一、文件操作
1、打开关闭文件
- 在python中打开文件用open函数,open(文件名,访问模式)
| 访问模式 | 说明 |
|---|---|
| r | 以只读的方式打开,文件的指针将会放在文件的开头,默认形式 |
| w | 打开一个文件只用于写入,如果该文件已存在,则覆盖其中内容,如果不存在则新建文件 |
| a | 打开一个文件用于追加,如果文件存在,则指针位于文件的末尾,如果文件不存在,则新建文件 |
| rb | 以一个二进制形式打开一个文件,只读模式,指针会放在文件的开头 |
| wb | 以二进制格式打开文件,只写模式,如果文件存在则覆盖内容,如果文件不存在则新建 |
| ab | 以二进制格式打开文件,追加模式,如果文件存在则在其后追加,不存在则新建 |
| r+ | 打开一个文件用于读写,文件指针会放在开头 |
| w+ | 打开一个文件用于读写,如果文件存在则覆盖,不存在则新建 |
| a+ | 打开一个文件用于读写,如果文件存在则指针会在末尾,文件打开会追加,文件不存在则新建 |
| rb+ | 以二进制格式打开一个文件用于读写,指针会放在文件的开头 |
| wb+ | 以二进制格式打开一个文件用于读写,文件存在则会覆盖,如果不存在则新建 |
| ab+ | 以二进制格式打开一个文件用于追加,文件存在则会将指针放在末尾,如果文件不存在,则新建 |
- 在python中关闭文件用close函数,close()
2、文件的操作方法
- 写数据用write
f = open('text.txt','w')
f.write('hello world')
f.close()
结果:
hello world
- 文件读取用read
- readlines 是将文件按照行全部读取,返回列表,每行的数据为一个元素
- 分行读取用readline ,主要用于数据量过大,直接加载浪费内存,分行读取可以解决这个问题
- 在读写文件的过程中如果想知道当前的位置可以用tell(),返回指针的位置
- seek(offset,from)可以定位到某个位置,offset偏移量,from是方向,0代表文件开头,1代表当前位置,2代表文件末尾,例如seek(3,0)代表从文件开头,偏移3个字节
- 对cvs文件操作,列出个shell执行批量操作的文本制作,脚本比较乱,没有用函数或者类,还需进行优化
import os
import time
#获取电脑时间
t = time.gmtime()
#将机器时间转换为可读时间
T = time.strftime("%Y%m%d%H%M%S",t)
#创建以电脑时间命名的文件夹
os.mkdir('%s'%T)
script = open('piliangjiaoben.csv','r')
scrip_list = script.readlines()
name_list = []
#转换路径到新建脚本文件夹
file = os.chdir('.\%s'%T)
#创建以ENB为名字的文件
for line in scrip_list[1:]:
name = line[2:8]
command = eval(line[9:])
fo = open("%s.mos"%name,'a')
fo.write('%s\n'%command)
if scrip_list == 0:
break
fo.close()
file_name = os.listdir(file)
#解决同ENB问题并添加confb+/confb-
for name_new in file_name:
f = open(name_new,"r+")
f.seek(0)
f_read = f.read()
f.seek(0)
f.write('confb+\n%sconfb-'%f_read)
f.close()
for line in scrip_list[1:]:
#创建ip.txt文件
f_ip = open('ip.txt',"a+")
f_ip.write('%s\n'%line[0:8])
if scrip_list == 0:
break
f_ip.close()
#创建run.mos文件
f_run = open('run.mos',"a+")
f_run.write('lt all\nget ENodeBFunction=1 enbid > $enbid\nrun $enbid.mos\n')
f_run.close()
