大家好,我是微学AI,今天给大家介绍一下,自然语言处理实战项目18-NLP模型训练中的Logits与损失函数的计算应用项目,在NLP模型训练中,Logits常用于计算损失函数并进行优化。损失函数的计算是用来衡量模型预测结果与真实标签之间的差异,从而指导模型参数的更新。
Logits是模型在分类任务中的输出,在经过Softmax函数后可以获得类别的概率分布。通过将Logits输入到交叉熵损失函数中,可以计算模型的预测结果与真实标签之间的差距,进而衡量模型的性能。
目录
1 引言
在自然语言处理(NLP)领域,模型训练是一个重要的环节。在模型训练过程中,我们需要了解并掌握一些关键概念,例如Logits和损失函数。这两个概念对于理解和优化模型性能至关重要。
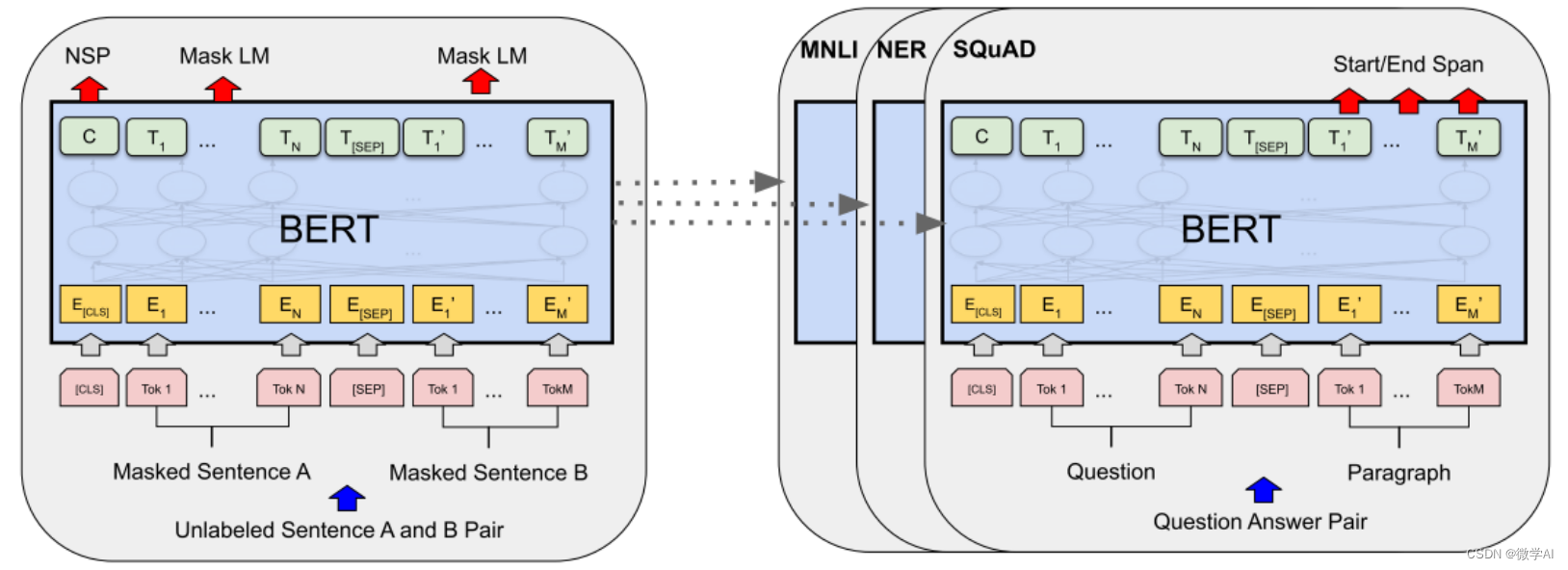
2 理解Logits
Logits通常是指通过神经网络最后一层线性变换(但未进行softmax或sigmoid等归一化操作)得到的原始预测值。比如我们使用BERT等模型做下