OpenAI GPT是2018年OpenAI发表的论文《Improving Language Understandingby Generative Pre-Training》中提出来的。它主要是一种无监督预训练+有监督微调的方法。我们的目标是学习一个通用的语言表示,可以经过很小的调整就应用在各种任务中。模型有两个过程:
1.无监督预训练的过程
它也是使用语言模型去完成无监督的训练。由待预测词的上文预测该词,它使用的模型是基于transformer结构解码器的语言模型,则非监督的极大似然为:
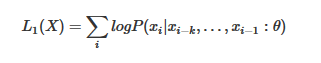
当模型预训练好后,进行过程2
2.有监督微调的过程(fine-tuning)
和ELMO不一样,在进行下游任务时,ELMO可以将新融合的词向量放入其他的模型结构中。而OpenAI GPT只能使用和预训练一样的模型结构。假设自己有标签数据集C。里面的数据结构为(x1,x2,…,xm,y),首先加载好预训练好的模型的参数,然后将自己的数据(x1,x2,…,xm)输入到预训练好的模型中,进行语言模型的微调。怎么微调呢,就是在自己的数据集上进行两个任务:语言模型辅助微调和标签预测。语言模型的预测和预训练是一样的,标签预测就是将数据输入transformer中,将模型输出的向量h再经过另外一个线性层和softmax预测标签,并和真实值求损失。可以得到标签预测的极大似然为:
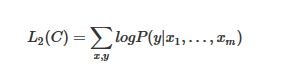
语言模型辅助微调的极大似然为:L1 ( C ), λ为权重
因此最终得到的总的极大似然为:
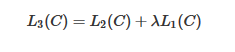
λ为超参。其中L2 ( C )为分类极大似然。L1 ( C )为微调的极大似然。
模型的优缺点:
优点:
1.相对循环神经网络(rnn或lstm),transformer可以捕捉到更长范围的信息
2.计算速度比循环神经网络更快,易于并行化
3.在大数据集上使用语言模型作为附加任务的效果更好,小数据集不然
缺点:
对于某些类型的任务如文本蕴涵任务、文本相似度任务、问答对选择等需要对输入数据的结构作调整,并不是太友好