aggregate(zeroValue, seqOp, combOp)
Aggregate the elements of each partition, and then the results for all the partitions, using a given combine functions and a neutral “zero value.”
seqOp
“”"
每个分区执行的聚合函数
对rdd中按分区每个元素y执行此函数, x为上一次的执行结果, 首次计算时使用默认值zeroValue
“”"
comOp
“”"
对每个分区的结果执行的聚合函数
执行此函数时, 每个分区的计算结果y执行此函数, x为上一次的执行结果, 首次计算时使用默认值zeroValue
“”"
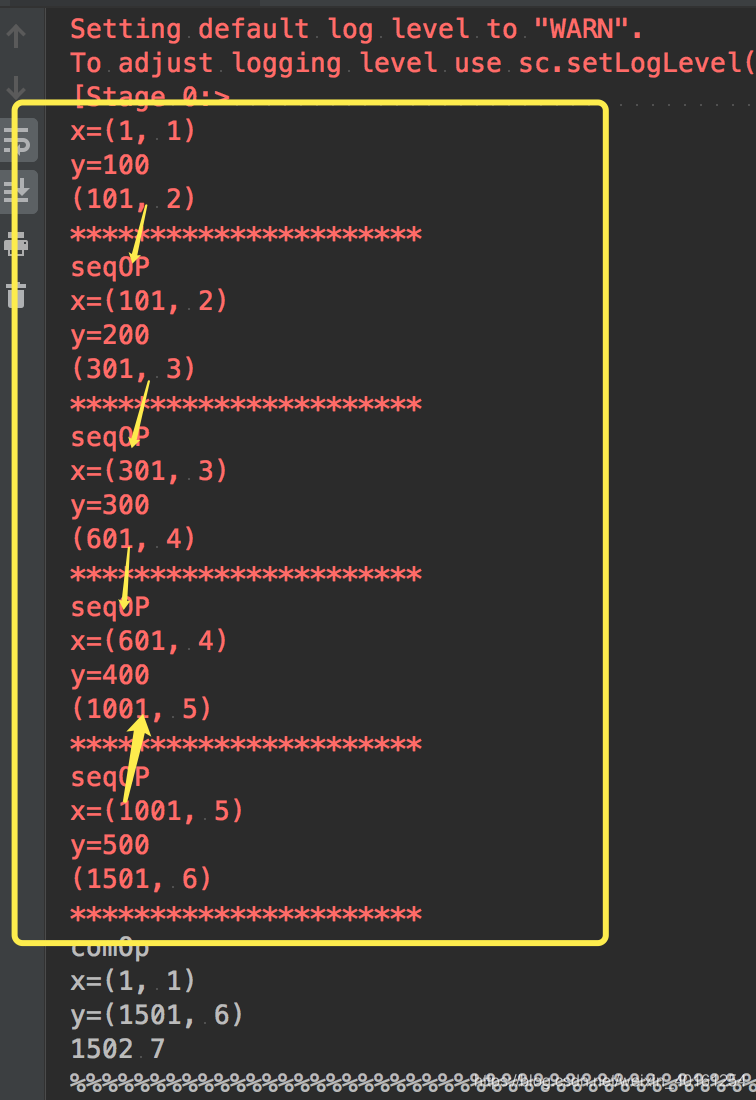
