Spark2.2.0
参考《图解Spark》
Spark消息通信原理主要分成三个部分:整体框架;启动消息通信;运行时消息通信
一、Spark通信整体框架
Spark2.2使用Netty作为master与worker的通信框架,Spark2.0之前使用的akka框架。
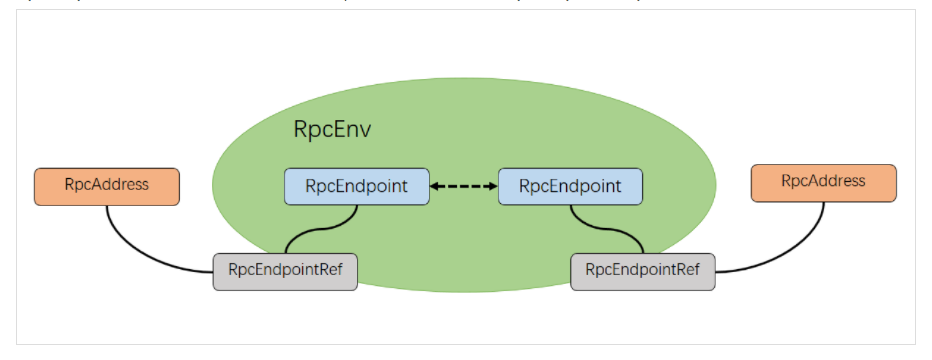
- RpcEndpoint:Spark针对于每个节点(Client/Master/Worker)都称之一个RpcEndPoint,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。一个RpcEndpoint经历的过程依次是:构建->onStart→receive→onStop。其中onStart在接收任务消息前调用,receive和receiveAndReply分别用来接收另一个RpcEndpoint(也可以是本身)send和ask过来的消息。
- RpcEndpointRef:是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
- RpcAddress: 表示远程的RpcEndpointRef的地址,Host + Port。
- RpcEnv:RPC上下文环境,每个RpcEndPoint运行时依赖的上下文环境称之为RpcEnv。RpcEnv负责RpcEndpoint整个生命周期的管理,包括:注册endpoint,endpoint之间消息的路由,以及停止endpoint。
- Dispatcher:消息分发器,针对于RPC端点需要发送消息或者从远程RPC接收到的消息,分发至对应的指令收件箱/发件箱。

通信框架使用了工厂设计模式实现,这种设计方式实现了对Netty的解耦,能够根据需要引入其他的消息通信工具。
具体的实现步骤如下:
在RpcEnv中定义了RPC通信框架的启动、停止和关闭等抽象方法,在RpcEnvFactory中定义了创建抽象方法。
在各个模块中的实现,如Master和Worker等,会先使用RpcEnv的静态方法创建RpcEnv实例,然后实例化Master,由于Master继承ThreadSafeRpcEndPoin,创建的Master实例是一个线程安全的EndPoint,接着调用RpcEnv的启动endpoint方法,把Master的终端点和其对应的引用注册到RpcEnv中。在消息通信中,其他对象只需要获取到了Master EndPoint的引用,就能发送消息给Master进行通信。
二、Spark启动消息通信
worker向Master发送注册消息,master处理完毕后返回注册成功或者是失败的消息,如果成功,worker向master定时发送心跳。
具体启动过程如下:
- 当master启动之后再启动worker,worker会自动建立通信环境RpcEnv和EndPoint,并且worker会向master发送注册信息RegisterWorker,master处理完毕后返回注册成功或者是失败的消息。HA条件下,worker可能需要注册到多个master上。在worker的tryRegisterAllMasters方法中创建注册线程池RegisterMasterThreadPool,把需要注册的请求放入这个线程池,通过此线程池启动注册线程。注册过程中,(注册线程)获取master EndPoint引用,(注册线程)调用RegisterWithMaster方法,根据master EndPoint引用的send方法给master发送注册消息RegisterWorker。
- master接到注册消息RegisterWorker后,master会对worker发送的消息进行验证,记录。如果注册成功,master发送registeredWorker给对应的worker,告诉worker已经完成注册,进行第3步骤,即worker定期发送心跳给master;如果注册失败,master会给worker发送registerWorkerFailed消息,worker会打印日志并结束worker的启动。master接到worker注册消息后,master先判断自己当前状态是否是STANDBY,如果是则忽略该消息;如果在注册列表发现了该worker编号,master则对worker发送注册失败的消息。判断完毕无误之后,调用registerWorker方法将此worker加入到master自己的列表,用于后续任务调度使用。
- worker收到注册成功的消息后,会定时发送心跳给master,间隔时间是spark.,方便master了解Worker状态。(注意timeout的四分之一才是心跳间隔哦)

三、Spark运行时消息通信
应用程序SparkContext向mater发送注册信息,并由master为该应用分配Exectour,exectour启动之后会向SparkContext发送注册成功消息,然SparkContext的rdd触发Action之后会形成一个DAG,通过DAGScheduler进行划分Stage并将其转化成TaskSet,然后TaskScheduler向Executor发送执行消息,Executor接收到信息之后启动并且运行,最后是由Driver处理结果并回收资源。
详细过程如下:
- 启动SparkContext,启动SparkContext时会实例化一个Schedulerbackend对象,standalone模式下实际创建的是SparkDeploySchedulerbackend对象,在这个对象启动中会继承父类DriverEndpoint和ClientEndpoint这两个endpoint。ClientEndpoint的tryRegisterAllMasters方法中创建注册线程池RegisterMasterThreadPool,在该线程池中启动注册线程并向master发送registerApplication注册应用的消息。master接收到注册应用的消息,在registerApplication方法中记录应用信息,并将该应用加入等待运行应用列表,注册完毕后master发送成功消息RegisteredApplication给ClientEndPoint,同时调用startExecutorOnworker方法运行应用。
- ClientEndpoint接收到Master发送的RegisteredApplication消息,需要把注册标识registered置为true。
- 在Master类的starExecutorsOnWorkers方法中分配资源运行应用程序时,调用allocateWorkerResourceToExecutors方法实现在Worker中启动Executor。当Worker收到Master发送过来的LaunchExecutor消息,先实例化ExecutorRunner对象,在ExecutorRunner启动中会创建进程生成器ProcessBuilder, 然后由该生成器使用command创建CoarseGrainedExecutorBackend对象,该对象是Executor运行的容器,最后Worker发送ExecutorStateChanged消息给Master,通知Executor容器【CoarseGrainedExecutorBackend】已经创建完毕。
- Master接收到Worker发送的ExecutorStateChanged消息
- 在3中的CoarseGrainedExecutorBackend启动方法onStart中,会发送注册Executor消息RegisterExecutor给DriverEndpoint,DriverEndpoint先判断该Executor是否已经注册。
- CoarseGrainedExecutorBackend接收到Executor注册成功RegisteredExecutor消息时,在CoarseGrainedExecutorBackend容器中实例化Executor对象。启动完毕后,会定时向Driver发送心跳信息, 等待接收从DriverEndpoint发送执行任务的消息。
- CoarseGrainedExecutorBackend的Executor启动后接收从DriverEndpoint发送的LaunchTask执行任务消息,任务执行是在Executor的launchTask方法实现的。在执行时会创建TaskRunner进程,由该进程进行任务处理,处理完毕后发送StateUpdate消息返回给CoarseGrainedExecutorBackend。
- 在TaskRunner执行任务完成时,会向DriverEndpoint发送StatusUpdate消息,DriverEndpoint接收到消息会调用TaskSchedulerImpl的statusUpdate方法,根据任务执行不同的结果处理,处理完毕后再给该Executor分配执行任务。
