1 强化学习基础知识
强化学习的数学基础是马尔可夫决策过程 (Markov Decision Processes, MDPs)。一个MDP 通常由状态空间、动作空间、状态转移矩阵、奖励函数以及折扣因子等组成。
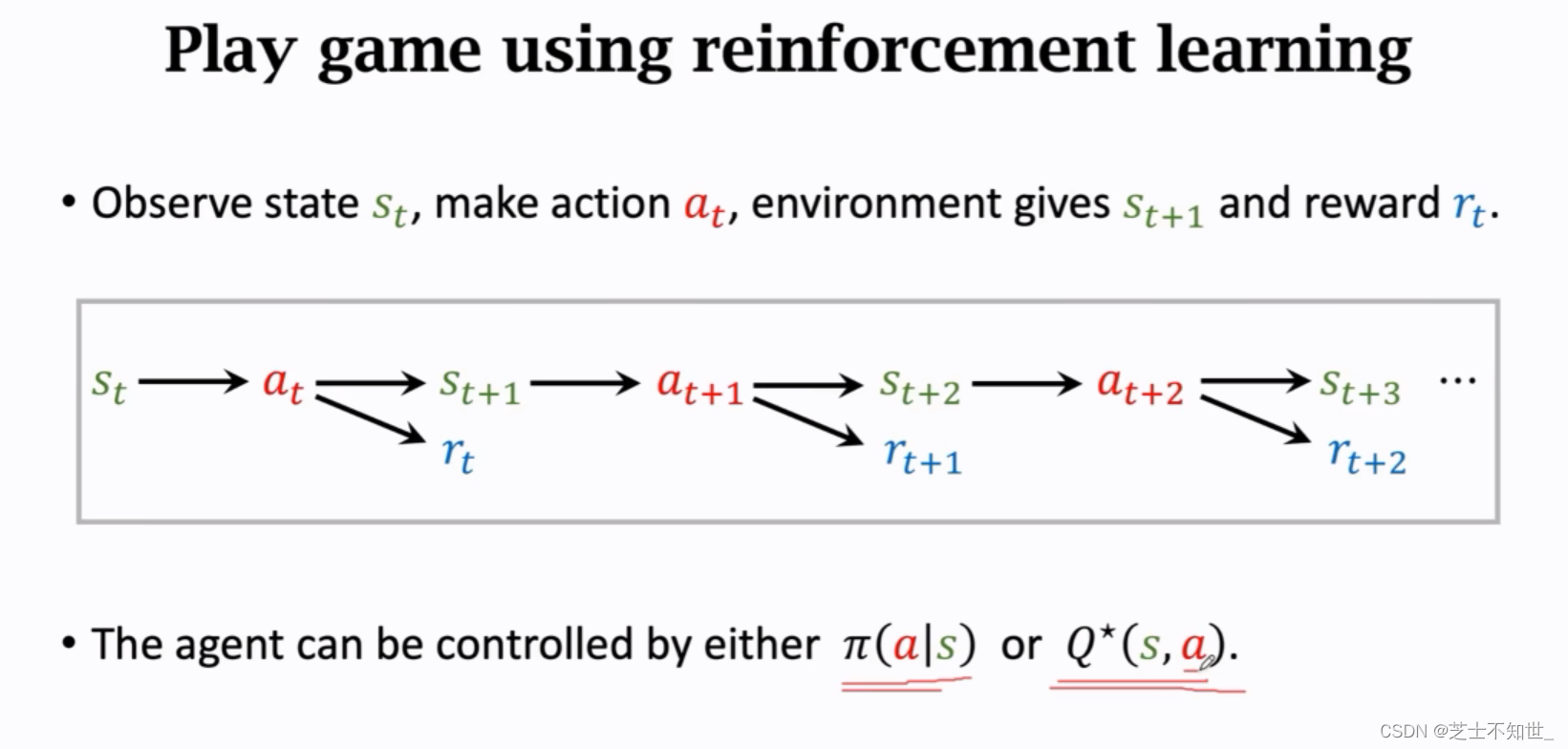
MDP过程:⾸先环境(Env)会给智能体(Agent)⼀个状态(State),智能体接收到环境给的观测值之后会做出⼀个动作(Action),环境接收到智能体给的动作之后会做出⼀系列的反应,例如对这个动作给予⼀个奖励(Reward),以及给出⼀个新的状态S。这是⼀个反复与环境进⾏交互,不断试错⼜不断进步的过程,试图找到一个决策规则(即策略)使得系统获
得最大的累积奖励值,即获得最大价值。
智能体Agent:执行任务的角色。
环境Env:任务的环境。
状态State:角色和环境所处的状态。
动作Action:角色在当前状态下做出的动作。
奖励Reward:环境根据角色的动作给出的反馈。
回报Return:每个动作的累计奖励,即未来奖励Reward的加权累计。
随机策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s):在状态S下在动作空间随机抽样给出动作a。
动作价值函数 Q π ( s ∣ a ) Q_\pi(s|a) Qπ(s∣a):给当前状态S下的动作打分,使用 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a)得出分数最高的动作a。