例子 分5partition
def seqOp1(x, y):
print('seqOP')
print('x='+str(x))
print('y='+str(y))
a = x[0] + y
b = x[1] + 1
print((a, b))
print("*" * 22)
return (a, b)
def combOp1(x, y):
print('comOp')
print('x=' + str(x))
print('y=' + str(y))
a = x[0] + y[0]
b = x[1] + y[1]
print(a, b)
print("%%" * 22)
return (a, b)
a = sc.parallelize([100, 200, 300, 400, 500], 5).aggregate((1, 1), seqOp1, combOp1)
print(a)
result:
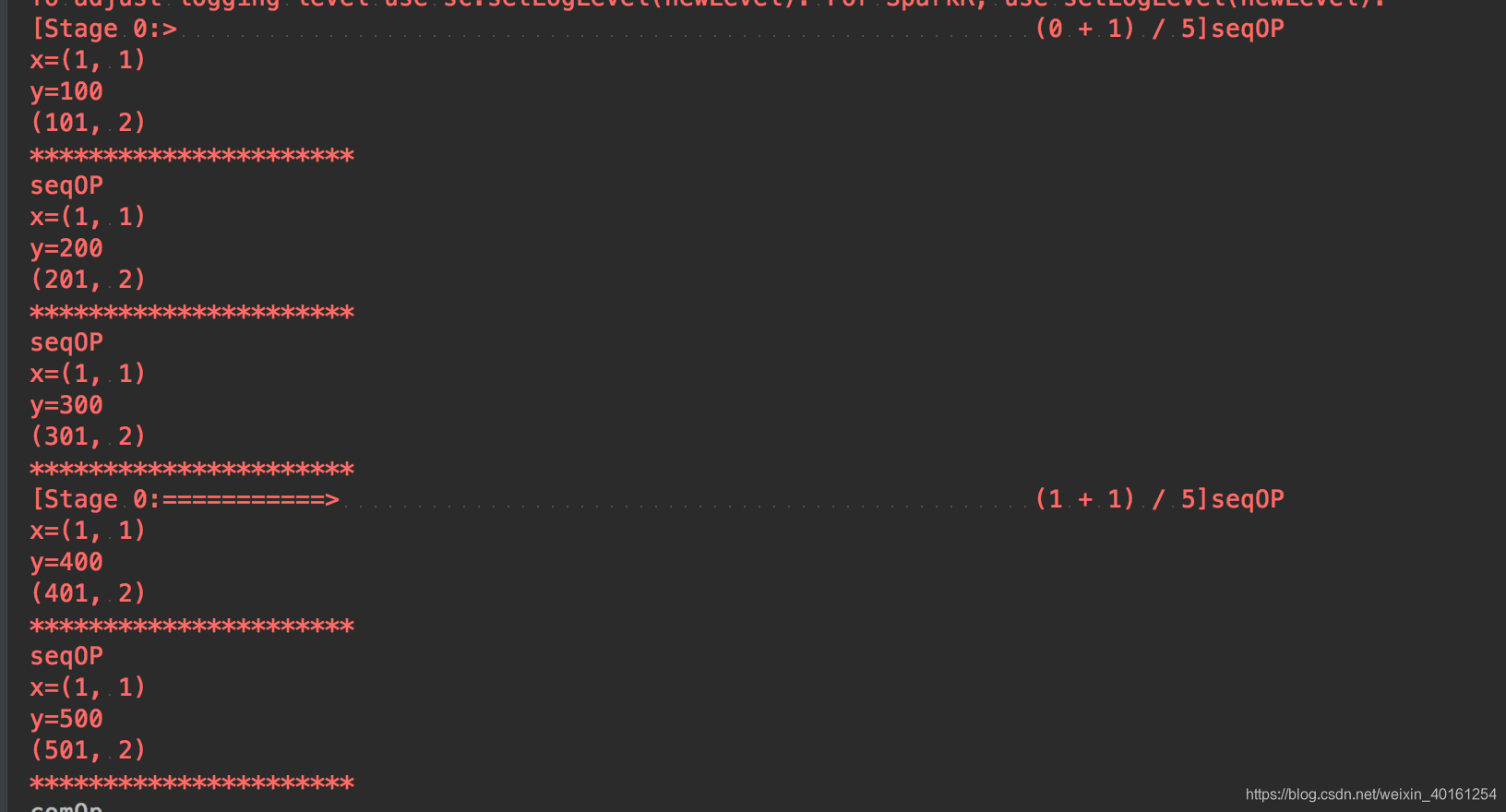
在这里插入图片描述
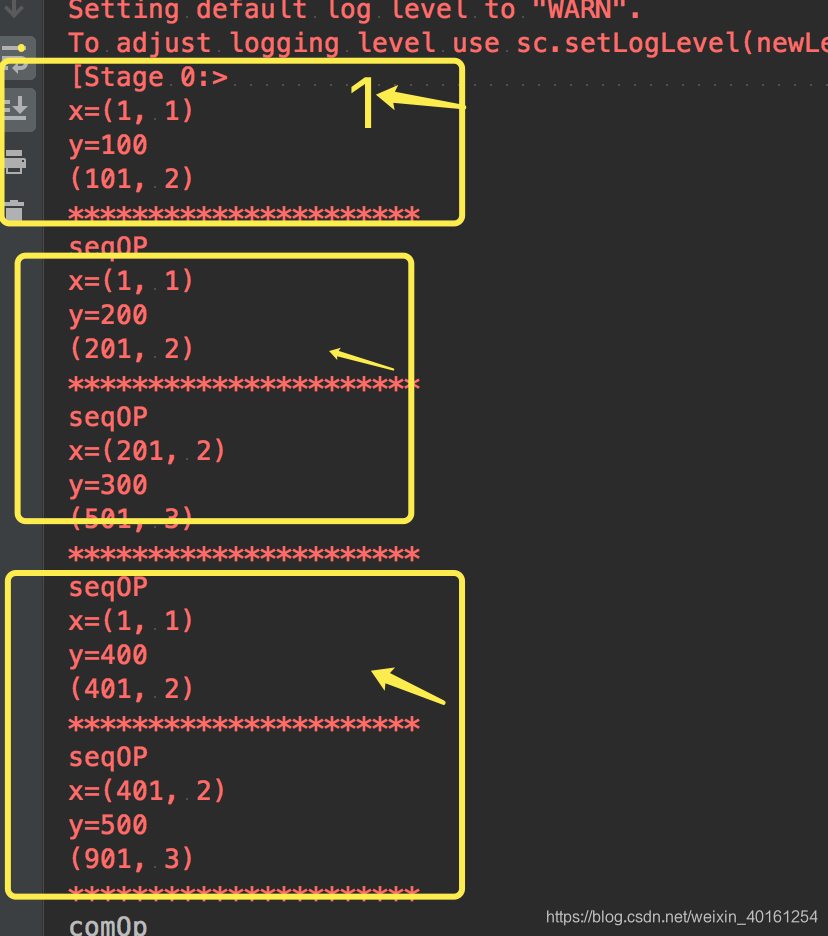
例子 分4partition
def seqOp1(x, y):
print('seqOP')
print('x='+str(x))
print('y='+str(y))
a = x[0] + y
b = x[1] + 1
print((a, b))
print("*" * 22)
return (a, b)
def combOp1(x, y):
print('comOp')
print('x=' + str(x))
print('y=' + str(y))
a = x[0] + y[0]
