版权声明:若需要转载,请标明原文地址。 https://blog.csdn.net/qq_41903671/article/details/83047219
一,基本运算
1,单链表,双链表的定义:

设计链式存储结构时,每个逻辑节点存储单独存储。
2,单链表的基本结构:

头节点在前,首节点在后。
3,顺序表与链表间存储密度的差异:

顺序表的存储密度为1,而链表的存储密度小于1。
4,
typedef struct LNode
{
ElemType data; //存放元素值
struct LNode *next; //指向后继节点
}LinkNode //单链表节点类型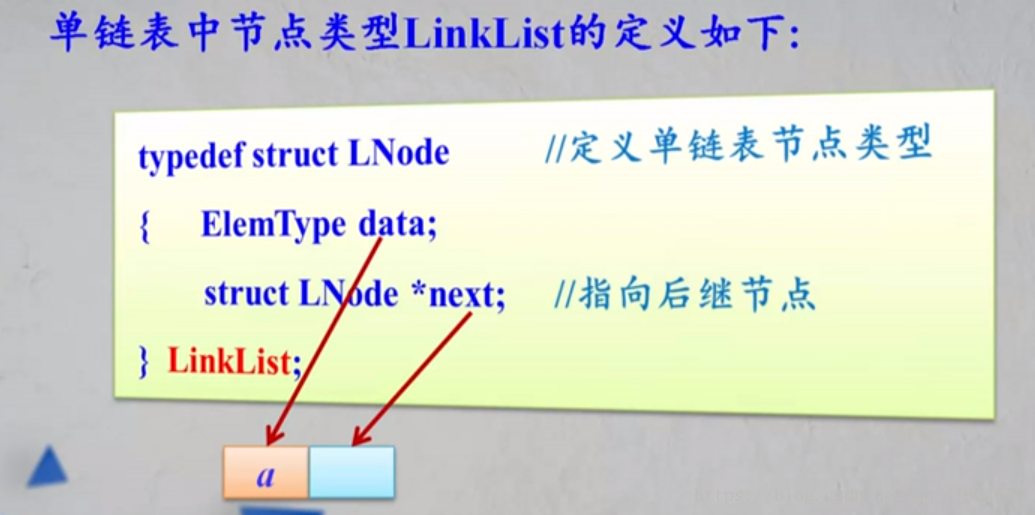
一个是数据域部分,一个是指向后继节点的指针域。
5,特点:

6,插入节点:
s→next=p→next
p→next=s
p指针指向一个节点。
如图7所示,删除节点:
p→next=p→next→next
二,基本算法
如图1所示,头插法建表

