版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012507347/article/details/52327218
KMP字符串匹配算法的本质呢就是分析子串自身的特点来优化算法。
第一个特点 前缀与后缀
来自《算法导论》的一个实例
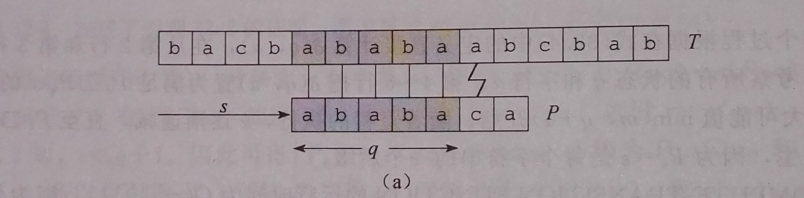
图a
文本 T , 与子串 P,已经匹配成功的q=5个字符,现在第六个字符匹配失败,要将子串P向前移动即 s 变大。s+1 的移动 显然失败,s+2的移动如下
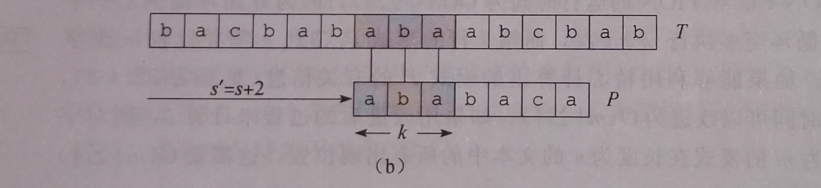
图b
能成功匹配到k=3个字符,现在分析这两次匹配到的内容
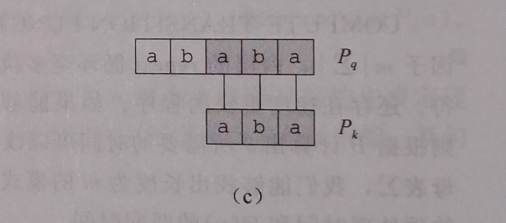
图c
可以看出Pk 与 Pq的后三个字符相匹配, 而Pk其实就是Pq的前三个字符,
换句话说就是 Pq的 前三个字符与后三个字符相同。
‘aba’既是Pq的前缀也是Pq的后缀, 符合这种特征的还有’a’ 其中’aba’是最长的
我们用
完整的P的前缀函数如下
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| P[i] | a | b | a | b | a | c | a |
|
|
0 | 0 | 1 | 2 | 3 | 0 | 1 |
使用这个函数我们可以得到KMP算法中的重要数组next
next数组的意义为:为当第子串中i个字符匹配失败时,要从子串的第next[i]个字符继续比较。
分析上一个例子
- 在第 6 个字符第一次匹配失败 i= 6
- 我们现在知道 P 的第 5 个字符的
π[i−1] = 3 - 所以我们应该向前移动
q−π[i−1] = 2 个字符 - 即与第
π[i−1]+1=3 比较
得
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| P[i] | a | b | a | b | a | c | a |
|
|
0 | 0 | 1 | 2 | 3 | 0 | 1 |
| next[i] | 0 | 1 | 1 | 2 | 3 | 4 | 1 |
第二个特点 nextval
如果用上例的P与下面一个文本匹配
T = a b a b c a a a..
p = a b a b a c a
- 第5个字符匹配失’a’,按照next函数 应与第 next[5] = 3个字符比较
- 发现p[3] = ‘a’ , 仍然失配,继续next[3] = 1
- 再一次p[1] = ‘a’ 最终 next[1] = 0
上面的过程发现连续的’a’造成这几步无用的操作,其实这一点我们可以提前预见到并避免。
当我们在p[q] 上失配时我们下一个匹配的是 p[next[q]] , 如果出现上述情况即
p[ q ] == p[ next[ q ] ] 则匹配一定失败 所以会直接匹配 p[next[ next[q] ]]
于是我们制定一个新的数组nextval
则
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| P[i] | a | b | a | b | a | c | a |
|
|
0 | 0 | 1 | 2 | 3 | 0 | 1 |
| next[i] | 0 | 1 | 1 | 2 | 3 | 4 | 1 |
| nextval[i] | 0 | 1 | 0 | 1 | 0 | 4 | 0 |