TF-IDF介绍(维基百科):
tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF原理:
TF:
词频(term frequency,tf)指的是某一个给定的词语在该文件中出现的频率.
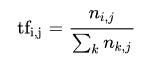
IDF:
逆向文件频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到:
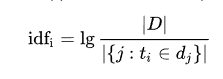
其中:

不过我们常常对IDF 进行处理:
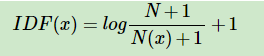
其中N代表语料库中文本的总数(样本数),而N(x)代表语料库中有多少文本包含词x。 至于图片中分子分母包括取对数后加的1都是为了使IDF平滑。
所以: TF-IDF = TF * IDF
文本挖掘预处理
首先我们准备了两段文本,这两段文本在两个文件中。两段文本的内容分别是nlp_test0.txt和nlp_test2.txt:
nlp_test0.txt:
沙瑞金赞叹易学习的胸怀,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。
nlp_test2.txt:
沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。
代码如下:
import jieba
with open('./nlp_test0.txt', 'r') as f:
document = f.read()
# 分词
document_cut = jieba.cut(document)
result = ('/'.join(document_cut) ) # 如果打印结果,则分词效果消失,后面的result无法显示
print(result)
with open('./nlp_test1.txt', 'w') as f2:
f2.write(result)
结果:
沙/瑞金/赞叹/易/学习/的/胸怀/,/是/金山/的/百姓/有福/,/可是/这件/事对/李达康/的/触动/很大/。/易/学习/又/回忆起/他们/三人/分开/的/前一晚/,/大家/一起/喝酒/话别/,/易/学习/被/降职/到/道口/县当/县长/,/王/大路/下海经商/,/李达康/连连/赔礼道歉/,/觉得/对不起/大家/,/他/最/对不起/的/是/王/大路/,/就/和/易/学习/一起/给/王/大路/凑/了/5/万块/钱/,/王/大路/自己/东挪西撮/了/5/万块/,/开始/下海经商/。/没想到/后来/王/大路/竟然/做/得/风生水/起/。/沙/瑞金/觉得/他们/三人/,/在/困难/时期/还/能/以沫/相助/,/很/不/容易/。
我们发现有些名字不能识别,如沙瑞金、易学习等,原因是jieba 里边没有这样的名词,
所以,使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
jieba.suggest_freq('沙瑞金', True)
jieba.suggest_freq('易学习', True)
jieba.suggest_freq('王大路', True)
jieba.suggest_freq('风生水起', True)
之后,我们再看看结果如何:
with open('./nlp_test0.txt', 'r') as f:
document = f.read()
# 分词
document_cut = jieba.cut(document)
result = ('/'.join(document_cut) )
print(result)
with open('./nlp_test1.txt', 'w') as f2: # 将nlp_test0.txt保存在nlp_test1.txt中
f2.write(result)
结果:
沙瑞金/赞叹/易学习/的/胸怀/,/是/金山/的/百姓/有福/,/可是/这件/事对/李达康/的/触动/很大/。/易学习/又/回忆起/他们/三人/分开/的/前一晚/,/大家/一起/喝酒/话别/,/易学习/被/降职/到/道口/县当/县长/,/王大路/下海经商/,/李达康/连连/赔礼道歉/,/觉得/对不起/大家/,/他/最/对不起/的/是/王大路/,/就/和/易学习/一起/给/王大路/凑/了/5/万块/钱/,/王大路/自己/东挪西撮/了/5/万块/,/开始/下海经商/。/没想到/后来/王大路/竟然/做/得/风生水起/。/沙瑞金/觉得/他们/三人/,/在/困难/时期/还/能/以沫/相助/,/很/不/容易/。
with open('nlp_test2.txt', 'r') as f:
document = f.read()
result = '/'.join(jieba.cut(document))
print(result)
with open('nlp_test3.txt', 'w') as f3: # 将nlp_test2.txt保存在nlp_test3.txt中
f3.write(result)
引入停用词:
点击这里下载停用词文本以stopwords.txt命名:
with open('stopwords.txt', 'r') as f:
stopwordslist = f.read().splitlines() # 读取为列表
TF-IDF特征处理:
# 先加载刚才已经处理好的文本信息
with open('nlp_test1.txt', 'r') as f1:
res1 = f1.read()
print(res1)
with open('nlp_test3.txt', 'r') as f3:
res3 = f3.read()
