环境信息
Spark版本:1.6.0
Spark消息通信层设计
Spark 通信层是基于优秀的网络通信框架Netty设计开发的,同时获得了Netty所具有的网络通信的可靠性和高效性。通信框架使用了工厂设计模式实现,这种方式实现了对Netty的解耦,能够根据需要引入其他的消息通信工具。
看看Spark的消息通信类图:
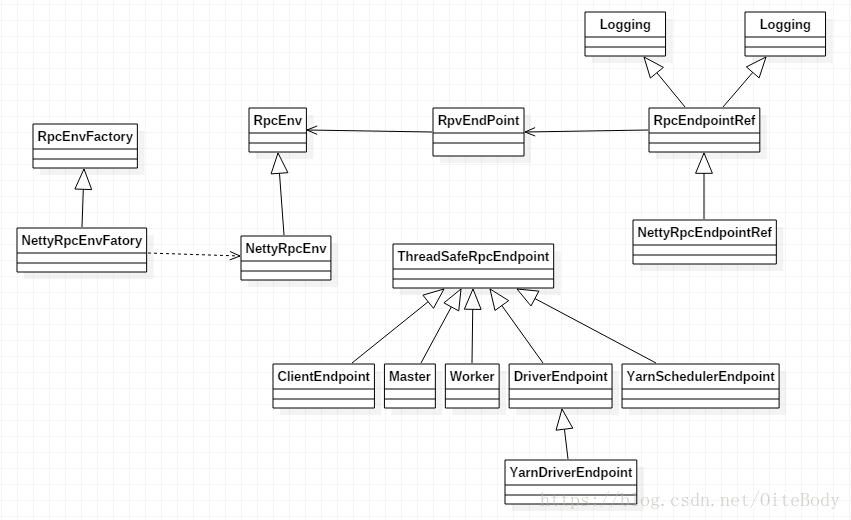
通信框架创建参见上图左边的四个类,具体实现步骤:
1、首先定义了RpcEnv和RpcEnvFactory两个抽象类,在RpcEnv定义了RPC通信框架的启动、停止和关闭等抽象方法,在RpcEnvFactory中定义了创建抽象方法。
2、然后在NettyRpcEnv和NettyRpcEnvFactory类中使用Netty对继承的方法进行了实现。需要注意的是,在NettyRpcEnv中启动终端点方法setupEndpoint,在这个方法中把RpcEndPoint和RpcEndpointRef相互以键值方式存放在线程安全的ConcurrentHashMap中。
3、最后在RpcEnv的object类中,通过反射方式实现了创建RpcEnv的实例的静态方法。
在各模块使用中,如Master、Worker等,会先使用RpcEnv的静态方法创建RpcEnv实例,然后实例化Master,由于Master继承于ThreadSafeRpcEndpoint,创建的Master实例是一个线程安全的终端点,接着调用RpcEnv启动终端点方法,把Master的终端点和其对应的引用注册到RpcEnv中。在消息通信中,其他对象只要获取了Master终端点的引用,就能够发送消息给Master进行通信。下面为Master的startRpcEnvAndEndPoint方法中,启动消息通信框架的代码:
/**
* Start the Master and return a three tuple of:
* (1) The Master RpcEnv
* (2) The web UI bound port
* (3) The REST server bound port, if any
*/
def startRpcEnvAndEndpoint(
host: String,
port: Int,
webUiPort: Int,
conf: SparkConf): (RpcEnv, Int, Option[Int]) = {
val securityMgr = new SecurityManager(conf)
val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME,
new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
val portsResponse = masterEndpoint.askWithRetry[BoundPortsResponse](BoundPortsRequest)
(rpcEnv, portsResponse.webUIPort, portsResponse.restPort)
}Spark消息通信启动过程
Spark启动过程中主要是进行Master和Worker之间的通信,其消息发送关系如下,首先由worker节点向Master发送注册消息,然后Master处理完毕后,返回注册成功消息或失败消息。
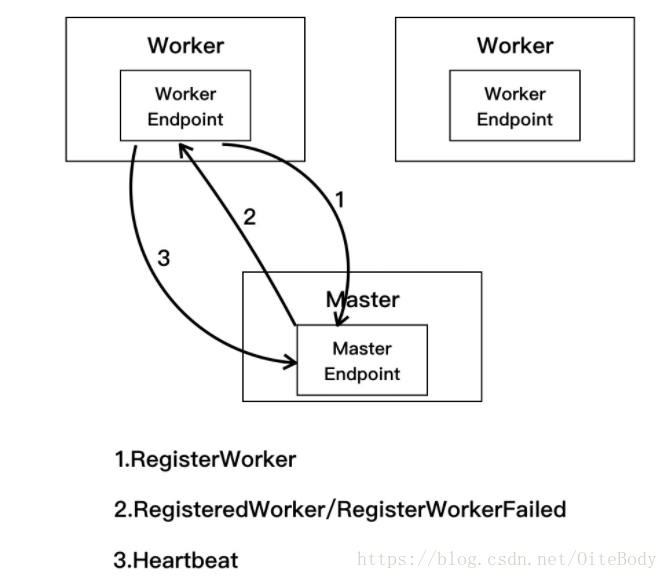
(1) 当Master启动后,随之启动各Worker,Worker启动时会创建通信环境RpcEnv和终端点EndPoint,并向Master发送注册Worker的消息RegisterWorker.Worker.tryRegisterAllMasters方法如下:
// 因为Master可能不止一个
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
masterRpcAddresses.map { masterAddress =>
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = {
try {
logInfo("Connecting to master " + masterAddress + "...")
