目录

一、为什么要有词嵌入?
文本是非结构化数据并且是不可计算的
向量是结构化数据并且是可计算的
二、one-hot编码:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]
缺点显而易见 真实情况文本出现的单词有成千上万个不同
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
三、什么是词嵌入(word embedding)
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,但他有更多的优点,比如通过词嵌入可以把高维的one-hot稀疏变为低维稠密
例子:(如下图所示:)
s=’我喜欢学习数学’ 使用词嵌入技术,将s中的每个词,都表示为一个128维的向量(这个维数是可以自定义的,只要能够保持与嵌入矩阵的维数是一致的)【为什么要设置维数】(目的是要捕捉词与词之间的关系)。
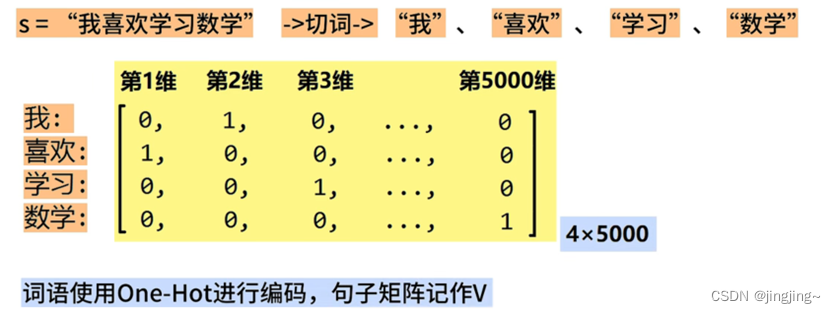
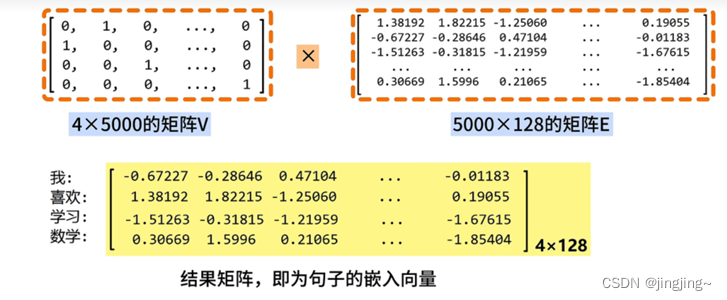
上图中的右边矩阵E即为嵌入矩阵。
1、什么是嵌入矩阵?
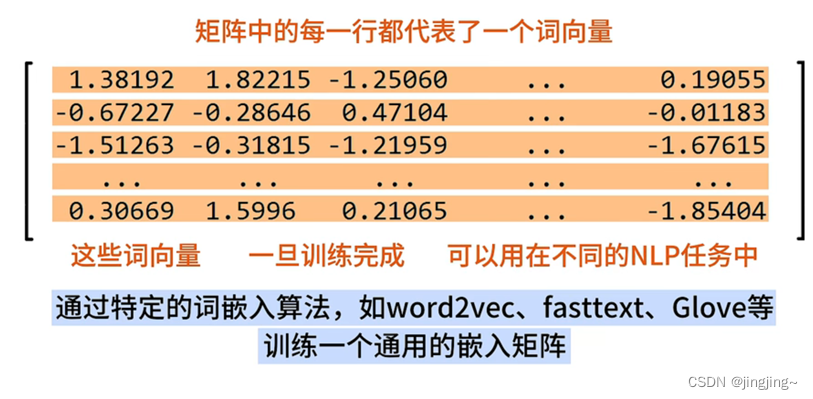
嵌入矩阵是通过特定的词嵌入算法,如word2vec、fasttext、Glove等训练得到一个通用的嵌入矩阵。(如下图所示)
2、为什么要设置维数?
设置维数是为了进一步说明词与词之间的关系(如下图左边表示)

通过降维算法不仅可表达相似性而且可通过计算得到数学关系 ,并绘制在二维平面上,可以发现语义相近的词语对应的位置也更相近。

上图说明,词嵌入向量不仅可以表达语义的相似性,而且可以通过向量的数学关系,描述词语之间的语义关联。
3、相比one-hot编码的优点
1、通过更低维的表达,表达效率得到提升。
2、可以理解词语的语义,并进行词语的推理,即语义相似的词在向量空间上也会更近。
3、嵌入矩阵是通用的,同一份词向量,可以用在不同的NLP任务中。
详细的视频参考:什么是词嵌入,Word Embedding算法_哔哩哔哩_bilibili
4、什么是word2vec和GLove?
Word2vec 和Glove都是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec有两种训练模式:CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model)
1、CBOW通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么
比如:

2、Skip-gram用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词
比如:

详细内容可参考:一文看懂 Word2vec(基本概念+2种训练模型+5个优缺点) (easyai.tech)
Glove算法详细可参考:GloVe详解 | 永远的热河路 (fanyeong.com)
四、图嵌入

将图嵌入到一个低维连续稠密的d维向量,上图中的d=6,这就是图嵌入。
1、词嵌入与图嵌入的相似性
词嵌入与图的随机游走是相似的,相邻的词之间是(相似的)存在一定关系,随机游走也是相邻的节点是相似的(可以预测中间的点)。(左图为节点,右图为词嵌入)

2、什么是随机游走
随机游走(deepWalk)就是在图中选取邻近的结点是完全随机的,其嵌入缺点,完全的随机游走,训练节点嵌入向量,只会把距离自己比较近的存在相似,而距离远但实际相似的是捕捉不到的。
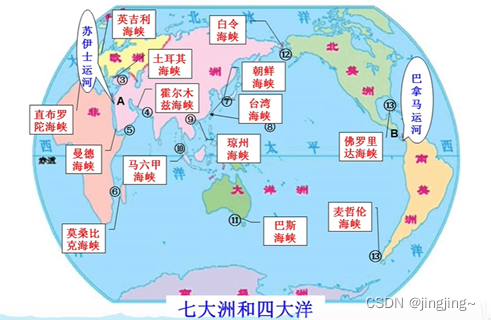
例如,下图苏伊士运河和巴拿马运河随机游走是做不到相似的。它只能找到周边的相似性。
DeepWalk缺点:
1、用完全随机游走,训练节点嵌入向量。
2、仅能反映相邻节点的社群相似信息。
3、无法反映节点的功能角色相似信息。
可参考的视频:Node2Vec【图神经网络论文精读】_哔哩哔哩_bilibili
3、Node2vec

node2vec相当于有偏的随机游走(可调节pq值)。(a乘权重有权图或者乘1无权图)
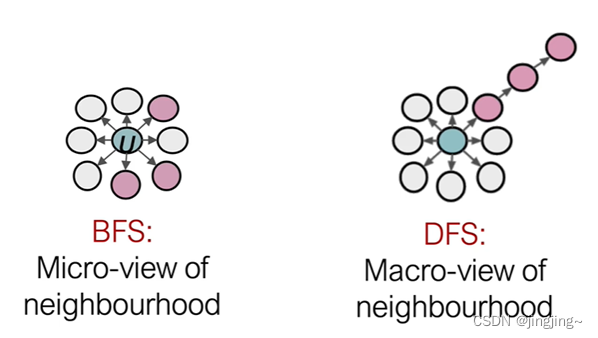
左图,如果把p调小相当于BFS(找周围相似),右图若把q调的小相当于DFS(找远处的相似),可以想象为DFS与BFS的一种结合。是一种二阶的随机游走,而不是deepWalk一阶的(相当于p=1,q=1的特例)。
4、总结
(Node2vec图嵌入算法)是无监督的和deepwalk(相当于把Word2vec用在图上)一样 :
1、Node2Vec解决图嵌入问题,将图中的每个节点映射为一个向量(嵌入)
2、向量(嵌入)包含了节点的语义信息(相邻社群和功能角色)。
3、语义相似的节点,向量(嵌入)的距离也近。
4、向量(嵌入)用于后续的分类、聚类、Link Prediction、推荐等任务。
1、在DeepWalk完全随机游走的基础上,Node2Vec增加p、_q参数,实现有偏随机游走。不同的p、q组合,对应了不同的探索范围和节点语义。
2、DFS深度优先探索,相邻的节点,向量(嵌入)距离相近。
3、BFS广度优先探索,相同功能角色的节点,向量(嵌入)距离相近。
4、DeepWalk是Node2Vec在p=1, q=1的特例。
LinkEmbedding
是两个点的连接,相当于将两个点进行融合到一起。