b = x[1] + y[1]
print(a, b)
print("%%" * 22)
return (a, b)
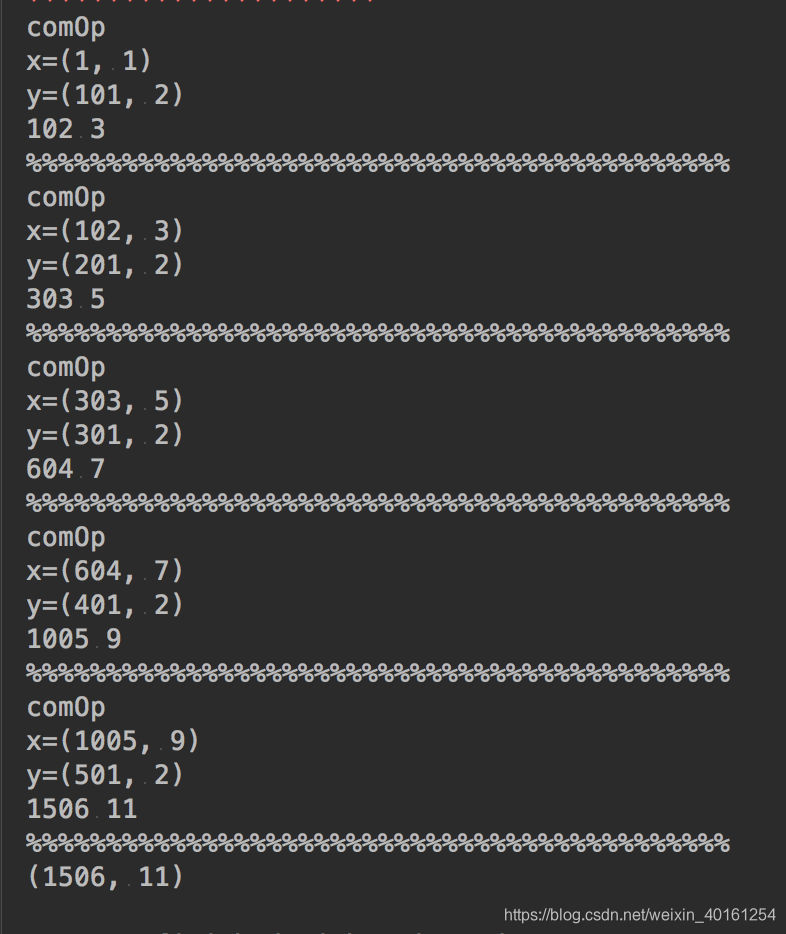
a = sc.parallelize([100, 200, 300, 400, 500], 4).aggregate((1, 1), seqOp1, combOp1)
print(a)
结果
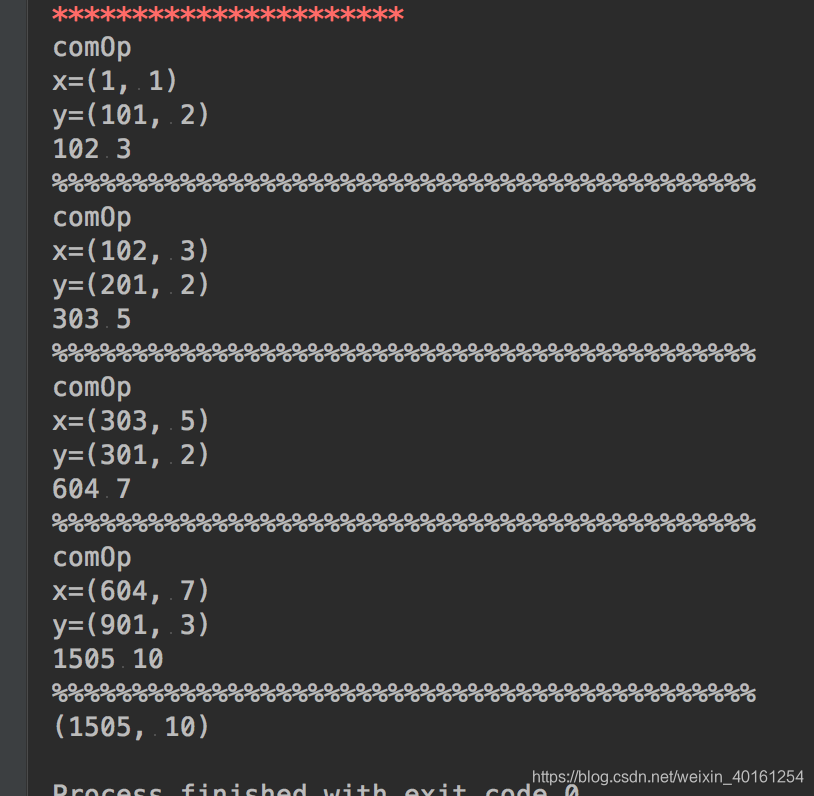
例子 分3partition
def seqOp1(x, y):
print('seqOP')
print('x='+str(x))
print('y='+str(y))
a = x[0] + y
b = x[1] + 1
print((a, b))
print("*" * 22)
return (a, b)
