出处:2018年1月的IEEE TIP上的文章
数据库:LIVE,CISQ,TID2013和Wild Image Quality Challenge数据库
源码:https://github.com/dmaniry/deepIQA
贡献
1、针对IQM问题的公开数据集比较小,作者在图像上进行random sample patch方法,每个patch的质量分为整张图片的质量数;
2、对局部区域采用加权方法(Weighted Average Deep Image QuAlity Measure);
3、不做归一化,从而使得luminance和contrast这类的全局特征也可以作为评价的特征;
4、采用了Siamese network的结构(VGG)
模型
FR模型:


NR模型:

区别:FR模型去掉孪生网络的一个分支就是NR模型
FR前向传播:首先,两个输入(distorted和reference)通过一个孪生CNN网络(也就是权值共享的结构相同的网络),然后得到feature vector,这个提取特征的网络是一个vgg-like的,分别得到的两个feature vector,两者进行fusion,再显式的加上两者的差,进行concat,得到融合的vector,即 ,用于回归。如果是对图像的patch 的Q进行平均的话,那么就只需要回归patch上的quality,而如果要加权平均,同时还要回归一个权重。然后做一个spatial pooling,得到最终的image quality。
,用于回归。如果是对图像的patch 的Q进行平均的话,那么就只需要回归patch上的quality,而如果要加权平均,同时还要回归一个权重。然后做一个spatial pooling,得到最终的image quality。
(1)特征提取:
所有卷积层都应用3×3的卷积核,并通过ReLU激活函数。为了获得与输入相同大小的输出,应用零填充来应用卷积。为了防止过拟合,对于fully-connected layer应用比率为0.5的 Dropout Regularization。论文输入是32×32的patch;
(2)特征融合:
输入distorted和reference的patch,通过Siamese networks两个分支分别直接处理,可以得到参考图像的特征向量 fr 和失真图像的特征向量fd,然后进行特征融合,由于和的spatial 空间是一致的,这使得的差值能够有效地表示特征空间上的距离。为了简化回归任务,显式的加上,即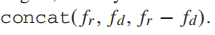 。
。
(3)加权:
简单平均加权:如果是对图像的patch 的质量进行平均的话,那么需要对每个patch的质量回归,最后得到整幅图像的视觉质量,计算方式如下(是图像块的数量,
是每个patch的质量)。

实验总结
1、加权平均的方法受到失真类型和失真空间分布的影响,在某些测试中效果达到没有最好(表一);
2、对于失真图像,参考图像的信息对池化局部权重非常重要(表四);
3、数据集大小对模型性能影响很大(表五);
4、池化局部权重方法的NR具有更强的泛化能力(表六);
5、patch的数量32最佳;
6、特征融合使用 效果更好,直接融合fr与fd效果最差(表8);
效果更好,直接融合fr与fd效果最差(表8);