Oracle数据库这部分内容有点长,我今天一天直看完了教学视频,现在还在翻PPT,大概明天能完全整理完吧~
然后昨天本来应该还有一个SSH的实战项目来着,我偷懒了...我有空一并补上,就这个礼拜~
目录
一、Oracle的简介
ORACLE数据库系统是美国ORACLE公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或B/S体系结构的数据库之一。比如SilverStream就是基于数据库的一种中间件。ORACLE数据库是目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库它实现了分布式处理功能。但它的所有知识,只要在一种机型上学习了ORACLE知识,便能在各种类型的机器上使用它。
Oracle数据库最新版本为Oracle Database 12c。Oracle数据库12c 引入了一个新的多承租方架构,使用该架构可轻松部署和管理数据库云。此外,一些创新特性可最大限度地提高资源使用率和灵活性,如Oracle Multitenant可快速整合多个数据库,而Automatic Data Optimization和Heat Map能以更高的密度压缩数据和对数据分层。这些独一无二的技术进步再加上在可用性、安全性和大数据支持方面的主要增强,使得Oracle数据库12c 成为私有云和公有云部署的理想平台。
Oracle具有如下特点:
1、完整的数据管理功能:
1)数据的大量性
2)数据的保存的持久性
3)数据的共享性
4)数据的可靠性
2、完备关系的产品:
1)信息准则---关系型DBMS的所有信息都应在逻辑上用一种方法,即表中的值显式地表示;
2)保证访问的准则
3)视图更新准则---只要形成视图的表中的数据变化了,相应的视图中的数据同时变化
4)数据物理性和逻辑性独立准则
3、分布式处理功能:
ORACLE数据库自第5版起就提供了分布式处理能力,到第7版就有比较完善的分布式数据库功能了,一个ORACLE分布式数据库由oraclerdbms、sql*Net、SQL*CONNECT和其他非ORACLE的关系型产品构成。
4、用ORACLE能轻松的实现数据仓库的操作。
因为Oracle数据库具有可用性强、可扩展性强、数据安全性强、稳定性强等特点,在企业开发中占据更加重要的位置。
下面我们来说一说Oracle里的一些基本概念~
Oracle数据库是位于硬盘上实际存放数据的文件,这些文件组织在一起,成为一个逻辑整体,即Oracle数据库。因此在Oracle看来,“数据库”是指硬盘上文件的逻辑集合,必须要与内存里实例合作,才能对外提供数据管理服务。
而Oracle实例是位于物理内存里的数据结构。它由一个共享的内存池和多个后台进程所组成,共享的内存池可以被所有进程访问。用户如果要存取数据库(也就是硬盘上的文件)里的数据,必须通过实例才能实现,不能直接读取硬盘上的文件。
它们的区别在于实例可以操作数据库,在任何时刻一个实例只能与一个数据库关联,大多数情况下,一个数据库内只有一个实例对其进行操作。
表空间由多个数据文件组成,为逻辑概念;数据文件只能属于一个表空间,为物理概念。
段存在于表空间中;段是区的集合;区是数据块的集合;而数据块会被映射到磁盘块。
数据库的逻辑和物理结构

二、Oracle的安装
具体的安装就不多说了,在安装结束前有一个权限管理,可以在那里面设置相应的登陆用户名等等~
我们通常把SCOTT和HR这两个取消勾选,密码随高兴填写就好(如果是安装到管理员机器上的,那么登陆时不管输入什么都能够登陆进去,这是因为有机器验证)。
三、基本的SQL语句
Oracle支持SQL92和SQL99等等多种SQL标准,这里对一些简单的SQL操作进行介绍,其实大部分都跟MySQL的操作相似。
这里有几点需要注意一下:
- 空值是无效的,未指定的,但是它并不等同于空格或者0!包含空值的数学表达式都为空值。
- 列的别名使用双引号,区分大小写。例:SELECT ename AS "Name" ... AS可以省略。
- 连接符不是&,而是 || ,把列与列、列与字符等连接在一起,可以用来合成列。例SELECT ename||'_'||job AS "Employees" FROM emp; 日期和字符只能在单引号中出现!

