简介
机器人要对目标物体进行操作的时候,比如机器人从冰箱里拿出可乐。那么在传统方法中,一般是需要进行环境感知,机器人知道周围环境以及它目前所处的位置,位姿,以及目标的位置,接着进行路径规划,然后是决策控制。当然,中间还有landmark建模等等,可以看出为了解决这一系列的问题,需要进行较多的步骤。Feifei Li她们组就弄了一个end-to-end的方法,直接从输入当前图片以及目标图片,进行学习,输出不同场景下的action~ 选择概率最大的场景执行。所以通过这种凭感觉走的DRL的方式,就可以像人一样找到目标。
在这篇论文中,主要是两个贡献,一个是泛化性能,一个是3D模拟器。泛化能力指的是在不同的场景中,都能找到目标。以及在同一个场景中,可以找到不同的目标。3D模拟器就是对真实世界的模拟,这样可以训练得更快。这个模拟器对于以前的模拟器它有有点,主要是实时交互性以及它的真实性,比如点击冰箱就可以打开,用的是Unity3D做的。叫做AI2-THOR模型。可以使用Python API让agent与引擎进行交互。
DRL深度强化学习,深度学习和强化学习的结合体。前一部分是深度学习提取特征的部分,后面的loss function用的就是Q function。之前的DRL的方法比如AlphaGo使用的是转有的target模型,面对棋局的变化就要重新训练过。
细节
问题
从输入当前状态的图片和目标图片,通过DRL网络后,输出3D的action。所以是一个2D到3D空间的变化。之前训练网络,目标参数都是死的,比如AlphaGo的规则,如何判断是赢。然后规则改变的话,那么整个网络参数就要重新进行训练。整个的policy就是
learning setup
在这里采用的是离散空间进行计算award,这样更加坚简单,如果是连续的,就改成贝叶斯概率。使用meshigrid描述地图,看(probalistic robot)。
action space:前后左右。
observation:输入两幅图片。
reward design:将路径长度加入约束条件。对immediate reward加入penalty。
model: a~
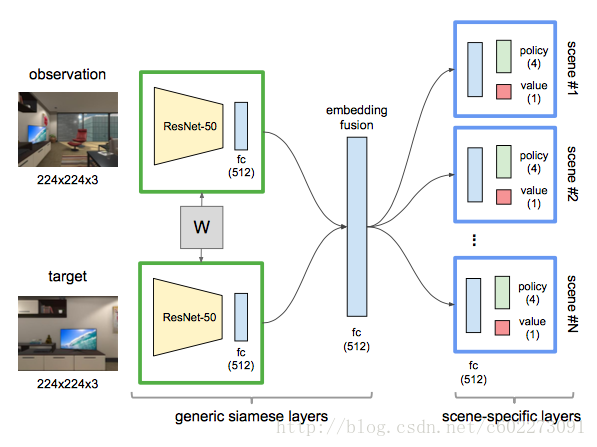
在inference的时候,输入是两幅图片,observation和target,接着分别输入到了共享权值的ResNet-50中,接着得到512 dim的vector,连接在一起,就是1024 dim,所以generic siamese layers生成的就是1024 dim的vector,这个vector与weight matrix 1024x512,得到embedding fusion的512 dim。然后这个embedding vector进入到不同的scene,并且512的vector再次与512x512的weight matrix相乘得到新的scene vector(这是猜想,每一个scene都专门训练了一个scene weight matrix)经过最后的Q function得到四个action的概率和一个value,这个value的值可以理解为不同scene的概率分布(猜想,文中这部分的细节给的不算多)。这里Q learning采用的就是actor-critic model(这个我可能要花一个寒假来搞明白这到底是啥,以及这里的RMSProp Optimizer又是什么)
训练的时候,为了加快速度,采用Google的A3C算法进行更新权值,每个target运行训练的时候都可以用初始一样的权值,跑完一以后,后向更新的时候一起更新就可以了。训练的数据其实论文中讲得不清楚,只有一句保存的4帧,获取了它的motion,我猜想这里应该是有一个完整的视频序列,从获取目标到找到目标的一个最短路径,然后输入就是当前帧和目标,输入的label就是4帧的motion(如果是离散的就是用前后左右来表示,这样更方便,直观,也不容易标错)。
文章中对不同场景中同一个target,不同的target在一个场景中,连续的map,以及将仿真环境中的数据进行fune-tuning用到真是机器人上做了实验。
来自于: http://blog.csdn.net/c602273091/article/details/78817808