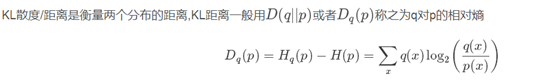强化学习总结和理解,都是自己最近学习的总结 ,如果有不对的地方还请指出
这一周一直在学强化学习,总结了常见经典算法,强化学习的资源很少,2015年alphago的成功才火起来。不知道未来会不会继续有突破,学完感觉比深度学习难了很多,资源也非常少,对数学要求极高,还需要提高数学和实践能力,以下为自己看了几十遍算法总结的心得。
强化学习分为在线学习和离线学习
Off-policy:q-learning
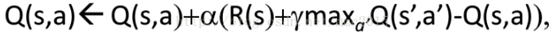
On-policy: sarsa
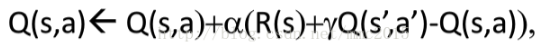
On-policy是保证跟随最优策略的基础上保持对动作的探索性,也必然会失去选择最优动作的机会。(采取动作策略时选择 更新Q时也采用选择动作的策略—容易陷入局部最优)
Off-policy 是允许迭代过程中有两个policy,一个用于生成学习过程的动作,一个由值函数产生的最优策略(采取动作策略时选择 ,更新Q时采用从过往Q表中选max-Q来更新)
值迭代更新
传统Q-learinig 的Q-table无法满足大量状态和动作,DQN是第一个将深度学习模型与强化学习结合在一起从而成功地直接从高维的输入学习控制策略。
DQN:
创新点:
基于Q-Learning构造Loss Function(不算很新,过往使用线性和非线性函数拟合Q-Table时就是这样做)。
通过experience replay(经验池)解决相关性及非静态分布问题;
使用TargetNet解决稳定性问题。
优点:
算法通用性,可玩不同游戏;
End-to-End 训练方式;
可生产大量样本供监督学习。
缺点:
无法应用于连续动作控制;
只能处理只需短时记忆问题,无法处理需长时记忆问题(后续研究提出了使用LSTM等改进方法);
CNN不一定收敛,需精良调参。
Class deep-q net()
Self.memory=init
Build eval net()
Q_eval = w* s+b //实时预测Q值
Build target net() //历史Q值表 对照找Q(s_)
Q_next = w*s_ +b //算下个状态Q值
Store_memory() //存储 s,a,r,s_ 等待训练
Choose——action () //选择e-贪婪算法选动作
Learn() //到达一定步数 将q_eval网络训练的参数赋给q_target网络
Main()
For episode:
A = choose_action(s)
S_,r = env.step(A)
Store_memory(s,a,s_,r)
到达一定步数:
从memory库随机选不相关记忆训练,loss=根号(max(q_target_s_)-q_eval(s))平方
反向传播修改q_eval参数,隔一定步数,赋给q_target.
(DQN-已经完全掌握理解了)
max操作使得估计的值函数比值函数的真实值大。如果值函数每一点的值都被过估计了相同的幅度,即过估计量是均匀的,那么由于最优策略是贪婪策略,即找到最大的值函数所对应的动作,这时候最优策略是保持不变的。也就是说,在这种情况下,即使值函数被过估计了,也不影响最优的策略。强化学习的目标是找到最优的策略,而不是要得到值函数,所以这时候就算是值函数被过估计了,最终也不影响我们解决问题。然而,在实际情况中,过估计量并非是均匀的,因此值函数的过估计会影响最终的策略决策,从而导致最终的策略并非最优,而只是次优,为了解决值函数过估计的问题,Hasselt提出了Double Qlearning的方法。所谓Double Qlearning 是将动作的选择和动作的评估分别用不同的值函数来实现。
变体1,Double-DQN(DDQN):
和DQN结构一样,不过q-target是由两个网络算出来的,动作由q_eval算,Q值由q-target算。

变体2,prioritized dqn:
游戏在初期尝试时,总会在原地徘徊,拿到都是负样本奖励,记忆库里有用的正样本很少,prioritized replay会重视这种少量的值得学习的样本。算法重点是在batch抽样时不是随机抽样,而是根据优先级,优先级的确定:原本是TD_e
rror,如果error越大,代表预测精度有很大的上升空间,样本就越需要被学习,优先级越高。

变体3-dueling-DQN:
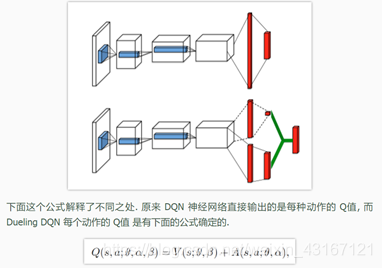
输出的Q是状态值加优势值函数。
普通的DQN:

Dueling-dqn:

