损失函数是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
损失函数分类
损失函数基本可以分为分类损失(Classification Loss)和回归损失(Regression Loss)

下面主要介绍5种常见的损失函数。
损失函数介绍
0-1损失函数,最直观的损失函数就是模型的预测结果,即0-1损失函数(0-1 Loss Function),其数据表达式如下:

虽然0-1损失函数能够客观的评价模型的好坏,但缺点是数学性质不好,不连续且不可导,比较难以优化。因此经常使用连续可微的损失函数代替。
平方损失函数(Quadratic Loss Function),经常用在预测标签y为实数值的任务中。其数学表达式如下:
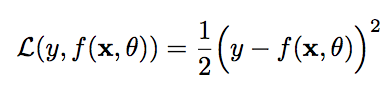
平方损失函数一般不适用于分类问题。
附:平方损失函数前边有系数1/2 是因为在求倒数之后将系数去掉。
交叉熵损失函数(Cross-Entroy Loss Function),一般用于分类问题。假设样本的标签y属于{1,2,....,C}为离散的类别,模型f(x,theta)属于[0,1]^C 的输出为类别标签的条件概率分布,即:
![]()
并满足:
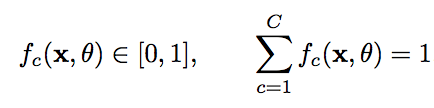
我们可以使用一个C维的one-hot向量y来表示样本标签。假设样本的标签为k,那么标签向量y只有第k维的值为1,其余元素的值为0。标签向量y可以看作是样本标签的真实概率分布。即第c维(记为y_c,1=< c =<C )是类别c的真实概率。假设样本的类别为k,那么他属于第k类的概率为1,其他类的概率为0。
对于两个概率分布,一般可以用交叉熵来衡量他们的差异。标签的真实概率分布y和预测样本概率f(x,theta)之间的交叉熵为:
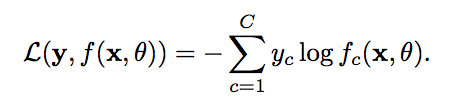
比如对于三分类问题,一个样本的 标签向量为y=[0,0,1]^T,模型预测的标签分布为f(x,theta)=[0.3,0.3,0.4]^T,则他们的交叉熵为:

因为y为one-hot向量,公式-1也可以写为:
![]()
其中f_y(x,theta)可以看作是真实类别y的似然函数,因此交叉熵损失函数也就是负对数似然损失函数(Negative Log-likelihood Function)。
对数损失函数(Logarithmic Loss Function),该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。

Hinge损失函数(Hinge Loss Function),对于二分类问题,假设y和f(x,theta)的取值分别为{-1,+1},Hinge损失函数为:

损失函数/代价函数/目标函数区别
损失函数和代价函数是同一个东西,目标函数是一个与他们相关但更广的概念
- 损失函数:定义在某个样本上的,是指一个样本的误差
- 代价函数:是定义在整个训练集上的,是所有样本误差的平均,也就是所有损失函数值的平均
- 目标函数:是指最终需要优化的函数,一般来说是经验风险+结构风险,也就是代价函数+正则项
个人网站: 文艺与Code | Thinkgamer的博客
CSDN博客: Thinkgamer技术专栏
知乎: Thinkgamer
微博: Thinkgamer的微博
GitHub: Thinkgamer的GitHub
微信公众号: 数据与算法联盟(DataAndAlgorithm)
{kind=link}
