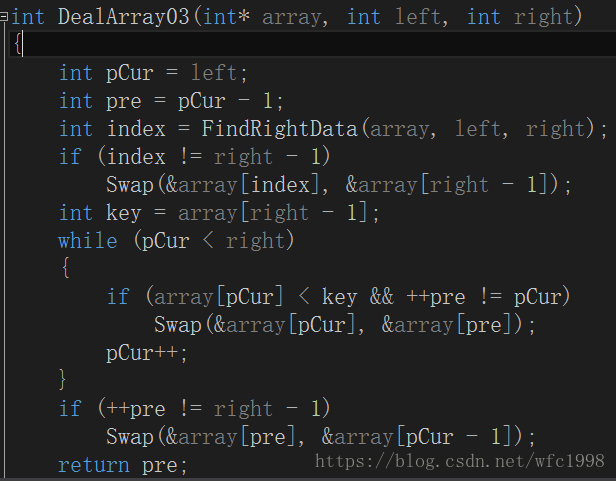
方法三:前后标记法
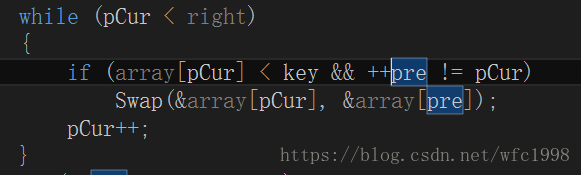
- 数组最后一个数据为基准值,创建一个变量pCur标记数组第一个数字,再创建一个变量标记pPre标记pCur前一个位置的数据
- 如果1,当前pCur位置的数据比基准值小;2,++pPre不等于pCur,满足这两个条件,就将pCur位置的数和pPre位置的数交换。如果不满足这两个条件,就不交换,pCur++向后走;
- 比如现在pCur位置的数据2比基准值小,但是不满足第二个条件,所以不交换,但是++pPre已经执行了,所以pPre到了2的位置,pCur++向后走,遇到6,第一个条件就不满足,第二个条件就不执行,不交换,pPre依然在2的位置
- 到这个位置,pCur当前为4,小于基准值,++pPre也不等于pCur,pPre已经在6的位置,满足两个条件,然后交换pPre和pCur这两个位置的数据,如下图
- 继续以上过程,当pCur走到3的时候要发生交换
- 一直继续这个过程,当pCur走出数组的时候,如下图
- 把最后一个数据和pPre后一个位置的数据交换位置,基准值左边的数比基准值小,基准右边的数比基准值大,结束本区间的排序,然后不断缩小区间,使得整个数组完全有序。
- 代码实现
- 处理这个数列的方式是前后标记法,下面是对函数的调用
递归调用函数,根据传参的不同,不断缩小区间,直到区间里只有一个数据为止,

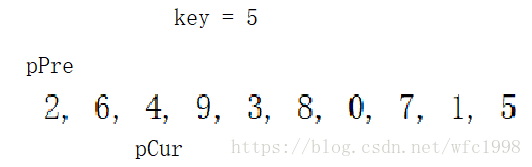

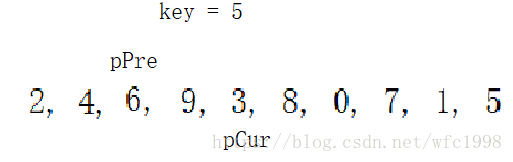
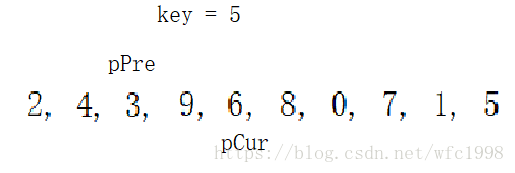


运行结果
三,快速排序的优化
1,为什么要优化?
以上提供的三种快速排序的方法,都是把最后一个数当作基准值,然后把整个数组升序排列,如果最有一个数为这个数组里的最大值或者最小值,会导致递归次数变多,而增加运行时间。
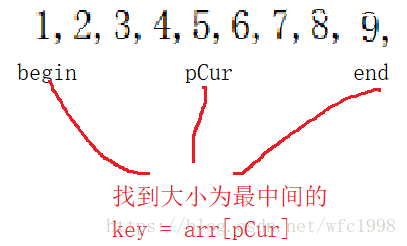
2,怎么优化?
取数组中第一个数,最后一个数和最中间一个数,然后把大小为中间的数找到并返回,如图
3,代码实现
int FindRightData(int* array, int left, int right)
{
int mid = left + (right - left) / 2;
if (array[left] < array[right - 1])
{
if (array[mid] < array[left])
return left;
else if (array[right- 1] < array[mid])
return right - 1;
else
return mid;
}
else
{
if (array[mid] > array[left])
return left;
else if (array[right - 1] < array[mid])
return right - 1;
else
return mid;
}
}
这个方法可以尽量避免取到数列里的最大值或者最小值

四,快速排序性能分析
时间复杂度
1、最优情况
在最优情况下,划分数组的函数每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为 [log2n]+1( [x] 表示不大于 x 的最大整数),即仅需递归 log2n 次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,就有了下面的不等式推断:
这说明,在最优的情况下,快速排序算法的时间复杂度为O(nlogn)。
2、最糟糕情况
然后再来看最糟糕情况下的快排,当待排序的序列为正序或逆序排列时,且每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为 ,最终其时间复杂度为O(n^2)。
空间复杂度
1,如果需要产生O(log n)嵌套递归调用,它需要在他们每一个存储一个固定数量的信息。因为最好的情况最多需要O(log n)次的嵌套递归调用,所以它需要O(log n)的空间。
2,最坏情况下需要O(n)次嵌套递归调用,因此需要O(n)的空间。