PyTorch实战CNN文本分类
文章目录
项目解读
CNN原本用于图像任务,如何利用CNN进行文本分类任务?关键在于特征提取方式,进过上一节,我们知道LSTM利用了词嵌入模型,将词映射为一个300维的向量。这里我们也可以利用同样的方式,举例:先将一个字映射为5维向量,设卷积核大小为45(红色部分)或者35(绿色部分)或者2*5(黄色部分),颜色深浅为两个卷积核即两个初始化权重参数不同的卷积核。卷积核宽度越小得到的特征越多如图第二阶段长条所示。最大池化max-pooling提取特征点,进行拼接,再进行全连接进行分类。
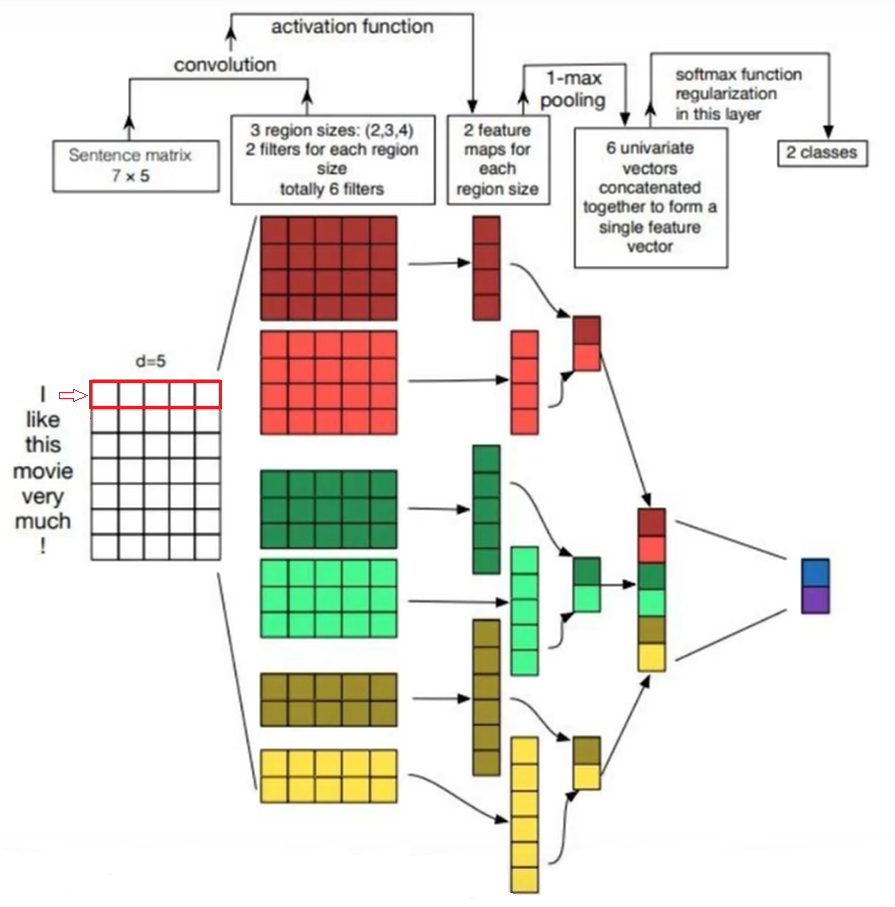
全部代码在上一节LSTM中,代码实现了LSTM模块和CNN模块,注意需要把model默认值改为TextCNN
项目地址:https://github.com/ljyljy/Text_classification_of_THUCNews
详细运行方式参照https://blog.csdn.net/qq_41605740/article/details/127396232
代码解读
我们主要分析model模块,进行Debug查看torch.Size
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
- embedding进行词嵌入,转为300维词向量
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
- 三层卷积写成ModuleList
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
- torch.Size([128,256,31])特征图向量大小即为上图第三部分长条形特征图,每次卷积只移动一步,卷积核宽度为2,所以卷积后特征为31
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
- torch.Size([128,256])将特征向量最大池化为一个特征值
def forward(self, x):
#print (x[0].shape)
out = self.embedding(x[0])
- torch.Size([128,32,300])还缺少一个颜色通道
out = out.unsqueeze(1)
- torch.Size([128,1,32,100])
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
- torch.Size([128,768]) 三种卷积拼接在一起256*3
out = self.fc(out)
return out