def combOp1(x, y):
print('comOp')
print('x=' + str(x))
print('y=' + str(y))
a = x[0] + y[0]
b = x[1] + y[1]
print(a, b)
print("%%" * 22)
return (a, b)
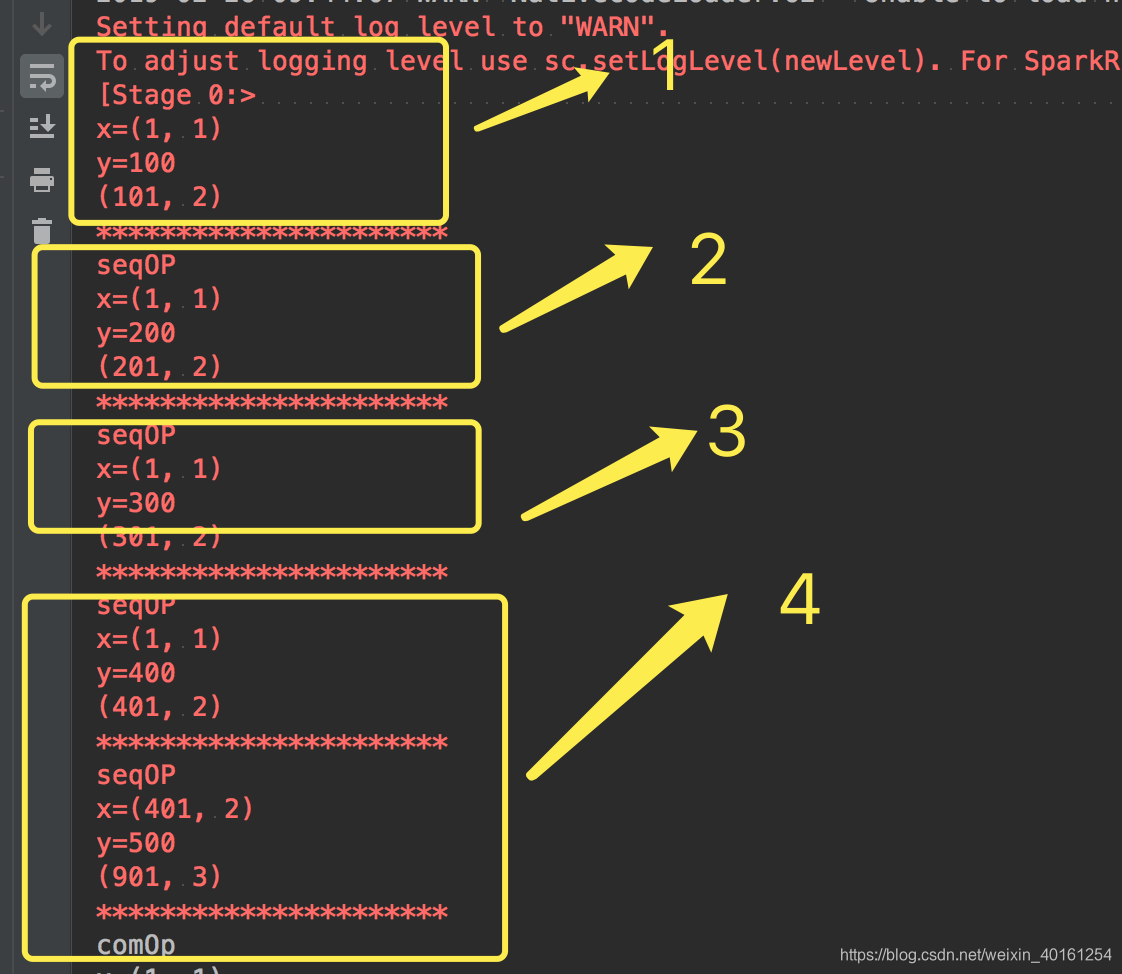
a = sc.parallelize([100, 200, 300, 400, 500], 3).aggregate((1, 1), seqOp1, combOp1)
print(a)

同理1分区
a = sc.parallelize([100, 200, 300, 400, 500], 1).aggregate((1, 1), seqOp1, combOp1)
结果