script.close()
3、os模块
文件的重命名、删除等操作需要用到os模块,这个是python等内置库不需要安装。
- 文件重命名:os.rename(old_name,new_name)
- 文件删除:os.remove(文件名)
- 创建文件夹:os.mkdir(‘文件夹名’)
- 获取当前目录:os.getcwd()
- 改变默认目录:os.chdir(‘路径’)
- 获取目录列表:os.listdir(‘路径’)
- 删除文件夹:os.rmdir(‘文件夹名’)
二、datetime模块
1、datetime模块包含的类
| 类名 | 功能说明 |
|---|---|
| date | 日期对象,常用的属性有year, month, day |
| time | 时间对象 |
| datetime | 日期时间对象,常用的属性有hour, minute, second, microsecond |
| datetime_CAPI | 日期时间对象C语言接口 |
| timedelta | 时间间隔,即两个时间点之间的长度 |
| tzinfo | 时区信息对象 |
2、datetime中常用的方法属性
- date对象由year年份、month月份及day日期三部分构成:date(year,month,day)
- 通过year, month, day三个数据描述符可以进行访问:a = datetime.date.today(),可以通过a.year、a.month、a.day来获取当前的具体年、月、日
- 使用__sub__(…)和__rsub__(…)方法获得两个日期相差多少天,前者为正向操作,后者为反向操作
- a = datetime.date(2019,3,6)可以用a.isocalendar()返回年、周、周几三个数据,如下:
import datetime
a = datetime.date(2019,3,6)
a.isocalendar()
Out[142]: (2019, 10, 3)
a.isocalendar()[0]
Out[143]: 2019
a.isocalendar()[1]
Out[144]: 10
a.isocalendar()[2]
Out[145]: 3
- isoformat(): 返回符合ISO 8601标准 (YYYY-MM-DD) 的日期字符串
a.isoformat()
Out[146]: '2019-03-06'
- toordinal(): 返回公元公历开始到现在的天数。公元1年1月1日为1
a.toordinal()
Out[147]: 737124
- fromtimestamp():根据给定的时间戮,返回一个date对象
time.time()
Out[148]: 1551887053.4536488
datetime.date.fromtimestamp(time.time())
Out[149]: datetime.date(2019, 3, 6)
- today():返回当前日期
datetime.date.today()
Out[150]: datetime.date(2019, 3, 6)
- format(…)方法以指定格式进行日期输出,日期的格式化:
a = datetime.date(2019,3,6)
a.__format__('%Y-%m-%d')
Out[152]: '2019-03-06'
a.__format__('%Y/%m/%d')
Out[153]: '2019/03/06'
a.__format__('%y/%m/%d')
Out[154]: '19/03/06'
a.__format__('%D')
Out[155]: '03/06/19'
- 时间格式化符号:
| 符号 | 说明 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00=59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53)星期一为星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
| %Z | 当前时区的名称 |
三、类和对象
- 将数据与函数绑定到一起,进行封装,减少重复代码的过程,叫面向对象编程,区别于面向过程编程(根据业务逻辑从上到下写代码)。
