Druid的数据被保存在datasource里面, DataSource类似于关系型数据库中的table。所有的DataSource是按照时间来分片的,必要时也可以额外加上其他字段来分片。每个时间区间范围被称为一个chunk(比如当你的DataSource是按天来分片的,一天就是一个chunk)。在chunk内部,数据被进一步分片成一个或多个segment。所有的segment是一个单独的文件,通常一个segment会包含数百万行数据。segment和chunk的关系示意图如下:
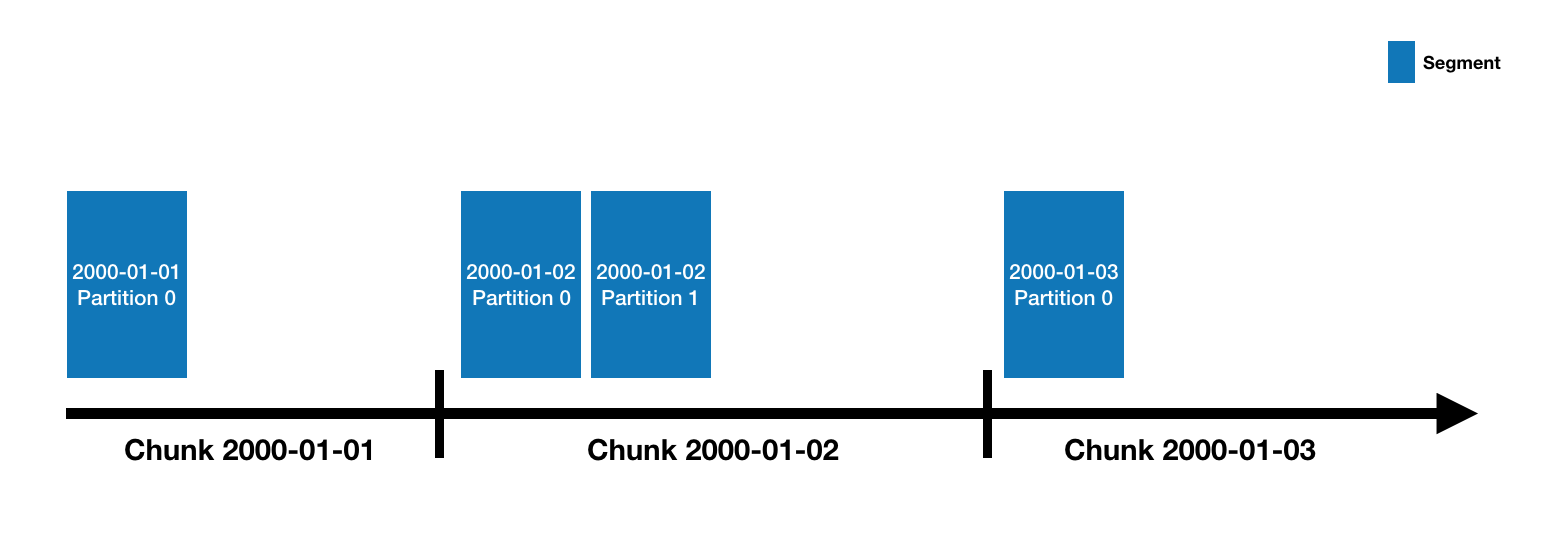
一个DataSource可以有少数几个segment构成,也可能包含多达数十万甚至上百万个segment。所有的segment的生命周期从在MiddleManager接收导入数据时被创建,最初的时候,segment时处于可修改和未提交的状态,segment的数据是紧凑的并且支持快速查询,它是通过如下步骤被创建:
- 把数据转换成列式格式;
- 通过bitmap编码来建立倒排索引;
- 通过不同的算法进行压缩:
- 对于string类型的列,通过字典编码的方式将string转换为id以最小化存储空间;
- 对bitmap索引进行位图压缩;
- 所有的列都根据类型来选择合适的压缩算法;
segment会被定期提交和发布。提交时他们会被写入deepstorage中,提交后会变成不可写的状态,然后数据就被从MiddleManager移交给Historical进程。(参考架构介绍部分:https://blog.csdn.net/weixin_40735752/article/details/88218571)。segment的信息也会被写入到metadata store组件,这个信息包括segment的格式,大小,以及在deepstorage的存储位置。Coordinator通过这些信息来获悉哪些数据在集群中是可用的。