强化学习分类:
强化学习方法通常分为两类:基于模型的方法 (Model-Based) 和无模型方法 (Model-Free),本文主要介绍后者。无模型方法又可以分为价值学习和策略学习:
1.价值学习Q*(s|a):给状态S下各种动作打分,选择价值最大的最优动作a。——Deep Q Network(DQN) 与 Q Learning 与 SARSA
2.策略学习π(a|s):在状态S计算所有动作概率,随机抽样执行动作a。——策略网络Policy Network
3.价值学习+策略学习:Actor-Critic method 与 Advantage Actor-Critic——AC算法 与 A2C算法
强化学习实验环境OpenAI Gym:。按照官方文档安装 https://gym.openai.com/。安装之后就可以在 Python 里面调用 Gym 库中的函数了。
OpenAI Gym编码规则:智能体与环境的交互。

2 价值学习
目标:学习一个函数来近似 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a),有了 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a),智能体就可以根据 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a)来做决策,选择打分最高的动作(最大化回报 Ut 的期望)。


动作价值函数 Q π ( s ∣ a ) Q_\pi(s|a) Qπ(s∣a):对回报 U t U_t Ut求期望,即对当前状态S下的动作打分,使用最优动作价值函数 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a)得出分数最高的动作a。
2.1 DQN
Deep Q Learning(DQN) 用一个神经网络 Q ( s , a ; w ) Q(s, a; w) Q(s,a;w) 来近似 Q ∗ ( s ∣ a ) Q_*(s|a) Q∗(s∣a)函数,难点在于训练 DQN 所用的时间差分算法 (TD)——Q学习算法。
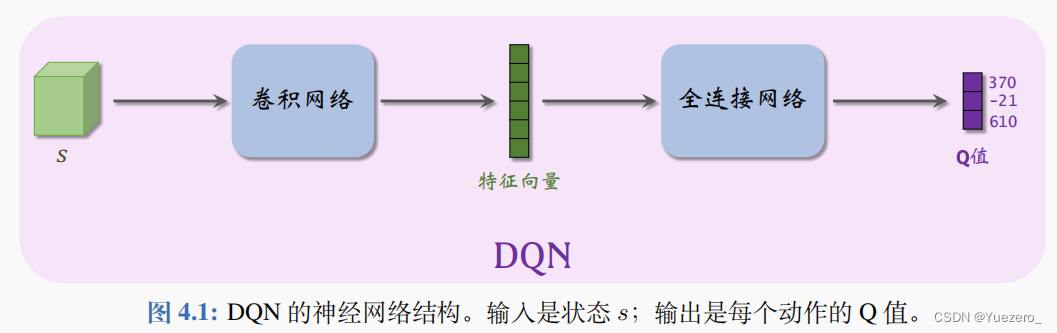
w 表示神经网络中的参数;一开始随机初始化 w,随后用“经验”去学习 w。学习的目标是:对于所有的 s 和 a,DQN 的预测 Q(s, a; w) 尽量接近 Q⋆(s, a),DQN 的输出是离散动作空间 A 上的每个动作的 Q 值,即给每个动作的评分,分数越高意味着动作越好。
TD算法训练:用 Q 学习算法 (Q learning)训练DQN。TD 算法是一大类算法,常见的有 Q 学习和 SARSA。
Q 学习的目是学到最优动作价值函数 Q⋆;SARSA的目的是学习动作价值函数 Qπ。
2.2 Q 学习算法训练DQN
Q 学习的目是学到最优动作价值函数 Q⋆;
根据回报 U t U_t Ut的定义,使用时间差TD算法得到target和prediction的关系,作差得到目标与预测的TD误差,进而计算Loss。
为了使预测prediction更接近目标target,所以应使target和prediction的差值绝对值尽可能小。
target = Q ( s t , a t ; w ) Q(s_t, a_t; w) Q(st,at;w)
prediction = r t + γ ⋅ Q ( s t + 1 , a t + 1 ; w ) r_t + \gamma·Q(s_{t+1}, a_{t+1}; w) rt+γ⋅Q(st+1,at+1;w)




注:本节推导出的是最原始的 TD算法,在实践中效果不佳。应使用高级优化技巧。
至此,每步动作都会产生对应的奖励,计算loss,计算梯度进行优化训练。

2.3 SARSA算法训练DQN
SARSA 的目的是学习动作价值函数 Qπ。
2.4 TD算法和DQN改进
两种方法改进 TD 算法,让 DQN 训练得更好。第 6.1 节介绍经验
回放 (Experience Replay) 和优先经验回放 (Prioritized Experience Replay)。
3 策略学习
目标:学习策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s),有了策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s),可以直接用 π ( a ∣ s ) \pi(a|s) π(a∣s)计算所有动作的概率值,然后随机抽样选出一个动作并执行。