一,介绍
Python 中的机器学习库
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在 NumPy,SciPy 和 matplotlib 上
- 开放源码,可商业使用 - BSD license

二,线性回归算法模型
2个概念
样本集:用于对机器学习算法模型对象进行训练。样本集通常为一个DataFrame。
- 特征数据:特征数据的变化会影响目标数据的变化。必须为多列。
- 目标数据:结果。通常为一列1,建立线性回归算法模型对象
from sklearn.linear_model import LinearRegression linear = LinearRegression() # 实例化 线性回归算法模型对象
2,使用样本数据对模型进行训练
数据: near_citys_dist: array([47, 8, 71, 14, 37], dtype=int64) # 城市距离海边的最远距离 near_citys_max_temp: array([32.75, 32.79, 33.85, 32.81, 32.74]) # 城市的最高温度 # 使用这两组数据预测 城市温度与距离海边距离的关系 linear.fit(near_citys_dist.reshape(-1,1),near_citys_max_temp) # 注意特征数据必须时多列,所以把array转化为多列的
返回值: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
3,对模型进行精准度的评分
linear.score(near_citys_dist.reshape(-1,1),near_citys_max_temp) # 0.5549063263099332
4,使用模型进行预测
x = np.array([65,44,12,99]).reshape(-1,1) # 给定一组特征数据
y = linear.predict(x) # 预测其值
# array([ 33.40442982, 33.10898974, 32.65879535, 33.88276137])
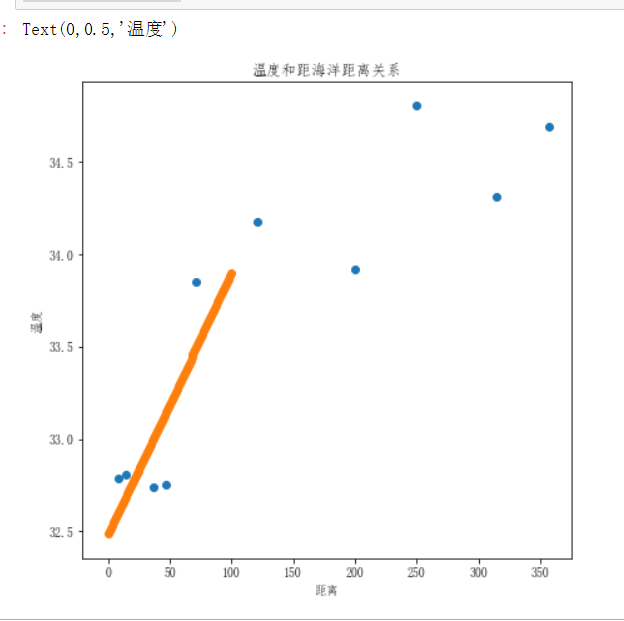
#绘制回归曲线
x = np.linspace(0,100,num=100) # 给定一组特征数据
y = linear.predict(x.reshape(-1,1)) # 预测其值
plt.figure(figsize=(7,7))
plt.scatter(citys_dist,citys_max_temp)
plt.scatter(x,y)
plt.title('温度和距海洋距离关系')
plt.xlabel('距离')
plt.ylabel('温度')