- 对象是面向对象编程的核心,在使用对象的过程中,为了将具有共同特征和行为的一组对象抽象定义,提出了类的概念。
- 类是个抽象的,在使用的时候通常会找到这个类的一个具体的存在,使用这个具体的存在,一个类可以有多个对象。
- 对象指某个具体的事物,可以看得见、能够直接使用的。
- 类就是创建对象的模版。
- 拥有相同(或类似)属性和行为的对象都可以抽象出一个类。
1、定义类
用关键字class来定义类,格式如下:
class 类名:
方法列表
class Car:
def get_car_info(self):
print('车轮子个数:%d,颜色%s'%(self.wheel_num, self.color))
def move(self):
print("车正在移动。。。")
定义类时有两种,一种是经典类(上边的Car就是),一种是新式类如:Car(object)。
类命名的规则按照大驼峰。
2、创建对象
- python中可以根据定义的类来创建出对象。
- 创建对象的格式为:对象名=类名()
class Car:
def get_car_info(self):
print('车轮子个数:%d,颜色%s'%(self.wheel_num, self.color))
def move(self):
print("车正在移动。。。")
def toot(self):
print('汽车在鸣笛')
BMW = Car()
BMW.color = '黑色‘
BMW.wheel_num = 4
BMW.toot()
print(BMW.color)
print(BMW.wheel_num)
结果:
汽车在鸣笛
黑色
4
- BMW = Car(),创建一个Car的实例对象,此时可以通过实例对象来访问属性和方法。
- 第一次BMW.color = '黑色‘表示给BMW对象添加属性,如果后面再出现表示对属性进行修改。
- 当创建一个对象时,就是用一个模子来制造一个实物。
3、__init__方法
- __init__初始化函数,用来完成一些默认的设定
class Car:
def __init__(self):
self.wheel_num = 4
self.color = '蓝色'
def move(self):
print('车在跑。。。')
BMW = Car()
print('车的颜色:%s'%BMW.color)
print('车轮胎数: %s'%BMW.wheel_num)
结果:
车的颜色:蓝色
车轮胎数: 4
- 当创建了Car对象后,在没有调用__init__方法的前提下,对象就默认有了2个属性
- __init__方法还可以在传递一些参数
class Car:
def __init__(self, new_wheel_num, new_color):
self.wheel_num = new_wheel_num
self.color = new_color
def move(self):
print('车在跑。。。')
BMW = Car(4, '蓝色')
print('车的颜色:%s'%BMW.color)
print('车轮胎数: %s'%BMW.wheel_num)
结果:
车的颜色:蓝色
车轮胎数: 4
- _init_()方法,在创建一个对象时默认被调用,不用手动调用
- _init_(self) 中,默认有1个参数名字为self,如果在创建对象时传递两个实参,那么__init__(self) 中除了self作为第一个形参外,还需要两个形参
- _init_(self) 中的self参数,不需要开发者传递,python解释器会自动把当前的对象引用传递进去
4、‘魔法’方法
- 在python中方法名如果是__xxx__()形式的,那么就有特殊功能,因此叫做‘魔法’方法
- 当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从这个方法中return的数据
class Car:
def __init__(self, new_wheel_num, new_color):
self.wheel_num = new_wheel_num
self.color = new_color
def __str__(self):
msg = "嘿。。。我的颜色是" + self.color + str(self.wheel_num) + "个轮胎"
return msg
def move(self):
print('车在跑。。。')
