hadoop中的MapReduce框架里已经预定义了相关的接口,其中如Mapper类下的方法setup()和cleanup()。
----setup()
此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。
若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
----cleanup()
此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。
若是将释放资源工作放入方法map()中,也会导 致Mapper任务在解析、处理每一行文本后释放资源,
而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
所以,建议资源初始化及释放工作,分别放入方法setup()和cleanup()中进行。
-------------------------
转自:http://f.dataguru.cn/thread-23148-1-1.html
-------------------------
下面主要对Setup函数进行深入探讨:首先看下两个程序的区别:

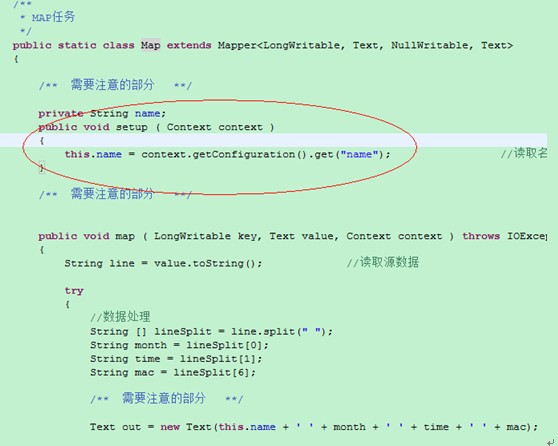
区别在于第一个程序把context这个上下文对象作为map函数的参数传到map函数中,
第二个程序则是在setup函数中处理了context对象,
从这个角度讲,在Map类的实例中是可以拿到Context这个上下文对象的,这一点是毋庸置疑的,不管是在类内部的哪个函数中使用都可以,
既然是这样,那么讨论的重点就是map这个类中方法的声明及执行了,所以分析下Mapper类的源代码:
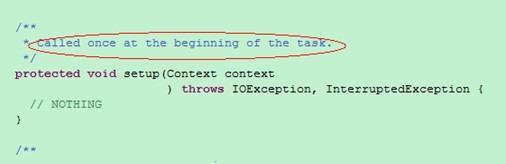
在mapper类中,只对这个方法进行了声明,也就是说它的子类可以重新实现这个方法,这一点很容易理解的。
下面从源码级分析下整个mapper类的结构和hadoop在设计这个类时的巧妙之处:
Map的主要任务就是把输入的key value转换为指定的中间结果(其实也是key value),这个类主要包括了四个函数:

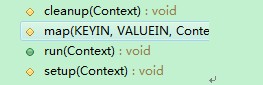
Setup一般是在执行map函数前做一些准备工作,
map是主要的数据处理函数,
cleanup则是在map执行完成后做一些清理工作和finally字句的作用很像,
下面看一下run方法:


这个方法调用了上面的三个函数,组成了setup-map-cleanup这样的执行序列,这一点和设计模式中的模版模式很类似,
当然在这里我们也可以改写它的源码,比如可以在map的时候增加多线程,这样可以对map任务做进一步的优化,
从以上的分析可以很清楚的知道setup函数的作用了。
那么还有一个小问题,我们上文中提到的Context对象是怎么回事呢?
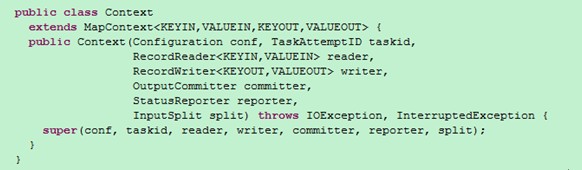
原来它是mapper的一个内部类,至于Context的继承树,这里就不再多解释了,
简单的说顶级接口是为了在map或是reduce任务中跟踪task的状态,很自然的MapContext就是记录了map执行的上下文,
在mapper类中,这个context可以存储一些job conf的信息,如的运行时参数等,
我们可以在map函数中处理这个信息,这也是hadoop中参数传递中一个很经典的例子,
同时context作为了map和reduce执行中各个函数的一个桥梁,这个设计和java web中的session对象、application对象很相似。