在PHP开发中会经常用到字符串截取,有的时候字符串截取会出现乱码的情况,那么怎么解决这个问题呢,其实也很容易
首先我们要了解关于中英文占多少字节的问题。
ASCII码:一个中文汉字占两个字节的空间。
UTF-8编码:一个中文(含繁体)等于三个字节。
Unicode编码:一个中文(含繁体)等于两个字节。
下面我们就通过几个简单的代码示例为大家详细介绍关于PHP截取中英字符串且无乱码的相关知识。
一、 substr() 截取字符串
<?php
ehco substr('PHP中文网', 0, 5);
substr:返回字符串的子串。
substr()中第一个参数表示要截取的字符串,第二个参数表示从0位置开始截取,第三个参数表示截取长度。
截取“PHP中文网”前5个字节,结果如下:
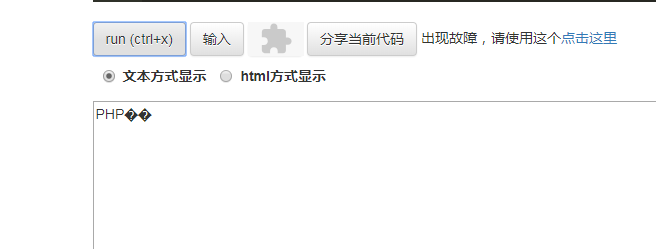
如图显示乱码,也就是说当我们使用substr函数进行中英文字符串截取时,会出现乱码。
二、关于mb_substr()截取字符串
<?php
echo mb_substr('php中文网', 0, 5);
mb_substr:获取部分字符串。 截取“PHP中文网”前5个字符,结果如下:
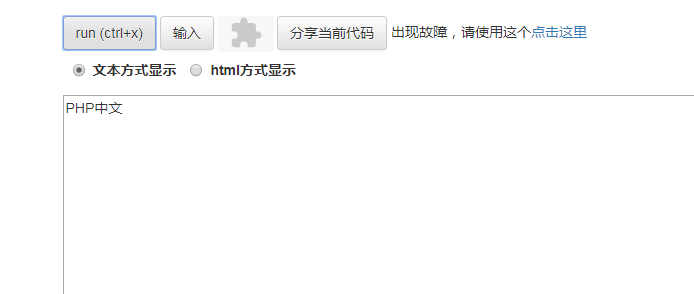
如图截取了前五个字符,并且没有出现乱码。 注:mb_substr是根据字符数来执行截取字符串。
三、 mb_strcut() 截取字符串
<?php
echo mb_strcut("PHP中文网", 0, 7);
截取“PHP中文网”前7个字节,结果如下:
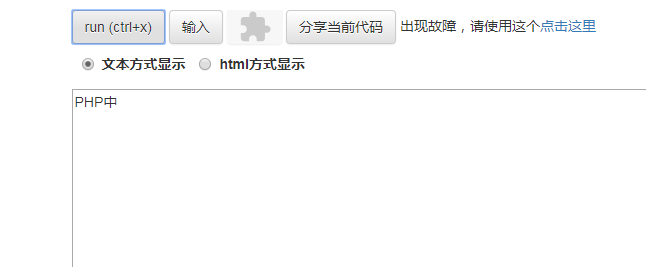
从图中可以看到,我们要截取7个字节,但是只显示截取了“PHP中”这6个字节。由于一个汉字等于三个字节,那么这里第7个字节就不会显示了。
综上所述,如果大家遇到要截取中文字符串并无乱码的需求时,可以选择后两种方法(mb_substr()和mb_strcut())