BMW = Car(4, '蓝色')
print(BMW)
结果:
嘿。。。我的颜色是蓝色4个轮胎
- 所谓的self可以理解为自己
- 可以把self当作C++中类里面的this指针,就是对象自身
- 某个对象调用其方法时,python解释器会把这个对象作为一个参数传递给self,所以开发者只需要传递后面的参数就行了
- 查看或者修改对象的属性,可以直接通过对象名修改或者通过方法间接修改
5、私有属性
- 为了更好的保存属性安全,即不能随意修改,处理方法为将属性定义为私有属性,添加一个可以调用的方法供调用。
- 在属性前面加两个下划线‘’,则表明该属性为私有属性,否则为公有属性,方法一样,在方法名前加两个下划线‘’则为私有方法,否则为公有方法
6、__del__方法
- 当删除一个对象时,python解释器会默认调用一个方法,_del_()方法
- 当有1个变量保存了对象引用时,此对象的引用计数就好加一
- 当使用del删除变量指向的对象时,如果对象的引用计数不是1,比如3,那么此时只会让这个引用计数减1,变成2,再调用两次,就可以把这个对象删除了
import time
class Animal(object):
def __init__(self, name):
print('__init__ 被调用')
self.__name = name
def __del__(self):
print('__del__ 被调用')
print('%s对象马上被删除'%self.__name)
dog = Animal("泰迪")
del dog
cat = Animal("波斯猫")
cat2 = cat
cat3 = cat
print("--马上删除cat对象")
del cat2
print("--马上删除cat2对象")
del cat3
print("--马上删除cat3对象")
print("程序两秒后结束")
time.sleep(2)
结果:
__init__ 被调用
__del__ 被调用
泰迪对象马上被删除
__init__ 被调用
--马上删除cat对象
--马上删除cat2对象
--马上删除cat3对象
程序两秒后结束
7、继承
- 在程序中,继承描述的是事物之间的所属关系,例如猫、狗都属于动物,泰迪、二哈都属于狗,那么所属的类可以继承父类,可以使用父类的方法、属性
- 私有的属性,不能通过对象直接访问,但是可以通过方法访问
- 私有方法不能通过对象直接访问
- 私有属性、方法不会被子类继承,也不能访问
- 一般情况下,私有属性、方法都是不对外公布的,往往用来做内部的事情,起到安全作用
- python中是可以多继承的
class Base(object):
def test(self):
print('--base test--')
class A(Base):
def test(self):
print('--A test--')
class B(Base):
def test(self):
print('--B test--')
class C(A, B):
pass
obj_C = C()
obj_C.test()
print(C.__mro__)#可以查看C类的对象搜索方法时的顺序
结果:
--A test--
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.Base'>, <class 'object'>)
8、多态
- 所谓多态,就是定义时的类型和运行时的类型不一样
class F1(object):
def show(self):
print('F1.show')
class S1(F1):
def show(self):
print('S1.show')
class S2(F1):
def show(self):
print('S2.show')
def Func(obj):
print('obj.show()')
s1_obj = S1()
Func(s1_obj)
s2_obj = S2()
Func(s2_obj)
结果:
obj.show()
obj.show()
8、类属性、实例属性
- 类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有
- 对于公有的类属性,在类外可以通过类对象和实例对象访问
- 如果需要在类外修改类属性,必须通过类对象去引用然后进行修改,如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除该实例属性
