版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_36470920/article/details/76360021
使用广度优先遍历来遍历下方的无向图,一个可能的输出序列是:
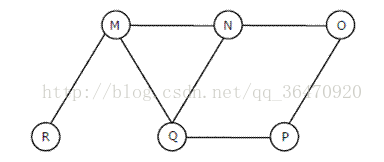
A. MNOPQR
B. NQMPOR
C. QMNPRO
D. QMNPOR
分析:这道题考广度优先搜索,很郁闷最近的我可能因为熬夜使得脑子转不过来,太笨了吧,看着道题如果不说代码实现的话很简单。只要掌握了原理就好:
先看M,广度优先可能的有
M-R-Q-N-P-O
M-R-Q-N-O-P
M-R-N-Q-P-O
M-R-N-Q-O-P
M-Q-R-N-P-O
M-Q-R-N-O-P
M-Q-N-R-P-O
M-Q-N-R-O-P
M-N-Q-R-P-O
M-N-Q-R-O-P
M-N-R-Q-P-O
M-N-R-Q-O-P
一共有3*2*1(RQN全排列)*2*1(OP全排列)=12种高中老樊爷爷教过的
满满回忆ing
再看N开头的:
N-M-Q-O-P-R
N-M-Q-O-R-P
N-M-O-Q-P-R
N-M-O-Q-R-P
N-Q-M-O-P-R
N-Q-M-O-R-P
N-Q-O-M-P-R
N-Q-O-M-R-P
N-O-M-Q-P-R
N-O-M-Q-R-P
N-O-Q-M-P-R
N-O-Q-M-R-P
一共有3*2*1(MQO全排列)*2*(PR全排列)=12种
再看Q开头的:
Q-M-N-P-O-R
Q-M-N-P-R-O(题目答案C)
Q-M-P-N-O-R
Q-M-P-N-R-O
Q-N-P-M-O-R
Q-N-P-M-R-O
Q-N-M-P-O-R
Q-N-M-P-R-O
Q-P-N-M-O-R
Q-P-N-M-R-O
Q-P-M-N-O-R
Q-P-M-N-R-O
一共有3*2*1(MNP全排列)*2*1(RO全排列)=12种
因此本题答案选C
下面我用Python代码来完成广度优先和深度优先算法,程序还有些问题,目前我的水平有限所以就先写个这,后面会再改的,大体上的功能是实现了的
E:\Python27\python.exe "D:/python/python 数据结构/Graph.py"
nodes: [1, 2, 3, 4, 5, 6, 7, 8]
1 : [2, 3]
2 : [1, 4, 5]
3 : [1, 6, 7]
4 : [2, 8]
5 : [2, 8]
6 : [3, 7]
7 : [3, 6]
8 : [4, 5]
the breath first search list is:
[1, 2, 3, 4, 5, 6, 7, 8]
the depth first search list is:
[1, 2, 4, 8, 5, 3, 6, 7]
Process finished with exit code 0
A. MNOPQR
B. NQMPOR
C. QMNPRO
D. QMNPOR
分析:这道题考广度优先搜索,很郁闷最近的我可能因为熬夜使得脑子转不过来,太笨了吧,看着道题如果不说代码实现的话很简单。只要掌握了原理就好:
先看M,广度优先可能的有
M-R-Q-N-P-O
M-R-Q-N-O-P
M-R-N-Q-P-O
M-R-N-Q-O-P
M-Q-R-N-P-O
M-Q-R-N-O-P
M-Q-N-R-P-O
M-Q-N-R-O-P
M-N-Q-R-P-O
M-N-Q-R-O-P
M-N-R-Q-P-O
M-N-R-Q-O-P
一共有3*2*1(RQN全排列)*2*1(OP全排列)=12种高中老樊爷爷教过的
满满回忆ing
再看N开头的:
N-M-Q-O-P-R
N-M-Q-O-R-P
N-M-O-Q-P-R
N-M-O-Q-R-P
N-Q-M-O-P-R
N-Q-M-O-R-P
N-Q-O-M-P-R
N-Q-O-M-R-P
N-O-M-Q-P-R
N-O-M-Q-R-P
N-O-Q-M-P-R
N-O-Q-M-R-P
一共有3*2*1(MQO全排列)*2*(PR全排列)=12种
再看Q开头的:
Q-M-N-P-O-R
Q-M-N-P-R-O(题目答案C)
Q-M-P-N-O-R
Q-M-P-N-R-O
Q-N-P-M-O-R
Q-N-P-M-R-O
Q-N-M-P-O-R
Q-N-M-P-R-O
Q-P-N-M-O-R
Q-P-N-M-R-O
Q-P-M-N-O-R
Q-P-M-N-R-O
一共有3*2*1(MNP全排列)*2*1(RO全排列)=12种
因此本题答案选C
下面我用Python代码来完成广度优先和深度优先算法,程序还有些问题,目前我的水平有限所以就先写个这,后面会再改的,大体上的功能是实现了的
