1,CNN的原理是什么?作用是什么?什么是池化?
2,CNN的模型有哪些?
LeNet5、AlexNet 、VGG、GoogleNet、ResNets
3,朴素贝叶斯公式
2,自然语言处理:HMM等算法?
3,hadoop 和 spark 是什么?Yarn是什么?
4,传统数据库、redis、hbase、hive区别?
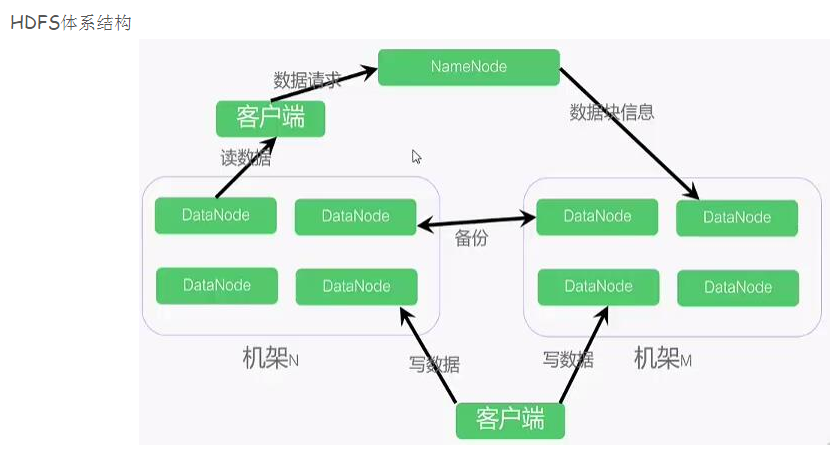
5,hdfs是什么?hdfs由几大模块组成?每个模块的作用?默认保存几份数据?datanode是什么?如果有3个datanode,其中一个损坏,会有什么后果?
HDFS主要是一个分布式的文件存储系统,由namenode来接收用户的操作请求,然后根据文件大小,以及定义的block块的大小,将大的文件切分成多个block块来进行保存。
在HDFS中,文件的读写过程就是client和NameNode以及DataNode一起交互的过程。我们已经知道NameNode管理着文件系统的元数据,DataNode存储的是实际的数据,那么client就会联系NameNode以获取文件的元数据,而真正的文件读取操作是直接和DataNode进行交互的。
参考链接:
http://www.2cto.com/database/201412/357371.html

6,数据倾斜的原因?如何处理?
使用mapreduce处理数据倾斜?
map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
可以进行二次排序。(。。。。。。。。)
7,如何改变linux打开的最大文件数?
8,你做的项目的分类器是什么?
9,两千个已标注的样本,两亿个未分类的样本,如何分类?
10,聚类有哪些算法?
11,4g内存的计算机,20亿的数据找出不重复的整数?
12,python如何打开csv文件
13,mysql如何删除一行?一列?如何加入两个属性(字段)?
14,特征选择有哪些方法?
常用的六种特征选择方法:
1)DF(Document Frequency) 文档频率
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性
2)MI(Mutual Information) 互信息法
互信息法用于衡量特征词与文档类别直接的信息量。
如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。
相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3)(Information Gain) 信息增益法
通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
4)CHI(Chi-square) 卡方检验法
利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的
如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。
5)WLLR(Weighted Log Likelihood Ration)加权对数似然
6)WFO(Weighted Frequency and Odds)加权频率和可能性
http://blog.csdn.net/ztf312/article/details/50890099
15,什么是梯度消失和梯度膨胀?如何解决?
16,map-reduce过程?
16.1 hadoop的shuffle过程
16.1.1 Map端的shuffle:
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目的是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
16.1.2 Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也成为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
16.2 MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
1)一个 MapReduce 作业由 Map 阶段和 Reduce 阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce 框架本质就是一个 Distributed Sort。
2)在 Map 阶段,Map Task 会在本地磁盘输出一个按照 key 排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在 Reduce 阶段,每个 Reduce Task 会对收到的数据排序,这样,数据便按照 Key 分成了若干组,之后以组为单位交给 reduce()处理。
3)很多人的误解在 Map 阶段,如果不使用 Combiner便不会排序,这是错误的,不管你用不用 Combiner,Map Task 均会对产生的数据排序(如果没有 Reduce Task,则不会排序,实际上 Map 阶段的排序就是为了减轻 Reduce端排序负载)。
4)由于这些排序是 MapReduce 自动完成的,用户无法控制,因此,在hadoop 1.x 中无法避免,也不可以关闭,但 hadoop2.x 是可以关闭的。