void CreatListF(LinkNode *&L,ElemType a[],int n)
{
LinkNode *s;
L=(LinkNode *)malloc(sizeof(LinkNode));
L→next=NULL; //创建头节点,其next域置为NULL
for(int i=0;i<n;i++) //循环建立数据节点s
{
s=(LinkNode *)malloc(sizeof(LinkNode));
s→data=a[i]; //创建数据节点s
s→next=L→next; //将s插入到原首节点之前、头节点之后
L→next=s;
}
}这个算法的时间复杂度为O(N)。
链表的节点顺序和逻辑顺序正好相反。
2,尾插法建表
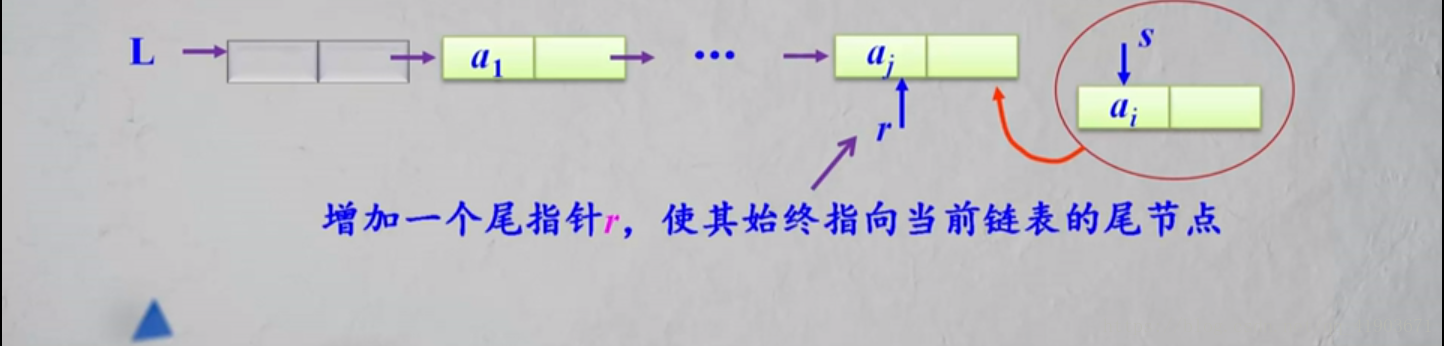
void CreateListR(ListNode *&L,ElemType a[],int n)
{
LinkNode *s,*r;
L=(LinkNode *)malloc(sizeof(LinkNode)); //创建头结点
r=L; //r始终指向尾结点,初始时指向头结点
for(int i=0;i<n;i++) //循环建立数据结点
{
s=(LinkNode *)malloc(sizeof(LinkNode));
s→data=a[i]; //创建数据结点s
r→next=s;
r=s;
}
r→next=NULL; //尾结点的next域置为空
}
链表的节点顺序与逻辑次序正好相同。
三,线性表基本运算在单链表中的实现
1,初始化线性表InitList(&L)
即创建一个头结点并将其未来域置空。
void InitList(LinkNode *&L)
{
L=(LinkNode *)malloc(sizeof(LinkNode));
L→next=NULL; //创建头结点,其next域置为NULL
}本算法的时间复杂度为O(1)。
2,销毁线性表DestroyList(&L)
该运算释放单链表大号占用的内存空间,即逐一释放全部结点的空间。其过程是让预,对指向两个相邻的结点(初始时预指向头结点,对指向首节点)。当p不为空时循环:释放结点预,然后预,对同步后移一个结点循环结束后,预指向尾结点,再将其释放。
void DestroyList(LinkNode * &L)
{
LinkNode *pre=L,*p=L→next; //pre指向结点p的前驱结点
while(p!=NULL) //扫描单链表L
{
free(pre); //释放pre结点
pre=p; //pre、p同步后移一个结点
p=pre→next;
}
free(pre); //循环结束时p为NULL,pre指向尾结点,释放它
}
本算法的时间复杂度为O(N),其中Ñ为单链表中数据结点的个数。
3,判断线性表是否为空表ListEmpty(L)
bool ListEmpty(LinkNode *L)
{
return(L→next==NULL);
}本算法的时间复杂度为O(1)。
4,求线性表的长度ListLength(L)
该运算返回单链表大号中数据结点的个数。
int ListLength(LinkNode *L)
{
int n=0;
LinkNode *p=L; //p指向头结点,n置为0(即头结点的序号为0)
while(p→next!=NULL)
{
n++;
p=p→next;
}
return(n); //循环结束时,p指向尾结点,其序号n为结点个数
}本算法的时间复杂度为O(N),其中Ñ为单链表中数据结点的个数。
5,输出单链表DidpList(L)
该算法逐一扫描单链表大号的每个数据结点,并显示各结点的数据域值。
void DispList(LinkNode *L)
{
LinkNode *p=L→next; //p指向首节点
while(p!=NULL) //当p不为NULL时,输出p结点的data域
{
printf("%d",p→data);
p=p→next; //p移向下一个结点
}
printf("\n");
}本算法的时间复杂度为O(N),其中Ñ为单链表中数据结点的个数。