class People(object):
address = '陕西'#类属性
def __init__(self):
self.name = 'laowang'#实例属性
self.age = 20 #实例属性
p = People()
p.age = 12
print(p.address)
print(p.name)
print(p.age)
print(People.address)
print('*'*30)
print(People.name)#报错
print(People.age)#报错
结果:
陕西
laowang
12
陕西
******************************
Traceback (most recent call last):
File "<ipython-input-169-ffce27fe535f>", line 1, in <module>
runfile('/Users/frankfwu/Desktop/python文件/spyder_py/class_test.py', wdir='/Users/frankfwu/Desktop/python文件/spyder_py')
File "/Users/frankfwu/anaconda3/lib/python3.7/site-packages/spyder_kernels/customize/spydercustomize.py", line 704, in runfile
execfile(filename, namespace)
File "/Users/frankfwu/anaconda3/lib/python3.7/site-packages/spyder_kernels/customize/spydercustomize.py", line 108, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "/Users/frankfwu/Desktop/python文件/spyder_py/class_test.py", line 163, in <module>
print(People.name)
AttributeError: type object 'People' has no attribute 'name'
删除实例属性后不会报错
class People(object):
country = 'china'#类属性
print(People.country)
p = People()
print(p.country)
p.country = 'japan'
print(p.country)
print(People.country)
del p.country #删除实例属性
print(p.country)
结果:
china
china
japan
china
china
9、静态方法和类方法
- 类方法就是类对象所拥有的方法,需要用修饰器@classmethod 来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls(大部分人这样做,并不是必须起这个名)作为第一个参数,能够通过实例对象和类对象去访问
- 类对象还有一个用途是可以对类属性进行修改
class People(object):
country = 'china'#类属性
@classmethod
def get_country(cls):
return cls.country
@classmethod
def set_country(cls, country):
cls.country = country
p = People()
print(p.get_country())#可以用实例对象引用
print(People.get_country())#可以通过类对象引用
p.set_country('japan')#类方法可以对类属性进行修改
print(p.get_country())
print(People.get_country())
结果:注意打印的东西,在用类方法对类属性修改后,通过类对象和实例对象访问都发生了变化
china
china
japan
japan
- 静态方法需通过@staticmethod来修饰,静态方法不需要多定义参数
class People(object):