// 获取Master终端点的引用
val masterEndpoint = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
registerWithMaster(masterEndpoint)
} catch {}
...
}
private def registerWithMaster(masterEndpoint: RpcEndpointRef): Unit = {
// 根据Master节点的引用发送注册信息
masterEndpoint.ask[RegisterWorkerResponse](RegisterWorker(
workerId, host, port, self, cores, memory, workerWebUiUrl))
.onComplete {
// 返回注册成功或失败的结果
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
Utils.tryLogNonFatalError {handleRegisterResponse(msg)}
case Failure(e) =>
logError(s"Cannot register with master: ${masterEndpoint.address}", e)
System.exit(1)
}(ThreadUtils.sameThread)
}随之进行步骤3,即Worker定期发送心跳给Master;如果注册过程中失败,则会发送RegisterWorkerFailed消息,Woker打印出错日志并结束Worker启动。Master.receiverAndReply方法如下:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterWorker(
id, workerHost, workerPort, workerRef, cores, memory, workerWebUiUrl) =>
logInfo("Registering worker %s:%d with %d cores, %s RAM".format(
workerHost, workerPort, cores, Utils.megabytesToString(memory)))
// Master处于STANDBY状态
if (state == RecoveryState.STANDBY) {
context.reply(MasterInStandby)
} else if (idToWorker.contains(id)) { // 在注册列表中发现了该Worker节点
context.reply(RegisterWorkerFailed("Duplicate worker ID"))
} else {
val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,
workerRef, workerWebUiUrl)
// registerWorker方法会把Worker放到注册列表中
if (registerWorker(worker)) {
persistenceEngine.addWorker(worker)
context.reply(RegisteredWorker(self, masterWebUiUrl))
schedule()
} else {
val workerAddress = worker.endpoint.address
logWarning("Worker registration failed. Attempted to re-register worker at same " +
"address: " + workerAddress)
context.reply(RegisterWorkerFailed("Attempted to re-register worker at same address: "
+ workerAddress))
}
}
...
}Worker的handleRegisterResponse方法:
private def handleRegisterResponse(msg: RegisterWorkerResponse): Unit = synchronized {
msg match {
case RegisteredWorker(masterRef, masterWebUiUrl) =>
logInfo("Successfully registered with master " + masterRef.address.toSparkURL)
registered = true
changeMaster(masterRef, masterWebUiUrl)
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(SendHeartbeat)
}
}, 0, HEARTBEAT_MILLIS, TimeUnit.MILLISECONDS)
if (CLEANUP_ENABLED) {
logInfo(
s"Worker cleanup enabled; old application directories will be deleted in: $workDir")
forwordMessageScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(WorkDirCleanup)
}
}, CLEANUP_INTERVAL_MILLIS, CLEANUP_INTERVAL_MILLIS, TimeUnit.MILLISECONDS)
}
case RegisterWorkerFailed(message) =>
if (!registered) {
logError("Worker registration failed: " + message)
System.exit(1)
}
case MasterInStandby =>
// Ignore. Master not yet ready.