策略迭代更新
值更新输出动作的Q值,动作多了或者状态多了就不行了。策略梯度可以算连续动作,随机策略梯度输出的是动作的概率,确定性动作梯度输出确定的一个动作。只能进行回合更新。
Loss = log(prob|s,a) * vt //vt可以是TD_error,Q值,A(优势函数)….
反向传播 提高其中好的动作的概率,降低不好的,vt是幅度
AC算法 Actor 和 Critic:
Actor是策略梯度网络,尽量迎合critic的评分来更新自己的动作,critic是Q值网络,给actor进行评价,尽量更新Q,使得Q收敛。增加了单步更新属性,比传统的policy gradiant更快。但是取决于critic的价值判断,critic很难收敛,加上actor的更新就更难收敛,所以有升级版的deterministic policy gradiant,以AC为思想。
Class actor()
Def init() //初始化网络,输入状态s ,按概率输出动作
Def train()
Loss = E(log(action_prob) * TD_error)
// TD_error是从critic网络传过来的TD_error = (r+gammaV_next) - V_eval
Train = minize(loss) //反向传播回去
Def choose_action()
np.random.choice //根据动作概率随机选
Class critic()
Def init() //初始化网络,输入状态s 和动作a,输出动作的Q值
Def train()
Loss = 平方 (TD_error= (r+gammaV_next) - V_eval)
//优势函数TD_error= A= Q-V , Q = r+gamma*v_next
Train = minize(loss) //反向传播回去
Main()
For episode:
A = choose_action
S_,r = env.step(A)
TD_error = critic.td_error
Actor.learn() //更新actor的网络参数
以我个人理比较通俗的理解是:
Actor看到游戏目前的state,做出一个action(根据动作概率选, 生成action的过程,本质上是一个随机过程;最后学习到的策略,也是一个随机策略(stochastic policy).
Critic根据state和action两者,对actor刚才的表现打一个分数。
Actor依据critic(评委)的打分,调整自己的策略(actor神经网络参数),争取下次做得更好。
Critic根据游戏系统给出的reward(相当于ground truth)和以往的打分(critic target)来调整自己的打分策略(critic神经网络参数)。
一开始actor随机表演,critic随机打分。但是由于reward的存在,critic评分越来越准,actor表现越来越好。(目前还不知道自己理解的有没有偏差)
优势函数: ,值函数V(s)可以理解为在该状态S下所有可能动作所对应的动作值函数乘以采取该动作的概率的和。更通俗的讲,值函数V(S)是该状态下所有动作值函数关于动作概率的平均值。而动作值函数Q(s,a)是单个动作所对应的值函数,如果优势函数大于零,则说明该动作比平均动作好
A3C算法
如果只用单个 agent(actor-critic)进行样本的采集,那么我们得到的样本就非常有可能是高度相关的,DQN、DDPG算法使用的experience replay(经验重放),可以说是解决了强化学习满足独立同分布的问题,然而有优点点的背后也是有代价的,就是它使用了更多的资源和每次交互过程的计算,并且他需要一个off-policy学习算法去更新由旧策略产生的数据
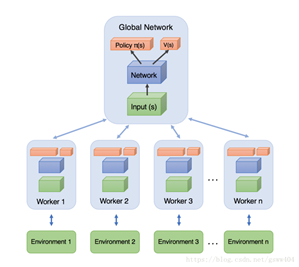

训练的时候,同时为多个线程上分配task,学习一遍后,每个线程将自己学习到的参数更新(这里就是异步的思想)到全局Global Network上,下一次学习的时候拉取全局参数,继续学习。
概况A3C: Google DeepMind 提出的一种解决 Actor-Critic 不收敛问题的算法. 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所以更新的相关性被降低, 收敛性提高.
DDPG
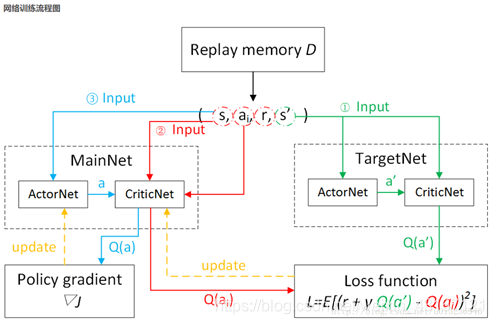
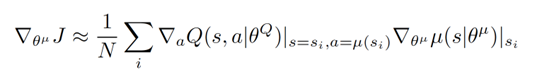
关于 Actor 部分, 他的参数更新同样会涉及到 Critic, 上面是关于 Actor 参数的更新, 它的前半部分 grad[Q] 是从 Critic 来的, 这是在说: 这次 Actor 的动作要怎么移动, 才能获得更大的 Q, 而后半部分 grad[u] 是从 Actor 来的, 这是在说: Actor 要怎么样修改自身参数, 使得 Actor 更有可能做这个动作. 所以两者合起来就是在说: Actor 要朝着更有可能获取大 Q 的方向修改动作参数了.
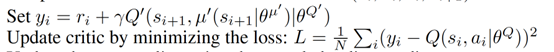
上面这个是关于 Critic 的更新, 它借鉴了 DQN 和 Double Q learning 的方式, 有两个计算 Q 的神经网络, Q_target 中依据下一状态, 用 Actor 来选择动作, 而这时的 Actor 也是一个 Actor_target (有着 Actor 很久之前的参数). 使用这种方法获得的 Q_target 能像 DQN 那样切断相关性, 提高收敛性.