country = 'china'
@staticmethod
def get_country():
return People.country
print(People.get_country())
结果:
china
- 从类方法和实例方法以及静态方法多定义形式可以看出,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法
- 实例方法的第一个参数是实例对象self,通过self引用的可能是类属性,也可能是实例属性,不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高
- 静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类对象来引用
四、正则表达式
1、正则表达式介绍
正则表达式是处理字符串的强大工具,它有自己特定的语法结构。又称为正规表示法、正规表示式、常规表示法等。是计算机科学的一个概念。通常被用来检索、替换哪些匹配某个模式的文本。
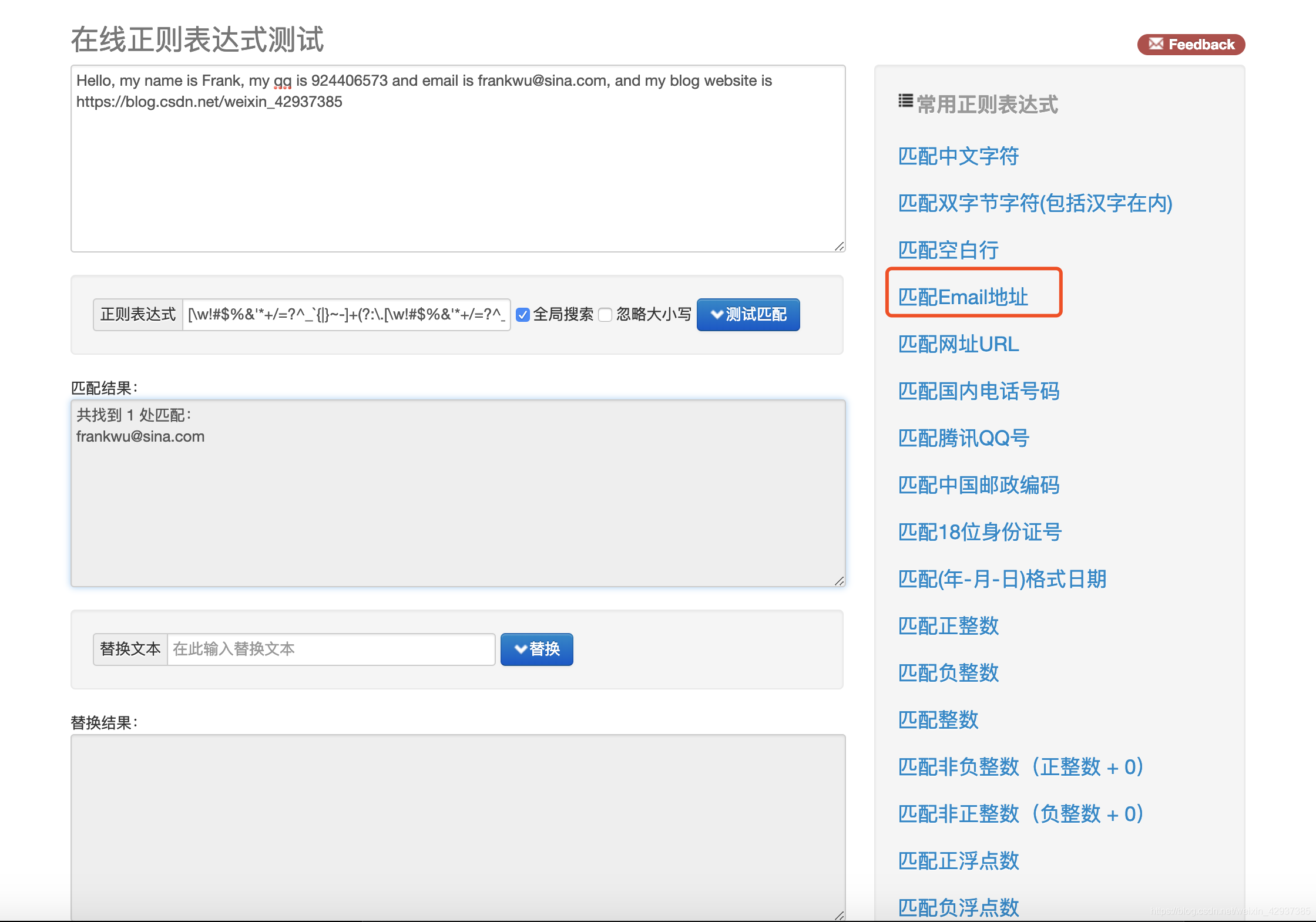
利用开源中共提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本如下:
Hello, my name is Frank, my qq is 924406573 and email is [email protected], and my blog website is https://blog.csdn.net/weixin_42937385
点击右边对应要查找的内容,就可以获得文本中相应的信息,并且正则表达式栏目出现一串怪异的字符串,这一串字符就是正则表达式([\w!#
%&’+/=?^_`{|}~-]+)@(?:\w?.)+\w?)。
2、常用的匹配规则
- \w 匹配字母、数字下划线
- \W 匹配不是字母、数字及下划线的字符
- \s 匹配任意空白字符,等价于[\t\n\r\f]
- \S 匹配任意非空白字符,[\s\S]用来匹配任意的字符(万能符)
- \d 匹配任意数字,等价于[0-9]
- \D 匹配任意非数字的字符
- \A 匹配字符串开头
- \Z 匹配字符串结尾,如果存在换行,只匹配到换行前到结束字符串
- \z 匹配字符串结尾,如果存在换行,同时匹配换行符
- \G 匹配最后匹配完成的位置
- \n 匹配一个换行符
- \t 匹配一个制表符(tab键)
- \r python中字符串前面加上r表示原生字符串,有了原生字符串,很好的避免了\转义时漏写反斜杠的错误,同时也更加直观
- ^ 匹配一行字符串开头
- $ 匹配一行字符串结尾
- . 匹配任意字符,处理换行符
- […] 用来表示一组字符,单独列出,比如[mk231]匹配m、k、2、3或1
- [^…] 不在[]中的字符,比如[^12] 不包含1、2的字符
- * 匹配0个或多个表达式
- + 匹配1个或多个表达式
- ? 匹配0个或1个前面的正则表达式定义的片段,非贪婪模式
- {n} 精确匹配n个前面的表达式
- {n,m} 匹配n到m次由前面正则表达式定义的片段,贪婪模式
- a|b 匹配a或者b,匹配左右任一表达式,优先匹配左边
- () 匹配括弧内的表达式,也表示一个组
- (?p<name>) 分组起别名
- (?P=name) 引用别名为name分组匹配到的字符串
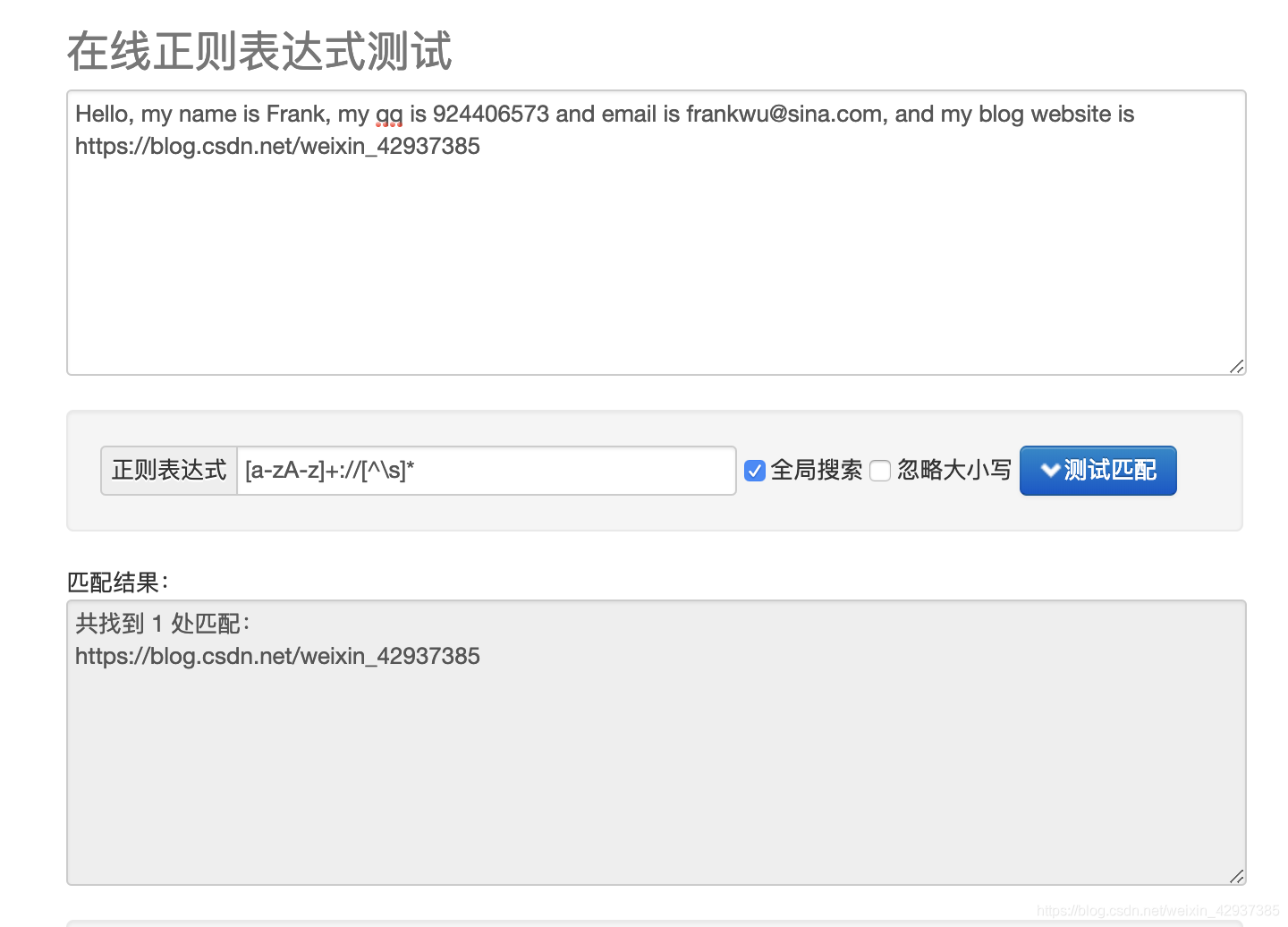
示例:URL的匹配如下图所示,[a-zA-z]+://[^\s]*, [a-zA-z]+表示中括弧中的内容匹配一次或多次,中括弧的内容匹配所有的英文字母,接着是匹配一个:,两个//,[^\s]*表示空格除了空白字符外的任意字符出现一次或多次。
五、re模块
在python中需要使用正则表达式时,通常需要一个模块,这个模块就是re,下来简单的介绍下re的一些方法。
1、match()方法
re.match 是用来进行增则匹配检查的方法,若字符串匹配正则表达式,则match方法返回匹配对象,负责返回None,而不是空字符串。re.match()能够匹配以xxxx开头的字符串。
匹配对象具有group方法,用来返回字符串的匹配部分。
span方法用来返回匹配的范围。
import re
content = 'Hello, my name is Frank'
