目录
二、ArrayList、LinkedList、Vector的区别
三、HashMap和ConcurrentHashMap的区别
一、HashMap和Hashtable的区别
1、Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了;
2、继承不同:Hashtable基于Dictionary类 ,HashMap基于AbstractMap,而AbstractMap基于Map接口的实现;
3、Hashtable中key和value都不允许为null,遇到null,直接返回 NullPointerException ;HashMap中key和value都允许为null,遇到key为null的时候,调用putForNullKey方法进行处理,而对value没有处理;
4、两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式;
5、Hashtable中hash数组默认大小是11,扩充方式是old*2+1 ;HashMap中hash数组的默认大小是16,而且一定是2的指数。
二、ArrayList、LinkedList、Vector的区别
1、ArrayList、LinkedList和Vector都是实现了List接口。
2、其中,ArrayList和Vector底层是用数组实现的,因此可以用序号下标来访问他们,查找的效率高,一般数组的大小比要插入的数据大数量要大。
3、LinkedList的底层使用双向链表实现的,因此插入和删除的效率高。
4、在多线程并发的时候,ArrayList和LinkedList是非线程安全的,并且是不同步的。Vector的所有方法都用了synchronized方法,是线程安全的,但是vector中的方法组合起来使用不是线程安全的。
三、HashMap和ConcurrentHashMap的区别
1、Hashmap本质是数组加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以HashMap是线程不安全的;
2、ConcurrentHashMap:在HashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁的几率,实现线程安全,提高并发效率。
四、HashMap和LinkedHashMap的区别
1、LinkedHashMap有序的,有插入顺序和访问顺序 ,HashMap无序的;
2、LinkedHashMap内部维护着一个运行于所有条目的双向链表 ,HashMap内部维护着一个单链表。
总结归纳:linkedMap在于存储数据你想保持进入的顺序与被取出的顺序一致的话,优先考虑LinkedMap,HashMap键只能允许一条为空,value可以允许为多条为空,键唯一,但值可以多个。
五、HashMap是非线程安全的原因及实现线程安全的方法
原文地址:https://blog.csdn.net/qq_39940205/article/details/80539079
线程不安全的原因:
在多线程环境下,假设有容器map,其存储的情况如下图所示(淡蓝色为已有数据)。

此时的map已经达到了扩容阈值12(16 * 0.75 = 12),而此时线程A与线程B同时对map容器进行插入操作,那么都需要扩容。此时可能出现的情况如下:线程A与线程B都进行了扩容,此时便有两个新的table,那么再赋值给原先的table变量时,便会出现其中一个newTable会被覆盖,假如线程B扩容的newTable覆盖了线程A扩容的newTable,并且是在A已经执行了插入操作之后,那么就会出现线程A的插入失效问题,也即是如下图中的两个table只能有一个会最后存在,而其中一个插入的值会被舍弃的问题。
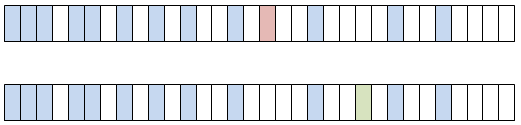
这便是HashMap的线程不安全性,当然这只是其中的一点。而要消除这种隐患,则可以加锁或使用HashTable和ConcurrentHashMap这样的线程安全类,但是HashTable不被建议使用,推荐使用ConcurrentHashMap容器。
那么怎么才能让HashMap变成线程安全的呢?
可以通过以下三种方法来实现:
1.替换成Hashtable,Hashtable通过对整个表上锁实现线程安全,因此效率比较低;(不推荐)
2.使用Collections类的synchronizedMap方法包装一下。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射;
3.使用ConcurrentHashMap,它使用分段锁来保证线程安全,效率高,推荐使用。
六、ConcurrentHashMap实现线程安全的原理
ConcurrentHashMap将数据分别放到多个Segment中,默认16个,每一个Segment中又包含了多个HashEntry列表数组,
对于一个key,需要经过三次hash操作,才能最终定位这个元素的位置,这三次hash分别为:
- 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key);
- 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment;
- 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在哪个HashEntry。
每一个Segment都拥有一个锁,当进行写操作时,只需要锁定一个Segment,而其它Segment中的数据是可以访问的。
总结:ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁的几率,提高并发效率。