}
}
private val HEARTBEAT_MILLIS = conf.getLong("spark.worker.timeout", 60) * 1000 / 4Spark运行时消息通信
用户提交应用程序时,应用程序的SparkContext会向Master发送注册应用信息,并由Master给该应用分配Executor,Executor启动后会向SparkContext发送注册成功消息。
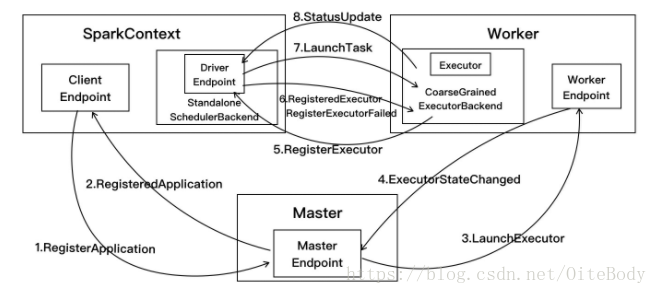
(1) 在SparkContext创建过程中会先实例化SchedulerBackend对象,standalone模式中实际创建的是StandaloneSchedulerBackend对象,在该对象启动过程中会继承父类DriverEndpoint和创建StandaloneAppClient的ClientEndpoint两个终端点。
在ClientEndpoint的tryRegisterAllMasters方法中创建注册线程池registerMasterThreadPool, 在该线程池中启动注册线程并向Master发送RegisterApplication注册应用的消息,代码如下:
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
// 遍历所有的Master, 这是一个for推导式,会构造会一个集合
for (masterAddress <- masterRpcAddresses) yield {
// 在线程池中启动注册线程,当该线程读到应用注册成功标识registered==true时退出注册线程
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) { // private val registered = new AtomicBoolean(false) 原子类型
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
// 发送注册消息
masterRef.send(RegisterApplication(appDescription, self))
} catch {...}
})
}
}override def receive: PartialFunction[Any, Unit] = {
case ElectedLeader => {
val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv)
state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty) {
RecoveryState.ALIVE
} else {
RecoveryState.RECOVERING
}
logInfo("I have been elected leader! New state: " + state)
if (state == RecoveryState.RECOVERING) {
beginRecovery(storedApps, storedDrivers, storedWorkers)
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
self.send(CompleteRecovery)
}
}, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
}
}
case CompleteRecovery => completeRecovery()
case RevokedLeadership => {
logError("Leadership has been revoked -- master shutting down.")
System.exit(0)
}
// 接收Worker发来的RegisteredAppliction消息
case RegisterApplication(description, driver) => {
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}
}
....
}启动Driver和Executors:
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) { return }
// 对Worker节点进行随机排序
val shuffledWorkers = Random.shuffle(workers) // Randomization helps balance drivers
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) {
// 按照顺序在集群中启动Driver,Driver尽量在不同的Worker节点上运行
for (driver <- waitingDrivers) {
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver)
waitingDrivers -= driver
}
}
}
startExecutorsOnWorkers()
}
/**
* Schedule and launch executors on workers
*/
private def startExecutorsOnWorkers(): Unit = {
// 使用FIFO算法运行应用,即先注册的应用先运行
for (app <- waitingApps if app.coresLeft > 0) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
// Filter out workers that don't have enough resources to launch an executor
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
// 一种是spreadOutApps,就是把应用运行在尽量多的Worker上,另一种是非spreadOutApps
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
// 给每个worker分配完application要求的cpu core之后,遍历worker启动executor
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}
override def receive: PartialFunction[Any, Unit] = {
case RegisteredApplication(appId_, masterRef) =>
// FIXME How to handle the following cases?
// 1. A master receives multiple registrations and sends back multiple
// RegisteredApplications due to an unstable network.
// 2. Receive multiple RegisteredApplication from different masters because the master is
// changing.
appId.set(appId_)
registered.set(true)
master = Some(masterRef)
listener.connected(appId.get)
case ApplicationRemoved(message) =>
markDead("Master removed our application: %s".format(message))
stop()
....