基本操作:
1、删除重复行
使用关键字DISTINCT:SELECT DISTINCT depto FROM emp;
2、显示表结构
使用DESCRIBE命令:DESCRIBE emp;

3、过滤
WHERE子句:SELECT * FROM empno WHERE deptno=10;
对于字符和日期要写在单引号中~
字符大小写敏感,日期格式敏感(默认日期格式为DD-MON-RR)
4、比较运算
- = : 等于(而不是我们java中熟悉的==)
- := : 赋值
- > : 大于
- >= : 大于等于
- < : 小于
- <= : 小于等于
- <> 或 != : 不等于
- BETWEEN ... AND ... : 在两者之间
- IN(set) : 等于值列表中的一个
- LIKE : 模糊查询,可以使用%和_,意义与MySQL中相同,表示通配符
- IS NULL : 空值
5、逻辑运算
AND OR NOT : 并 或 否
它们之间的优先级如下(可以通过括号来改变):

6、排序
使用ORDER BY子句,ASC升序,DESC降序,该子句在SELECT语句的结尾: SELECT * FROM emp ORDER BY hiredate DESC;
如果是多个列排序,按从左到右的优先级排列: SELECT * FROM emp ORDER BY deptno, hiredate DESC;
四、单行函数
什么是单行函数呢?单行函数具有如下特点:
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以转换数据类型
- 可以嵌套
- 参数可以是一列或一个值
基本的单行函数有字符、数字、日期、转换和通用五类,下面一一介绍~
1、字符函数
1.大小写控制函数
· LOWER 转换成小写:SELECT * FROM emp WHERE LOWER(ename)=‘king’;
· UPPER 转换成大写:SELECT * FROM emp WHERE UPPER(ename)=‘KING’;
· INITCAP 首字母大写:SELECT * FROM emp WHERE INITCAP(ename)=‘King’;
2.字符控制函数
· CONCAT 字符连接函数:CONCAT('Hello', 'World') -- HelloWorld
· SUBSTR 取子串:SUBSTR('HelloWorld', 1, 5) -- Hello
· LENGTH / LENGTHB 求字符串长度:LENGTH('HelloWorld') -- 10
· INSTR 指定字符在字符串中的位置:INSTR('HelloWorld', 'W') -- 6
· LPAD | RPAD 以某符号作为占位符:LPAD(salary, 10, '*') -- *****24000
· TRIM 从串中删除首个匹配的字母:TRIM('H' FROM 'HelloWorld') -- elloWorld
· REPLACE 替换指定字符为另一指定字符:REPLACE('HelloWorld', 'H', 'h') -- helloWorld
2、数字函数
· ROUND 按指定位四舍五入:ROUND(45.927, 2) -- 45.93
· TRUNC 在指定位置截断:TRUNC(45.927, 2) -- 45.92
· MOD 取余:MOD(1600, 300) -- 100
3、日期函数
Oracle中的日期型数据实际含有两个值:日期和时间,默认的日期格式为DD-MON-RR
· SYSDATE 得到当前系统时间:我们现在假设SYSDATE='25-JUL-95'
· ROUND 日期四舍五入:ROUND(SYSDATE, 'MONTH') -- 01-AUG-95
· TRUNC 日期截断:TRUNC(SYSDATE, 'MONTH') -- 01-JUL-95
· MONTH_BETWEEN 返回两个日期相差的月数:MONTH_BETWENN('25-JUL-95', '02-AUG-95') -- 1
· NEXT_DAY 指定日期的下一天:NEXT_DAY('25-JUL-95') -- '26-JUL-95'
· ADD_MONTHS 指定日期中加上若干月数
· LAST_DAY 本月的最后一天
4、转换函数
1.隐式转换

2.显式转换
TO_NUMBER、TO_DATE、TO_CHAR的格式是一样的:TO_CHAR(string, 'format_model');
·
我们先介绍有关日期的转换函数:
日期格式的元素有以下这些:

我们可以使用""双引号向日期中添加字符:DD "of" MONTH -- 12 of OCTOBER
再说说TO_CHAR函数常使用的几种格式:

比如:SELECT(TO_CHAR, '$99,999.00') SALARY FROM emp WHERE ename=‘KING’;
-- 
5、通用函数
这些函数适用于任何数据类型,包括空值~
· NVL(E1, E2) 如果E1为NULL,则函数返回E2,否则返回E1本身
· NVL2(E1, E2, E3)(在Oracle中xxx2函数都是对元函数的增强) 如果E1为NULL,则函数返回E3,若E1不为null,则返回E2
· NULLIF(E1, E2) 如果E1==E2,返回null,否则返回E1
· COALESCE(E1, E2, ...) 返回第一个非null值,否则返回null
下面来讲一个比较特殊的存在——条件表达式
以SQL中的IF-THEN-ELSE逻辑为例,使用CASE表达式(SQL99语法,类似Basic,较繁琐)和DECODE函数(Oracle的语法,类似java,简洁)。
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_expr3 THEN return_expr3
ELSE else_expr]
END
DECODE (col | expression, search1, result1[, search2, result2, ...] [, default])
五、分组函数
分组函数作用于一组数据,并对一组数据返回一个值。
常用的组函数有AVG、COUNT、MAX、MIN、SUM等,它的语法如下:
SELECT [column, ...] group_function(column, ...)
FROM table
[WHERE condition1, ...]
[GROUP BY column]
[ORDER BY column [ASC, DESC]]
值得注意的一点是——组函数忽略空值~
当然,我们使用SELECT筛选出来的列,如果没有出现在组函数当中,那么也一定要出现在GROUP BY语句当中!!!
通常而言,我们不能在WHERE语句中使用组函数,但是,我们可以在HAVING语句中使用组函数,所有符合条件的内容将被打印~
额外的说说GROUP BY的增强语句吧~要想到达类似于报表的这个效果,我们应该怎么做呢?
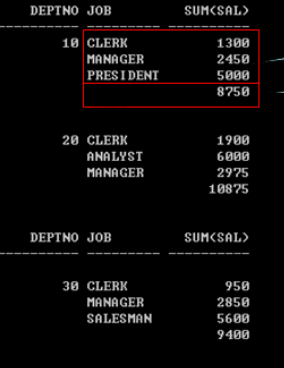
使用break on deptno skip 2这个命令即可,break on表示不打印重复列名,skip 2表示两类间隔两行~
六、多表查询
1、等值连接
SELECT alias1.column, alias2.column FROM table1 alias1, table2 alias2 WHERE alias1.column1=alias2.column2 AND ...
我们使用表的别名来简化名称同时提高效率(使用了别名就不能使用真名了),对于多个查询条件适用AND连接~
2、不等值连接
我们使用BETWEEN ... AND ... 语句~
3、外连接
使用外连接可以查询不满足连接条件的数据,它的符号是(+)
table1.column(+) = table2.column是右外连接(x外连接,则x表全部显示),与之相对应的,table1.column = table2.column(+)是左外连接
对于(+)的使用,有如下的注意事项:
1.(+)操作符只能出现在where子句中,并且不能与outer join语法同时使用。
2. 当使用(+)操作符执行外连接时,如果在where子句中包含有多个条件,则必须在所有条件中都包含(+)操作符
3.(+)操作符只适用于列,而不能用在表达式上。
4.(+)操作符不能与or和in操作符一起使用。
5.(+)操作符只能用于实现左外连接和右外连接,而不能用于实现完全外连接。4、自连接
即将一张表视为多张表,通过别名来实现,如:FROM emp e, emp b WHERE e.mgr = b.empno;
5、叉集
使用CROSS JOIN产生叉集,表中的对应行都会产生新的一行数据(如:A表中20行的数据,B表中有8行数据,那么叉集产生的结果便是20×8=160条),它与笛卡尔集的结果是一样的,如:SELECT xxx FROM xxx CROSS JOIN xxx;
在实际情况下,我们要尽量避免这种情况的发生,因为它会占用非常大的内存~
6、自然连接
使用NATURE JOIN进行自然连接,它会以两个表中具有相同名字的列为条件创造等值连接,但如果列名相同而数据类型不同则会产生错误~
在这里面,我们可以通过使用USING子句来指定使用的列,如:... FROM employee e NATURE JOIN departments d USING (department_id);
当然,我们也可以使用ON子句来指定额外的连接条件,如:... FROM employee e NATURE JOIN departments d ON (e.department_id = d.department_id);
七、子查询
子查询简单来说,就是在查询当中嵌套一个查询语句。子查询在主查询执行前完成,查询的结果由主查询调用。
如:SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='SCOTT');
需要注意的是,子查询要包含在括号内,且要放在比较条件的右侧,如果是多行操作符,则需要对于多行子查询~
给出一道面试真题,答案会在文末给出(题号1)