#-*-coding:utf-8-*- #depth_first_search #breadth_first_search class Graph(object): def __init__(self,*args,**kwargs): self.node_neighbors = {} #这是图的顶点存储的结构表示,也就是用字典的方法表示 #其中key值代表图的顶点,value代表相邻顶点,也就是这个顶点 #指向的顶点。和这个顶点连接的顶点。 self.depth_visited = [] self.breath_visited = [] #visit表示访问过的顶点列表,访问过这个定点的话就把它加进去 #这个列表里面 def add_nodes(self,nodelist): for node in nodelist: self.node_neighbors[node] = [] #这个方法是用来添加顶点,将nodelist里的顶点添加进去 def add_edge(self,edge): u,v = edge if(v not in self.node_neighbors[u]) and (u not in self.node_neighbors[v]): self.node_neighbors[u].append(v) self.node_neighbors[v].append(u) #这个方法是实现添加图里面的边,也就是说如果顶点字典里面某个 #顶点key u的value 列表里面没有顶点v,而且u连接了v,那么就在 #u的value列表里把v添加进去。同理在v的value列表里添加u进去 def depth_first_search(self): order = []#order是最后生成的路线图 def dfs(node): for i in self.node_neighbors[node]: if i not in self.depth_visited: self.depth_visited.append(i) order.append(i) dfs(i) for node in self.node_neighbors.keys(): if node not in self.depth_visited: order.append(node) self.depth_visited.append(node) dfs(node) print order def breath_first_search(self): queue = [] order = [] def bfs(): while len(queue) > 0: node = queue.pop(0) if node not in self.breath_visited: self.breath_visited.append(node) for n in self.node_neighbors[node]: if (not n in self.breath_visited) and (not n in queue): queue.append(n) order.append(n) for node in self.node_neighbors.keys(): if not node in self.breath_visited: queue.append(node) order.append(node) bfs() print order g = Graph() g.add_nodes(i+1 for i in range(8)) g.add_edge((1,2)) g.add_edge((1,3)) g.add_edge((2,4)) g.add_edge((2,5)) g.add_edge((4,8)) g.add_edge((5,8)) g.add_edge((3,6)) g.add_edge((3,7)) g.add_edge((6,7)) print 'nodes:',g.node_neighbors.keys() for node,value in g.node_neighbors.items(): print node, ':', value print 'the breath first search list is:' order1 = g.breath_first_search() print 'the depth first search list is:' order2 = g.depth_first_search()
E:\Python27\python.exe "D:/python/python 数据结构/Graph.py"
nodes: [1, 2, 3, 4, 5, 6, 7, 8]
1 : [2, 3]
2 : [1, 4, 5]
3 : [1, 6, 7]
4 : [2, 8]
5 : [2, 8]
6 : [3, 7]
7 : [3, 6]
8 : [4, 5]
the breath first search list is:
[1, 2, 3, 4, 5, 6, 7, 8]
the depth first search list is:
[1, 2, 4, 8, 5, 3, 6, 7]
Process finished with exit code 0