result = re.match('^He\w\w\w', content)
print(result)
print(result.group())
print(result.span())
结果如下:
<re.Match object; span=(0, 5), match='Hello'>
Hello
(0, 5)
2、search()方法
match()方法是从字符串的开头开始匹配,一旦开头不匹配,那么整个匹配就失败了。
search()方法在匹配时会扫描整个字符串,返回第一个匹配成功的内容,如果扫描完后还没找到,则返回None。
import re
content = 'Hello, my name is Frank'
result = re.match('F\w\w\w', content)
print(result)
result2 = re.search('F\w\w\w', content)
print(result2)
result3 = re.search('U\w\w\w', content)
print(result3)
结果:
None
<re.Match object; span=(18, 22), match='Fran'>
None
3、findall()方法
如果想要获取正则表达式匹配的所有内容,显然上述两种方法不适合,这时就需借助findall()方法了,该方法会搜索整个字符串,并返回所有符合匹配规则的内容。
import re
content = 'Hello, my name is Frank'
result1 = re.match('\w+', content)
print(result1)
result2 = re.search('\w+', content)
print(result2)
result3 = re.findall('\w+', content)
print(result3)
结果:
<re.Match object; span=(0, 5), match='Hello'>
<re.Match object; span=(0, 5), match='Hello'>
['Hello', 'my', 'name', 'is', 'Frank']
4、sub()方法
除了使用正则表达式提取信息外,还可以借助其用来修改文本。
sub()方法就可将匹配到的数据进行替换。
import re
content = 'Hello my name is Frank'
result = re.sub('\s','_', content)#用_来替换空格
print(result)
结果:
Hello_my_name_is_Frank
5、compile()方法
compile()方法可以将正则表达式编译成正则表达式对象,以便在后面的匹配中复用。
例如,将三个日期中的时间去掉,借助sub方法,由于正则表达式相同,没必要写三个,可以用compile方法将正则表达式编译成一个正则表达式对象,进行复用
import re
content1 = '2019-02-28 20:00'
content2 = '2019-03-01 20:00'
content3 = '2019-03-02 20:00'
pattern = re.compile('\d{2}:\d{2}')
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
result3 = re.sub(pattern, '', content3)
print(result1)
print(result2)
print(result3)
结果:
2019-02-28
2019-03-01
2019-03-02
六、HTTP请求
1、HTTP和HTTPS
HTTP协议(超文本传输协议): 是一种发布和接收HTML页面的方法。
HTTPS: 简单讲就是HTTP的安全版,在HTTP下加入SSL层。
浏览器发送HTTP请求的过程:
1)当用户在浏览器的地址栏输入一个URL后,浏览器会向HTTP服务器发送HTTP请求,主要分为Get和 Post两种方法。
2)当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取网站的HTML文件,服务器把Response文件对象发送给浏览器。
3)浏览器分析Response中的HTML,发现其中引用了很多其他文件,浏览器会自动再次发送Request去获取其他文件。