}
Worker收到Master发送过来的LaunchExecutor消息,先实例化ExecutorRunner对象,在ExecutorRunner启动中会创建进程生成器ProcessBuilder, 然后由该生成器使用command
创建CoarseGrainedExecutorBackend对象,该对象是Executor运行的容器,最后Worker发送ExecutorStateChanged消息给Master,通知Executor容器已经创建完毕。
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// 创建executor执行目录
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// 创建executor本地目录,当应用程序结束后由worker删除
val appLocalDirs = appDirectories.getOrElse(appId,
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq)
appDirectories(appId) = appLocalDirs
// 在ExecutorRunner中创建CoarseGrainedExecutorBackend对象,创建的是使用应用信息中的command,而command在
// StandaloneSchedulerBackend的start方法中构建
val manager = new ExecutorRunner(appId,execId,appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,memory_,self,workerId,host,webUi.boundPort,publicAddress,sparkHome,executorDir,workerUri,conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start() // 启动ExecutorRunner
coresUsed += cores_
memoryUsed += memory_
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {...}
}在ExecutorRunner创建中调用了fetchAndRunExecutor方法进行实现,在该方法中command内容在StandaloneSchedulerBackend中定义,指定构造Executor运行容器CoarseGrainedExecutorBacken:
private def fetchAndRunExecutor() {
try {
// 通过应用程序信息和环境配置创建构造器builder
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
val formattedCommand = command.asScala.mkString("\"", "\" \"", "\"")
logInfo(s"Launch command: $formattedCommand")
// 在构造器builder中添加执行目录等信息
builder.directory(executorDir)
builder.environment.put("SPARK_EXECUTOR_DIRS", appLocalDirs.mkString(File.pathSeparator))
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
// Add webUI log urls
val baseUrl =
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
// 启动构造器,创建CoarseGrainedExecutorBackend实例
process = builder.start()
val header = "Spark Executor Command: %s\n%s\n\n".format(
formattedCommand, "=" * 40)
// 输出CoarseGrainedExecutorBackend实例运行信息
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, StandardCharsets.UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// 等待CoarseGrainedExecutorBackend运行结束,当结束时向Worker发送退出状态信息
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
} catch {...}
}(4) Master接收到Worker发送的ExecutorStateChanged消息:
case ExecutorStateChanged(appId, execId, state, message, exitStatus) =>
// 找到executor对应的app,然后flatMap,通过app内部的缓存获取executor信息
val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId))
execOption match {
case Some(exec) =>
// 设置executor的当前状态
val appInfo = idToApp(appId)
val oldState = exec.state
exec.state = state
if (state == ExecutorState.RUNNING) {
assert(oldState == ExecutorState.LAUNCHING,
s"executor $execId state transfer from $oldState to RUNNING is illegal")
appInfo.resetRetryCount()
}
// 向Driver发送ExecutorUpdated消息
exec.application.driver.send(ExecutorUpdated(execId, state, message, exitStatus, false))
...中分配运行任务资源,最后发送LaunchTask消息执行任务:
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
context.reply(true)
} else {
...
// 记录executor编号以及该executor需要使用的核数
addressToExecutorId(executorAddress) = executorId
totalCoreCount.addAndGet(cores)
totalRegisteredExecutors.addAndGet(1)
val data = new ExecutorData(executorRef, executorRef.address, hostname,
cores, cores, logUrls)
// 创建executor编号和其具体信息的键值列表
CoarseGrainedSchedulerBackend.this.synchronized {
executorDataMap.put(executorId, data)
if (currentExecutorIdCounter < executorId.toInt) {
currentExecutorIdCounter = executorId.toInt
}
if (numPendingExecutors > 0) {
numPendingExecutors -= 1
logDebug(s"Decremented number of pending executors ($numPendingExecutors left)")
}
}
// 回复Executor完成注册消息并在监听总线中加入添加executor事件
executorRef.send(RegisteredExecutor)
context.reply(true)
listenerBus.post(
SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data))
// 分配运行任务资源并发送LaunchTask消息执行任务
makeOffers()
}Executor对象。启动完毕后,会定时向Driver发送心跳信息, 等待接收从DriverEndpoint发送执行任务的消息。
// 向driver注册成功了,返回RegisteredExecutor消息
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
// 新建Executor, 该Executor会定时向Driver发送心跳信息,等待Driver下发任务
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {...}处理完毕后发送StateUpdate消息返回给CoarseGrainedExecutorBackend:
def launchTask(context: ExecutorBackend,taskId: Long,
attemptNumber: Int,taskName: String,serializedTask: ByteBuffer): Unit = {
// 对于每一个task创建一个TaskRunner
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,serializedTask)
// 将taskRunner放入内存缓存
runningTasks.put(taskId, tr)
// 将taskRunner放入线程池中,会自动排队
threadPool.execute(tr)
}(8) 在TaskRunner执行任务完成时,会向DriverEndpoint发送StatusUpdate消息,DriverEndpoint接收到消息会调用TaskSchedulerImpl的statusUpdate方法,根据任务执行不同的结果处理,处理完毕后再给该Executor分配执行任务:
case StatusUpdate(executorId, taskId, state, data) =>
// 调用TaskSchedulerImpl的statusUpdate方法,根据任务执行不同的结果处理
scheduler.statusUpdate(taskId, state, data.value)
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
// 任务执行成功后,回收该Executor运行该任务的CPU,再根据实际情况分配任务
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None => ...
}
}