2.5 学习词嵌入
在构造语言模型里面:往往不是由一句话里面所有的词来预测下一个词,而是有一定的历史窗口(窗口的大小是一个超参数)
当窗口是4的时候:输入神经网络的向量大小是:4X300,
算法的参数是词嵌入矩阵,和隐层W,b,softmax的参数W,b
这个算法是让相似的词得到的词嵌入相似。词嵌入矩阵可以先初始化,算法想得到好的结果就需要不断地让相似的词的嵌入矩阵也相似。
如果要学习语言模型本身就可以选取目标词的上下文,如果要学习词嵌入可以用其他的上下文:
有三种方法选取上下文:前后n个词:
前一个词;
邻近词(并不是前一个词)
2.6 world2vc
分析句子做监督学习:在预料库里面选取一些词作为上下文,目标词在这些上下文的前后词距为10的这些单词里面
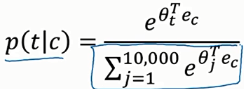
注意这个概率算出来是一个向量。
解决这个求和过大的问题(加速softmax的分类):使用一个分级的softmax滤波器
上下文的选取并不是随机的,而是采用某些方法来平衡常见词和非常见词
2.7 负采样