八、集合运算
UNION 并集 
UNION ALL 并集(包括重叠部分) 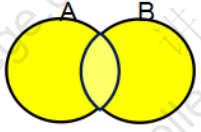
INTERSECT 交集 
MINUS 差集(属于A但不属于B的部分) 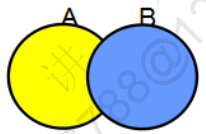
集合运算在两条SELECT语句中间使用~~
九、处理数据
1、增删改
数据库操作语言DML可以在下列条件下执行:插入数据、修改数据以及删除数据~~
1.增
· 插入单条语句:INSERT INTO table VALUE ...
· 从其他表中拷贝数据:INSERT INTO sales_reps(id, name, salary, commission_pct) SELECT employee_id, last_name, salay, commission_pct FROM employees WHERE job_id LIKE '%REP%';
2.改
· 更新:UPDATE ... SET ...;
3.删
· DELETE FROM table [WHERE ...];
· 清空表:TRUNCATE
DELETE和TRUNCATE的区别在于:DELETE可以ROLLBACK,可能产生磁盘碎片且不释放磁盘空间;而TRUNCATE不能回滚,不产生碎片。
2、事务
数据库事务由以下几部分组成:
- 一个或多个DML语句
- 一个DDL(Data Defination Language,数据定义语言)语句
- 一个DCL(Data Control Language,数据控制语言)语句
它以第一个DML语句的执行作为开始,以下面其中之一为结束:
- 显示结束:commit rollback
- 隐式结束(自动提交):DDL语言、DCL语言、exit(事务正常退出)
- 隐式回滚(系统异常终止):关闭窗口、掉电等异常情况~~
通过使用commit和rollback语句,我们可以确保数据的完整性,在数据改变被提交之前能够预览,而且能够将逻辑上相关的操作进行分组。
使用SAVEPOINT创建保存点~~使用ROLLBACK TO SAVEPOINT回滚到创建的保存点~~
3、隔离级别
Oracle只有两个隔离级别:READ COMMITED和SERIALIZABLE,Oracle默认的隔离级别是READ COMMITED
十、表&视图&其他
1、表的相关操作
1.CREATE TABLE tablename [AS SELECT ...(子查询)]
2.ALTER TABLE ADD / MODIFY / DROP / RENAME...TO...
2、约束
约束是表一级的限制,如果存在依赖关系,可以防止错误的删除数据。约束的类型主要有:NOT NULL(非空),UNIQUE(唯一),PRIMARY KEY(主键),FOREIGN KEY(外键)以及CHECK(检查满足条件)
用户可以使用CONSTRAINT自定义约束,给个栗子~~
create table student
(
sid number constraint student_pk primary key,
sname varchar2(20) constraint student_name_notnull not null,
gender varchar2(2) constraint student_gender check (gender in ('男','女')),
email varchar2(40) constraint student_email_unique unique
constraint student_email_notnull not null,
deptno number constraint student_fk references dept(deptno) on delete set null
);3、视图
视图是一种虚表,它建立在已有表(这些表称之为基表)的基础上,可以理解为存储起来的SELECT语句~
视图可以限制视图访问,可以简化复杂查询,可以提供数据的相互独立,可以给相同的数据提供不同的显示方式,但是有一点很可惜,它并不能提高数据库的性能~~
我们采用如下语法创建视图:
CREATE [OR REPLACE] [FORCE | NOFORCE] VIEW viewname [alias...] AS subquery [WITH CHECK OPTION ...] [WITH READ ONLY [CONSTRAINT]];
-- FORCE 表示子查询不一定存在
-- NOFORCE 表示子查询存在(默认)
-- WITH READ ONLY 表示只做查询操作(屏蔽对视图的DML操作)
4、其他
包括序列SEQUENCE、索引INDEX等等,不做详解
十一、存储过程
1、CREATE PROCEDURE procedurename AS PLSQL体 创建一个存储过程
--给指定的员工涨100,并且打印涨前和涨后的薪水
create or replace procedure raiseSalary(eno in number)
is
--定义变量保存涨前的薪水
psal emp.sal%type;
begin
--得到涨前的薪水
select sal into psal from emp where empno=eno;
--涨100
update emp set sal=sal+100 where empno=eno;
--要不要commit?
dbms_output.put_line('涨前:'||psal||' 涨后:'||(psal+100));
end raiseSalary;
/2、CREATE FUNCTION functionname RETURN 函数值类型 AS PLSQL体 创建一个存储函数
--查询某个员工的年收入
create or replace function queryEmpIncome(eno in number)
-- in表示为输入参数,相应的out为输出参数
return number
as
--定义变量保存月薪和奖金
psal emp.sal%type;
pcomm emp.comm%type;
begin
--得到月薪和奖金
select sal,comm into psal,pcomm from emp where empno=eno;
--返回年收入
return psal*12+nvl(pcomm,0);
end queryEmpIncome;
/
十二、触发器
触发器是一种与表相关联的PLSQL程序,当特定的语句发出时自动触发。分为语句级触发器以及行级触发器~
CREATE TRIGGER name {BEFORE | AFTER} {DELETE | INSERT | UPDATE [OF 列名]} ON 表名 [FOR EACH ROW [WITH ...]] PLSQL体
/*
实施复杂的安全性检查
禁止在非工作时间 插入新员工
1、周末: to_char(sysdate,'day') in ('星期六','星期日')
2、上班前 下班后:to_number(to_char(sysdate,'hh24')) not between 9 and 17
*/
create or replace trigger securityemp
before insert
on emp
begin
if to_char(sysdate,'day') in ('星期六','星期日','星期五') or
to_number(to_char(sysdate,'hh24')) not between 9 and 17 then
--禁止insert
raise_application_error(-20001,'禁止在非工作时间插入新员工');
end if;
end securityemp;
/
我心有点乱,今天就到这里......
我是小昶,明天再见吧