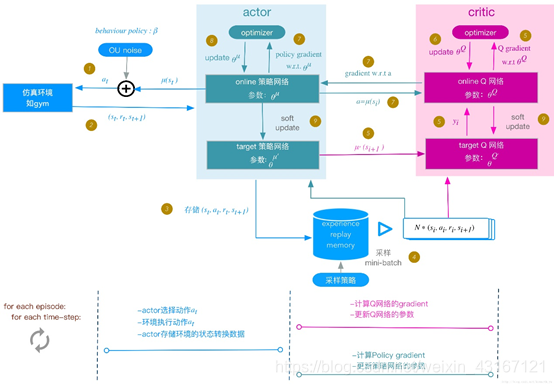
1,采取加了OU噪声的动作a
2,环境返回一系列状态,回报
3,存储到记忆
4,随机batch采样分别给actor的online和critic的online网络
5,将actor-target中采取的下个状态的动作在target网络中算出下个状态的Q值,并传给online算loss,为了Q网络学习过程更加稳定,易于收敛
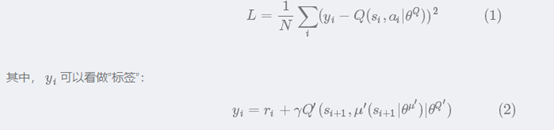
6,采取ADAM方式减小loss,更新critic的online网络
7,把Actor网络的动作给critic进行评价,采取policy-gradiant算loss
8,反向传播更新actor的online网络,采取adam的方式更新online网络
9,online算完之后,以soft= 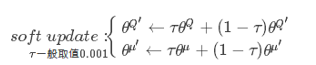 方式更新critic的Q-target网络和actor的target网络
方式更新critic的Q-target网络和actor的target网络
总结:actor(policy-gradient)这有估计网络和actor-target网络,估计(online)用来产生实时动作,在现实中实行,actor-target网络用来更新critic网络,在critic网络中,也有同样两个网络,都是输出状态的价值,输入端却不同,critic-online是拿着actor施加的动作作为输入,critic-target则是拿着actor-target的观测值加以分析
PPO/DPPO
OpenAI 提出的一种解决 Policy Gradient 不好确定 Learning rate (或者 Step size) 的问题. 因为如果 step size 过大, 学出来的 Policy 会一直乱动, 不会收敛, 但如果 Step Size 太小, 对于完成训练, 我们会等到绝望. PPO 利用 New Policy 和 Old Policy 的比例, 限制了 New Policy 的更新幅度, 让 Policy Gradient 对稍微大点的 Step size 不那么敏感.

总的来说 PPO 是一套 Actor-Critic 结构, Actor 想最大化 J_PPO, Critic 想最小化 L_BL. Critic 的 loss 好说, 就是减小 TD error. 而 Actor 的就是在 old Policy 上根据 Advantage (TD error) 修改 new Policy, advantage 大的时候, 修改幅度大, 让 new Policy 更可能发生. 而且他们附加了一个 KL Penalty,KL是个惩罚项, 简单来说, 如果 new Policy 和 old Policy 差太多, 那 KL divergence 也越大, 我们不希望 new Policy 比 old Policy 差太多, 如果会差太多, 就相当于用了一个大的 Learning rate, 这样是不好的, 难收敛.
额外知识:
信息熵:而信息熵则代表一个分布的信息量,或者编码的平均长度

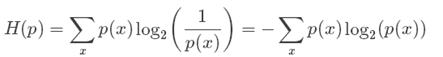
交叉熵cross-entropy:交叉熵本质上可以看成,用一个猜测的分布的编码方式去编码其真实的分布,得到的平均编码长度或者信息量
用交叉熵做损失函数的原因是:本质是衡量两个编码方式之间的差值,因为只有当猜测的分布接近于真实分布,则其值越小,比如根据自己模型得到A的概率为80%,B为20%,真实分布应该是得到A,则意味着A的概率是100%,所以
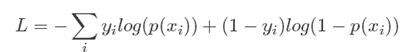
交叉熵比平方损失函数好在
1, 平方损失函数是非凸的,交叉熵是凸的
2, 交叉熵求导 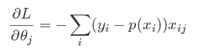
平方损失函数求导 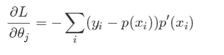
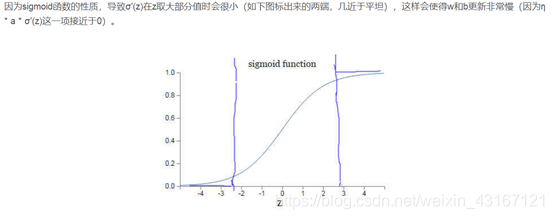
平方损失函数中会出现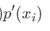 而反向求导时,a= sigmoid(wx+b)函数的导数会出现梯度消失的问题【一些人称之为饱和现象】,所以引入交叉熵,当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。,
而反向求导时,a= sigmoid(wx+b)函数的导数会出现梯度消失的问题【一些人称之为饱和现象】,所以引入交叉熵,当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。,
KL散度