print(res3)
结果:
沙瑞金/赞叹/易学习/的/胸怀/,/是/金山/的/百姓/有福/,/可是/这件/事对/李达康/的/触动/很大/。/易学习/又/回忆起/他们/三人/分开/的/前一晚/,/大家/一起/喝酒/话别/,/易学习/被/降职/到/道口/县当/县长/,/王大路/下海经商/,/李达康/连连/赔礼道歉/,/觉得/对不起/大家/,/他/最/对不起/的/是/王大路/,/就/和/易学习/一起/给/王大路/凑/了/5/万块/钱/,/王大路/自己/东挪西撮/了/5/万块/,/开始/下海经商/。/没想到/后来/王大路/竟然/做/得/风生水起/。/沙瑞金/觉得/他们/三人/,/在/困难/时期/还/能/以沫/相助/,/很/不/容易/。
沙瑞金/向/毛娅/打听/他们/家/在/京州/的/别墅/,/毛娅/笑/着/说/,/王大路/事业有成/之后/,/要/给/欧阳菁/和/她/公司/的/股权/,/她们/没有/要/,/王大路/就/在/京州帝/豪园/买/了/三套/别墅/,/可是/李达康/和/易学习/都/不要/,/这些/房子/都/在/王大路/的/名下/,/欧阳菁/好像/去/住/过/,/毛娅/不想/去/,/她/觉得/房子/太大/很/浪费/,/自己/家住/得/就/很/踏实/。
tf-idf处理
from sklearn.feature_extraction.text import TfidfVectorizer
vector = TfidfVectorizer(stop_words=stopwordslist)
corpus = [res1, res3]
tfidf = vector.fit_transform(corpus) # 进行tf-idf处理
print(tfidf)
结果:
这里只截取部分结果
最左边代表文本,中间代表词的id,最右代表tf-idf的权重
(0, 34) 0.17410143090216304
(0, 46) 0.12234674320234734
(0, 29) 0.3482028618043261
(0, 41) 0.12234674320234734
(0, 50) 0.12234674320234734
(0, 38) 0.12234674320234734
(0, 30) 0.12234674320234734
: :
(1, 21) 0.15416589591902946
(1, 36) 0.15416589591902946
(1, 23) 0.15416589591902946
(1, 47) 0.15416589591902946
获取信息
wordlist = vector.get_feature_names() # 获取词袋模型中的所有词
print(wordlist)
# tf-idf矩阵 元素a[i][j]表示j词在i类文本中的tf-idf权重
weightlist = tfidf.toarray() # IFIDF词频矩阵
print(weightlist)
#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weightlist)):
print("-------第", i, "段文本的词语tf-idf权重------" )
for j in range(len(wordlist)):
print(wordlist[j], weightlist[i][j])
结果:
['万块', '三人', '三套', '下海经商', '不想', '东挪西撮', '事业有成', '事对', '京州', '京州帝', '以沫', '公司', '分开', '别墅', '前一晚', '县当', '县长', '名下', '喝酒', '回忆起', '困难', '太大', '好像', '家住', '对不起', '很大', '房子', '打听', '时期', '易学习', '有福', '李达康', '欧阳菁', '毛娅', '沙瑞金', '没想到', '浪费', '王大路', '百姓', '相助', '股权', '胸怀', '触动', '话别', '豪园', '赔礼道歉', '赞叹', '踏实', '这件', '道口', '金山', '降职', '风生水起']
[[0.24469349 0.24469349 0. 0.24469349 0. 0.12234674
0. 0.12234674 0. 0. 0.12234674 0.
0.12234674 0. 0.12234674 0.12234674 0.12234674 0.
0.12234674 0.12234674 0.12234674 0. 0. 0.
0.24469349 0.12234674 0. 0. 0.12234674 0.34820286
0.12234674 0.17410143 0. 0. 0.17410143 0.12234674
0. 0.43525358 0.12234674 0.12234674 0. 0.12234674
0.12234674 0.12234674 0. 0.12234674 0.12234674 0.
0.12234674 0.12234674 0.12234674 0.12234674 0.12234674]
[0. 0. 0.1541659 0. 0.1541659 0.
0.1541659 0. 0.1541659 0.1541659 0. 0.1541659
0. 0.30833179 0. 0. 0. 0.1541659
0. 0. 0. 0.1541659 0.1541659 0.1541659
0. 0. 0.30833179 0.1541659 0. 0.1096903
0. 0.1096903 0.30833179 0.46249769 0.1096903 0.
0.1541659 0.32907091 0. 0. 0.1541659 0.