4)当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来。
URL: 统一资源定位符,用于描述网页和其他资源地址的一种标示方法。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
- scheme: 协议(例如:http, https, ftp)
- host: 服务器的ip地址或者域名
- port#: 服务器端口(如果是走默认协议端口,缺省80)
- path: 访问资源的路径
- query-string: 参数,发送给http服务器的数据
- anchor: 锚(跳转到网页的指定锚点为止)
HTTP1.1:完善的请求/响应模型,并将协议补充完整,请求方法如下。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | HEAD | 类似于get请求,只不过返回的响应体中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求会导致新的资源建立或已有资源的修改 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| 5 | DELETE | 请求服务器删除指定页面 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将链接改为通道方式的代理服务器 |
| 7 | OPTIONS | 允许客户端查看服务器的性能 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
GET是向服务器上获取数据,POST是向服务器传送数据。
注意,避免使用get方式请求提交表单,因为可能回导致安全问题。
2、常用的请求报头
1)Host(主机和端口号)
对应网址URL中的web名称和端口号,通常属于URL的一部分
2)Connection(链接类型)
Client发起一个包含Connection:keep-alive的请求,HTTP1.1使用默认值。
server收到请求后,回复一个包含Connection:keep-alive的响应,不关闭链接(支持keep-alive)或者Connection:close的响应,关闭链接(不支持keep-alive)。
3)Upgrade-Insecure-Requests(升级为HTTPS请求)
HTTPS是以安全为目的的HTTP通道,所以在HTTPS承载页面上不允许HTTP请求,一旦出现就提示或报错。
4)User-Agent(浏览器名称)
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36
5)Accept(传输文件类型)
指浏览器或其他客户端可以接受的MIME文件类型,服务器可以根据它判断并返回适当的文件格式。
6)Referer(页面跳转处)
表明产生请求的网页来自于哪个URL,用户是从该Referer页面访问到当前请求的页面,这个属性可以用来跟踪web请求来自哪个页面,是从什么网站来的等。
7)Accept-Encoding(文件编码格式)
指出浏览器可以接受的编码方式,编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度,在接收到web响应后先解码,然后再检查文件格式,可以减少大量的下载时间。
8)Accept-Language(语言种类)
Accept-Language: zh-CN,zh;q=0.9
9)Content-Type(POST数据类型)
请求里用来表示的数据类型
Content-Type: text/html; charset=UTF-8
10)Cookie
是在浏览器中寄存的小型数据体,可以记载和服务器相关的用户信息。
3、常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并完成整个处理过程,常用200OK
- 300~399:为完成请求,客户需进一步细化请求。常用302请求页面已临时转移至新URL,304/307使用缓存资源。
- 400~499:客户端的请求有错误,常用404服务器无法找到被请求的页面,403服务器拒绝访问权限不够。
- 500~599:服务器端出现错误,常用500请求未完成,服务器遇到不可预知的情况。