一、简介
在Flink中,其整体的运行机制如下图(图为网上下载,如果侵权立删):

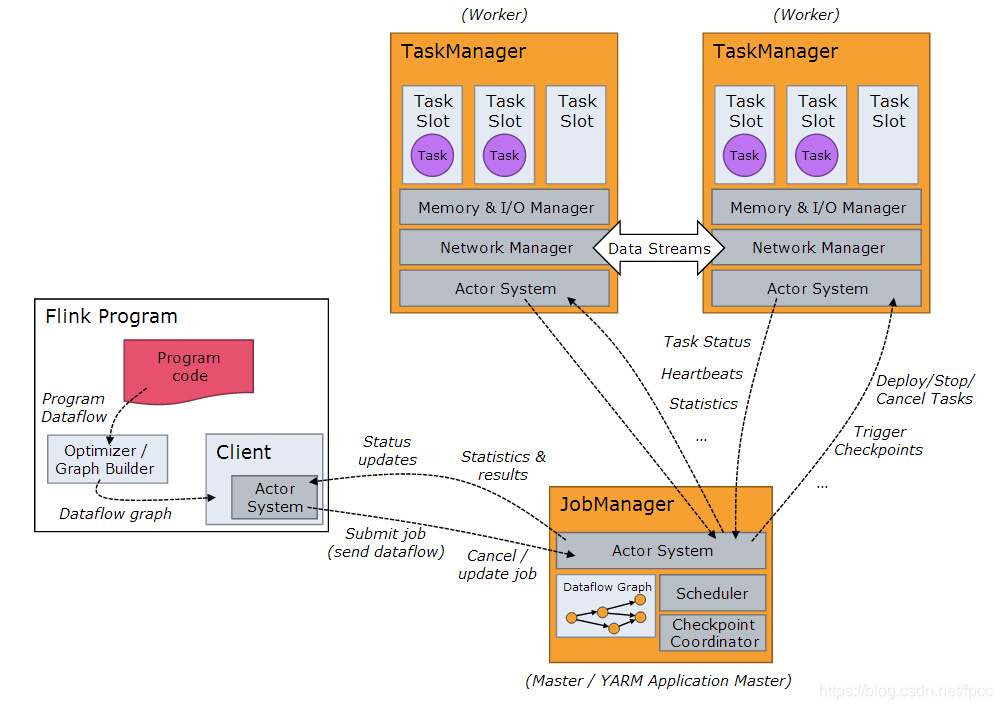
从上图可以看出,在整个Flink启动后,会启动一个JobManager和多个TaskManger,这个很好理解,一般都是一个管理者对应着多个工作者。但是,其最核心的目的是处理来自外界的数据,在Flink中,对整体的数据接口进行了抽象:

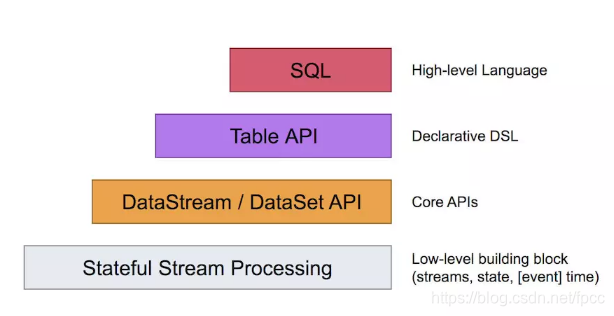
从上图可以看出,依据不同的层次Flink对数据的输入进行了抽象,从最顶层的SQL到其下的Table再到标准的数据流/数据集 API,直到带状态的底层Flink应用的数据流,通过不同的层次实现不同的响应方式。当然,它也提供了将一些(比如Table和DataStream)混合使用。
二、DataSource
flink提供了增加数据源的抽象类:
@Public
public abstract class StreamExecutionEnvironment {
......
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function) {
return addSource(function, "Custom Source");
}
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName) {
return addSource(function, sourceName, null);
}
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, TypeInformation<OUT> typeInfo) {
return addSource(function, "Custom Source", typeInfo);
}
@SuppressWarnings("unchecked")
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource<OUT, ?> sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
}
......
}
在它的成员函数里有addSource这个函数,来添加数据源,当然,在这个抽象类内部,已经定义好了几个source,诸如:
public final <OUT> DataStreamSource<OUT> fromElements(OUT... data){...}
public final <OUT> DataStreamSource<OUT> fromElements(Class<OUT> type, OUT... data) {...}
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, TypeInformation<OUT> typeInfo) {...}
......
上面只是列出几个,其它还有几个,大家可以去看源码。
如果将这些数据源分类的话,大致分为以下几类:
1、容器相关
比如:public DataStreamSource fromCollection(Collection data) ,可以迅速的从外部接口中导入相关的数据集合,不用再转来转去。
2、文件流相关
比如:public DataStreamSource readTextFile(String filePath) ,这个对操作文件流最方便了,大家都知道在网络中一般会专门提供文件操作的服务,这个也类似。
3、网络相关
比如:public DataStreamSource socketTextStream(String hostname, int port),Flink天生要对网络计算提供支持,这正是它的优势。本地也有一个Example,名字是Word count ,记得好像HADOOP也有一个类似的例程,好像大数据里都要提供一个类似的例程,有点像普通程序里的Hello World。
4、自定义
反正有addSource,你喜欢啥样的数据源就自己继承这个类搞一下呗。这里说明一下,如果想实现,可以参考Flink内部提供的其它的源码:
@Public
public interface SourceFunction<T> extends Function, Serializable {
void run(SourceContext<T> ctx) throws Exception;
void cancel();
@Public // Interface might be extended in the future with additional methods.
interface SourceContext<T> {
...
}
}
上面是SourceFuction接口定义,再看一下Flink中如何添加的:
@Test
public void testResourcesForChainedSourceSink() throws Exception {
......
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<Integer, Integer>> source = env.addSource(new ParallelSourceFunction<Tuple2<Integer, Integer>>() {
@Override
public void run(SourceContext<Tuple2<Integer, Integer>> ctx) throws Exception {
}
@Override
public void cancel() {
}
});
......
}
这样,一个最简单的源就添加了。
三、总结
通过上述的源码分析,可以了解到了Flink中的数据入口,这样,就为下来分析如何处理数据提供了启动的条件。