0. 0. 0.1541659 0. 0. 0.1541659
0. 0. 0. 0. 0. ]]
-------第 0 段文本的词语tf-idf权重------
万块 0.24469348640469468
三人 0.24469348640469468
三套 0.0
下海经商 0.24469348640469468
不想 0.0
东挪西撮 0.12234674320234734
事业有成 0.0
事对 0.12234674320234734
京州 0.0
京州帝 0.0
以沫 0.12234674320234734
公司 0.0
分开 0.12234674320234734
别墅 0.0
前一晚 0.12234674320234734
县当 0.12234674320234734
县长 0.12234674320234734
名下 0.0
喝酒 0.12234674320234734
回忆起 0.12234674320234734
困难 0.12234674320234734
太大 0.0
好像 0.0
家住 0.0
对不起 0.24469348640469468
很大 0.12234674320234734
房子 0.0
打听 0.0
时期 0.12234674320234734
易学习 0.3482028618043261
有福 0.12234674320234734
李达康 0.17410143090216304
欧阳菁 0.0
毛娅 0.0
沙瑞金 0.17410143090216304
没想到 0.12234674320234734
浪费 0.0
王大路 0.4352535772554076
百姓 0.12234674320234734
相助 0.12234674320234734
股权 0.0
胸怀 0.12234674320234734
触动 0.12234674320234734
话别 0.12234674320234734
豪园 0.0
赔礼道歉 0.12234674320234734
赞叹 0.12234674320234734
踏实 0.0
这件 0.12234674320234734
道口 0.12234674320234734
金山 0.12234674320234734
降职 0.12234674320234734
风生水起 0.12234674320234734
-------第 1 段文本的词语tf-idf权重------
万块 0.0
三人 0.0
三套 0.15416589591902946
下海经商 0.0
不想 0.15416589591902946
东挪西撮 0.0
事业有成 0.15416589591902946
事对 0.0
京州 0.15416589591902946
京州帝 0.15416589591902946
以沫 0.0
公司 0.15416589591902946
分开 0.0
别墅 0.3083317918380589
前一晚 0.0
县当 0.0
县长 0.0
名下 0.15416589591902946
喝酒 0.0
回忆起 0.0
困难 0.0
太大 0.15416589591902946
好像 0.15416589591902946
家住 0.15416589591902946
对不起 0.0
很大 0.0
房子 0.3083317918380589
打听 0.15416589591902946
时期 0.0
易学习 0.10969030467540065
有福 0.0
李达康 0.10969030467540065
欧阳菁 0.3083317918380589
毛娅 0.4624976877570884
沙瑞金 0.10969030467540065
没想到 0.0
浪费 0.15416589591902946
王大路 0.3290709140262019
百姓 0.0
相助 0.0
股权 0.15416589591902946
胸怀 0.0
触动 0.0
话别 0.0
豪园 0.15416589591902946
赔礼道歉 0.0
赞叹 0.0
踏实 0.15416589591902946
这件 0.0
道口 0.0
金山 0.0
降职 0.0
风生水起 0.0
>>> print(vector.vocabulary_) # 打印每个词对应的ID
{'沙瑞金': 34, '赞叹': 46, '易学习': 29, '胸怀': 41, '金山': 50, '百姓': 38, '有福': 30, '这件': 48, '事对': 7, '李达康': 31, '触动': 42, '很大': 25, '回忆起': 19, '三人': 1, '分开': 12, '前一晚': 14, '喝酒': 18, '话别': 43, '降职': 51, '道口': 49, '县当': 15, '县长': 16, '王大路': 37, '下海经商': 3, '赔礼道歉': 45, '对不起': 24, '万块': 0, '东挪西撮': 5, '没想到': 35, '风生水起': 52, '困难': 20, '时期': 28, '以沫': 10, '相助': 39, '毛娅': 33, '打听': 27, '京州': 8, '别墅': 13, '事业有成': 6, '欧阳菁': 32, '公司': 11, '股权': 40, '京州帝': 9, '豪园': 44, '三套': 2, '房子': 26, '名下': 17, '好像': 22, '不想': 4, '太大': 21, '浪费': 36, '家住': 23, '踏实': 47}
或者按顺序排列:
d = vector.vocabulary_
print(sorted(d.items(), key=lambda item:item[1]))
结果:
[('万块', 0), ('三人', 1), ('三套', 2), ('下海经商', 3), ('不想', 4), ('东挪西撮', 5), ('事业有成', 6), ('事对', 7), ('京州', 8), ('京州帝', 9), ('以沫', 10), ('公司', 11), ('分开', 12), ('别墅', 13), ('前一晚', 14), ('县当', 15), ('县长', 16), ('名下', 17), ('喝酒', 18), ('回忆起', 19), ('困难', 20), ('太大', 21), ('好像', 22), ('家住', 23), ('对不起', 24), ('很大', 25), ('房子', 26), ('打听', 27), ('时期', 28), ('易学习', 29), ('有福', 30), ('李达康', 31), ('欧阳菁', 32), ('毛娅', 33), ('沙瑞金', 34), ('没想到', 35), ('浪费', 36), ('王大路', 37), ('百姓', 38), ('相助', 39), ('股权', 40), ('胸怀', 41), ('触动', 42), ('话别', 43), ('豪园', 44), ('赔礼道歉', 45), ('赞叹', 46), ('踏实', 47), ('这件', 48), ('道口', 49), ('金山', 50), ('降职', 51), ('风生水起', 52)]
详情可查阅:
https://www.cnblogs.com/pinard/p/6744056.html
互信息的原理
***互信息的定义:***在概率论和信息论中,两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度。不同于相关系数,互信息并不局限于实值随机变量,它更加一般且决定着联合分布 p(X,Y) 和分解的边缘分布的乘积 p(X)p(Y) 的相似程度。互信息是点间互信息(PMI)的期望值。互信息最常用的单位是bit.
