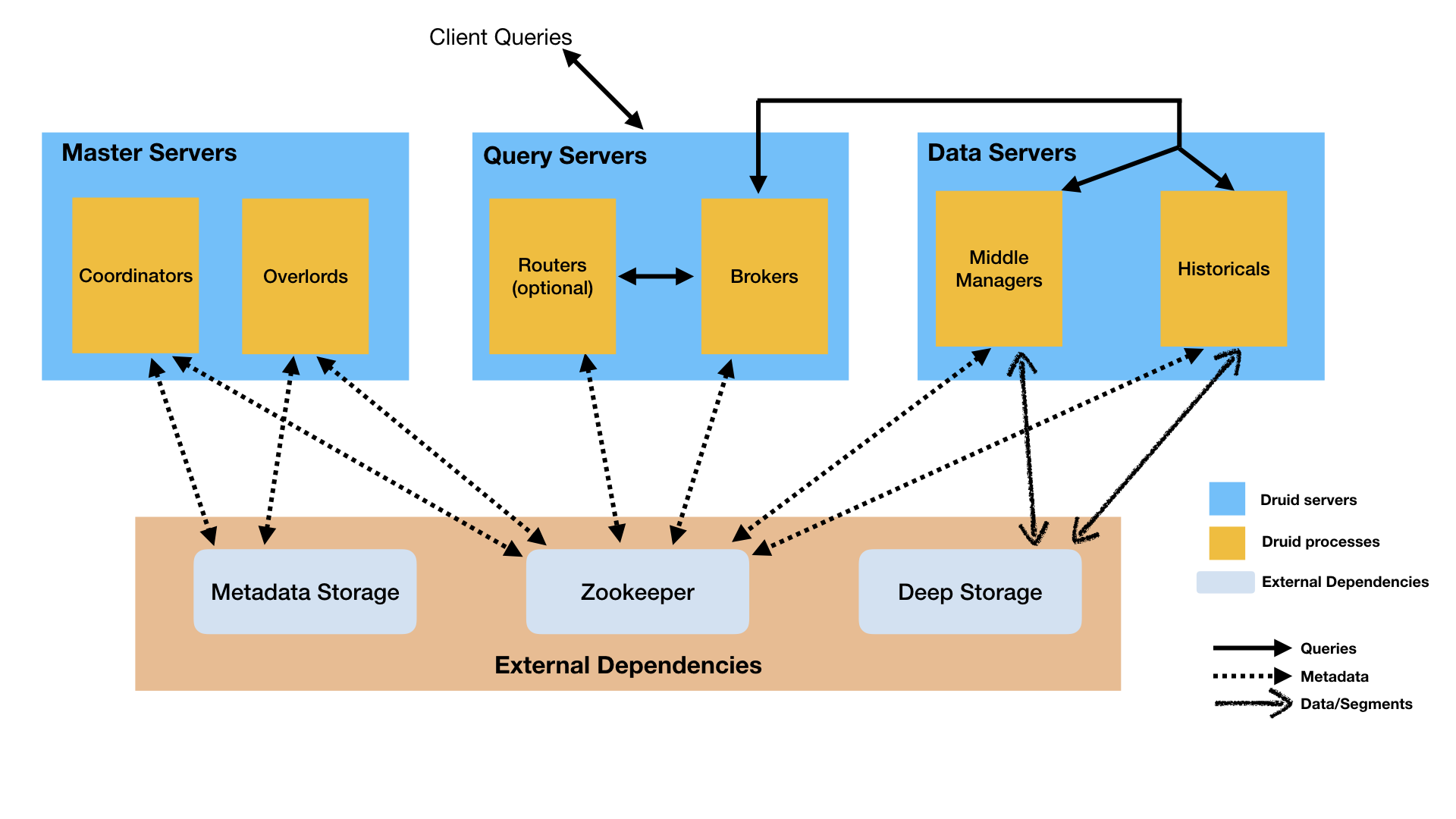
Druid采用多进程,分布式的架构;其架构易于运维及部署,便于部署在云环境中。每个Druid进程都可以被独立地配置和横向扩展,这种设计一方面赋予了Druid集群最大的灵活性和可扩展性,另一方面以提供了更高的容错性:避免了个别组件的失效影响了系统的其他模块。
Druid进程类型包括:
Historical进程:Historical进程用于处理历史数据的存储和查询(历史数据包括所以已经被committed的流数据)。Historical进程从深度存储(Deep Storage)中下载Segment数据,同时支持对这些数据的查询操作。Historical进程不支持写入操作。
MiddleManager进程:MiddleManager负责将数据导入到集群中。他们负责从外部数据源中读取数据,也负责发布新的Segment。
Broker进程:Broker负责从外部客户端接收查询请求,并把这些请求拆分成子查询后转发给Historical和MiddleManager。当Broker接收到这些子查询的结果疑惑,会合并子查询结果并将结果返回给调用者。终端用户实际上都是和Broker做交互,而不会直接查询Historical和MiddleManager。
Coordinator进程:Coordinator进程负责协调Historical进程。他们负责把Segment分配给特定的Historical进程,以及确保这些Segment在Historical间是负载均衡的。
Overlard进程:Overlard进程负责协调MiddleManager进程,它也是数据导入的控制器,负责将数据导入任务分配给MiddleManager以及协调发布新的Segment数据。
Router进程:Router进程是为Broker,Overlard, Coordinator提供统一网关服务的可选进程。用户也可以不适用Router而将请求直接发送给Broker,Overlard,Coordinator。
Druid进程可以被独立部署(物理机,虚拟机,或者容器),也可以被混布在同一个机器上。一个推荐的部署方案是:
- 数据服务器用于运行Historical和MiddleManager进程;
- 查询服务器用于运行Broker和Router(可选)进程;
- 管理服务器用于运行Coordinator和Overlard进程,这个服务器上也可以同时运行zookeeper。
除了上述进程类型以外,Druid还有三种外部组件,他们可以用来利用已有的基础设施:
Deep Storage:可以被所有Druid服务器访问的共享文件存储。通常是一个类似S3或HDFS的分布式存储系统,或者是一个可以mount的网络文件系统。Druid利用DeepStorage来存储所有导入的数据。
Metadata Store:共享的metadata存储,通常是一个传统的关系型数据库,比如Postgresql或MySQL。
Zookeeper:用于内部服务的发现,协调以及leader选举。
这些设计的初衷是为了让Druid在大规模生产环境中能够被容易的运维。比如,将metadata store和Deep Storage从其他部件中分离能够让druid系统是高度容错的:即使所有的Druid服务器都挂了,我们也可以很容易的从metadata store和Deep Storage中重新启动一个集群。
架构图如下: