在前面SVM一文中,我们解得的支持向量机在原始空间中是对训练数据能精确划分的如下图所示。可想而知,有大概率会出现过拟合的问题。这样的支持向量机的泛化能力较差。
 因此我们需要一种方式修改支持向量机,允许一些训练数据点被误分类,从而获得一个更好的泛化能力。我们允许数据点在边缘边界的错误侧,同时增加一个惩罚项,这个惩罚项随着与决策边界的距离的增大而增大。我们令这个惩罚项是距离的线性函数,为了实现它我们引入了松弛变量
ξn≥0,这样每个训练数据点都有一个松弛变量。对于位于正确的边缘边界内部的点或者边界上的点
ξn=0。对于其他的点,
ξn=∣tn−y(xn)∣。因此对于位于决策边界
y(xn)=0上的点,
ξn=1,并且
ξn>1就是被误分类的点,所以被精确分类的点满足
tny(xn)≥1−ξn,n=1,...,N
因此我们需要一种方式修改支持向量机,允许一些训练数据点被误分类,从而获得一个更好的泛化能力。我们允许数据点在边缘边界的错误侧,同时增加一个惩罚项,这个惩罚项随着与决策边界的距离的增大而增大。我们令这个惩罚项是距离的线性函数,为了实现它我们引入了松弛变量
ξn≥0,这样每个训练数据点都有一个松弛变量。对于位于正确的边缘边界内部的点或者边界上的点
ξn=0。对于其他的点,
ξn=∣tn−y(xn)∣。因此对于位于决策边界
y(xn)=0上的点,
ξn=1,并且
ξn>1就是被误分类的点,所以被精确分类的点满足
tny(xn)≥1−ξn,n=1,...,N
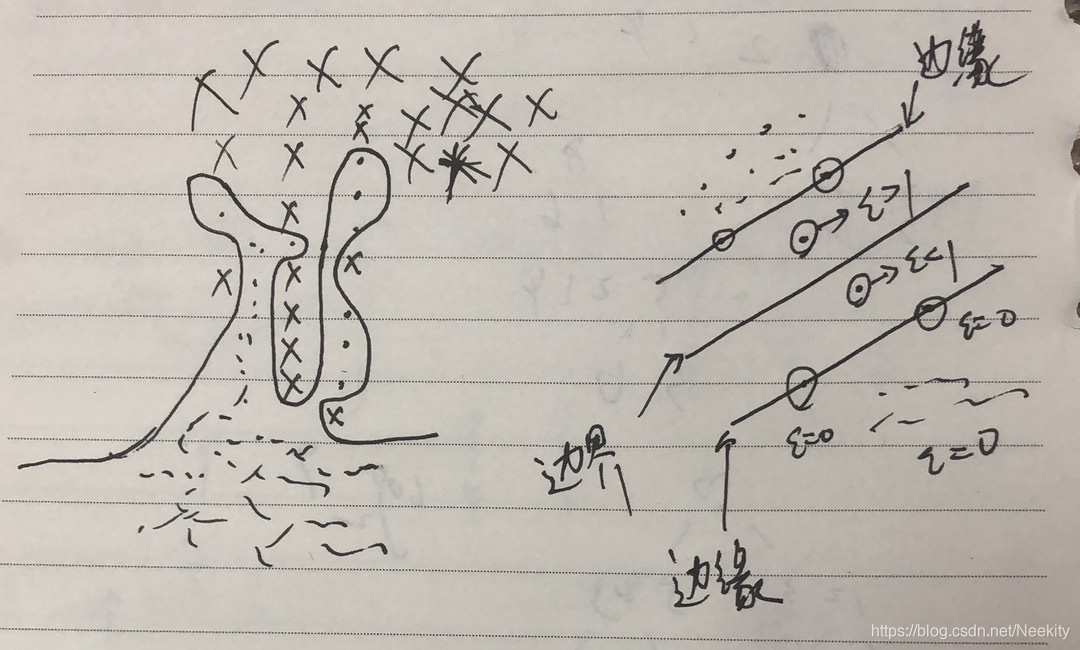
从上图中我们可以看到
ξn=0的数据点被正确分类,要么位于边缘上,要么在边缘正确的一侧。
0<ξn<=1的数据点位于边缘内部,但还是在决策边界的正确一侧。
ξn>1的数据点位于决策边界的错误一侧,是被错误分类的点。
所以这种方法有时被描述成放宽边缘的硬限制,得到一个软边缘,并且能允许一些训练数据点被错分。同时这种方法对异常点很敏感,因为误分类的惩罚随着
ξ线性增加。最终我们得到这样一个误差函数
Cn=1∑Nξn+21∣∣w∣∣2其中参数
C≥0控制了松弛变量惩罚与边缘之间的折中。由于任何被误分类的数据点都有
ξn>1,因此
∑nξn是误分类数据点数量的上界。于是参数C类似于正则化系数,它控制了最小化训练误差与模型复杂度的折中。当C趋向于无穷大时,就是线性可分数据的SVM。与之前的求法类似,我们先写出对应的拉格朗日函数
L(w,b,ξ,a,u)=21∣∣w∣∣2+Cn=1∑Nξn−n=1∑Nan{tny(xn)−1+ξn}−n=1∑Nunξn对应的KKT条件如下
an≥0
tny(xn)−1+ξn≥0
an(tny(xn)−1+ξn)=0
un≥0
ξn≥0
unξn=0对拉格朗日函数进行最优化
∂w∂L=0⇒w=n=1∑Nantnϕ(xn)
∂b∂L=0⇒0=n=1∑Nantn
∂ξ∂L=0⇒an=C−un把这些结果代入得到
L(a)=n=1∑Nan−21n=1∑Nm=1∑NanamtntmK(xn,xm)与硬判决相同,但限制条件有差异
0≤an≤C
n=1∑Nantn=0至此我们已经得到了
w,接下来求出
b,与之前相同考虑KKT条件。我们要找到满足
ξn=0即
tny(xn)=1的点
an>0,ξn=0,unξn=0⇒an>0,un>0⇒an>0,an=C−un<C⇒0<an<C然后与之前的计算一样
b=NM1n∈M∑{tn−m∈S∑amtmK(xn,xm)}此时M表示满足
0<an<C的数据点的下标集合