正式地,两个离散随机变量 X 和 Y 的互信息可以定义为: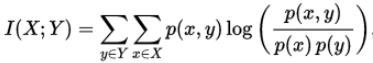
其中 p(x,y) 是 X 和 Y 的联合概率分布函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率分布函数.
在连续随机变量的情形下,求和被替换成了二重定积分:
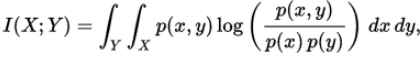
互信息量I(xi;yj)在联合概率空间P(XY)中的统计平均值。 平均互信息I(X;Y)克服了互信息量I(xi;yj)的随机性,成为一个确定的量。如果对数以 2 为基底,互信息的单位是bit。
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。(这种情形的一个非常特殊的情况是当 X 和 Y 为相同随机变量时。)
互信息是 X 和 Y 联合分布相对于假定 X 和 Y 独立情况下的联合分布之间的内在依赖性。于是互信息以下面方式度量依赖性:I(X; Y) = 0 当且仅当 X 和 Y 为独立随机变量。从一个方向很容易看出:当 X 和 Y 独立时,p(x,y) = p(x) p(y),因此:
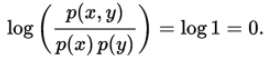
平均互信息量的物理含义
(1)观察者站在输出端
H(X/Y) —信道疑义度/损失熵.。Y关于X的后验不确定度。表示收到变量Y后,对随机变量X仍然存在的不确定度。代表了在信道中损失的信息。
H(X) —X的先验不确定度/无条件熵。
I(X;Y)—收到Y前后关于X的不确定度减少的量。从Y获得的关于X的平均信息量。
(2)观察者站在输入端
H(Y/X)—噪声熵。表示发出随机变量X后, 对随机变量Y仍然存在的平均不确定度。如果信道中不存在任何噪声, 发送端和接收端必存在确定的对应关系, 发出X后必能确定对应的Y, 而现在不能完全确定对应的Y, 这显然是由信道噪声所引起的。
I(Y;X) —发出X前后关于Y的先验不确定度减少的量。
(3)观察者站在通信系统总体立场上
H(XY)—联合熵.表示输入随机变量X, 经信道传输到达信宿, 输出随机变量Y。即收,发双方通信后,整个系统仍然存在的不确定度.
I(X;Y) —通信前后整个系统不确定度减少量。在通信前把X和Y看成两个相互独立的随机变量, 整个系统的先验不确定度为X和Y的联合熵H(X)+H(Y); 通信后把信道两端出现X和Y看成是由信道的传递统计特性联系起来的, 具有一定统计关联关系的两个随机变量, 这时整个系统的后验不确定度由H(XY)描述。
以上三种不同的角度说明: 从一个事件获得另一个事件的平均互信息需要消除不确定度,一旦消除了不确定度,就获得了信息。
参考:http://www.cnblogs.com/gatherstars/p/6004075.html
点互信息(PMI,Pointwise Mutual Information)
机器学习相关文献里面,经常会用到PMI(Pointwise Mutual Information)这个指标来衡量两个事物之间的相关性(比如两个词)。其原理很简单,公式如下:
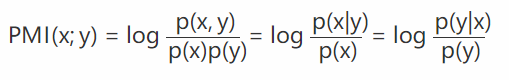
在概率论中,我们知道,如果x跟y不相关,则 p(x,y)=p(x)p(y) 。二者相关性越大,则 p(x,y) 就相比于 p(x)p(y) 越大。
例子
举个自然语言处理中的例子来说,我们想衡量like这个词的极性(正向情感还是负向情感)。我们可以预先挑选一些正向情感的词,比如good。然后我们算like跟good的PMI,即:
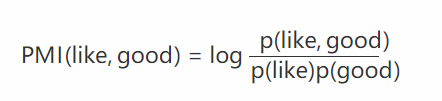
其中 p(like) 是like在语料库中出现的概率(出现次数除以总词数 N ), p(like,good) 表示like跟good在一句话中同时出现的概率(like跟good同时出现的次数除以 N2 )。
PMI(like,good) 越大表示like的正向情感倾向就越明显。
参考:
1、http://www.voidcn.com/article/p-xpzjpvoy-sr.html
2、https://blog.csdn.net/baimafujinji/article/details/6509820