Mapper映射文件是一个xml格式文件,必须遵循相应的dtd文件规范,如ibatis-3-mapper.dtd。我们先大体上看看支持哪些配置?如下所示,从Eclipse里截了个屏:
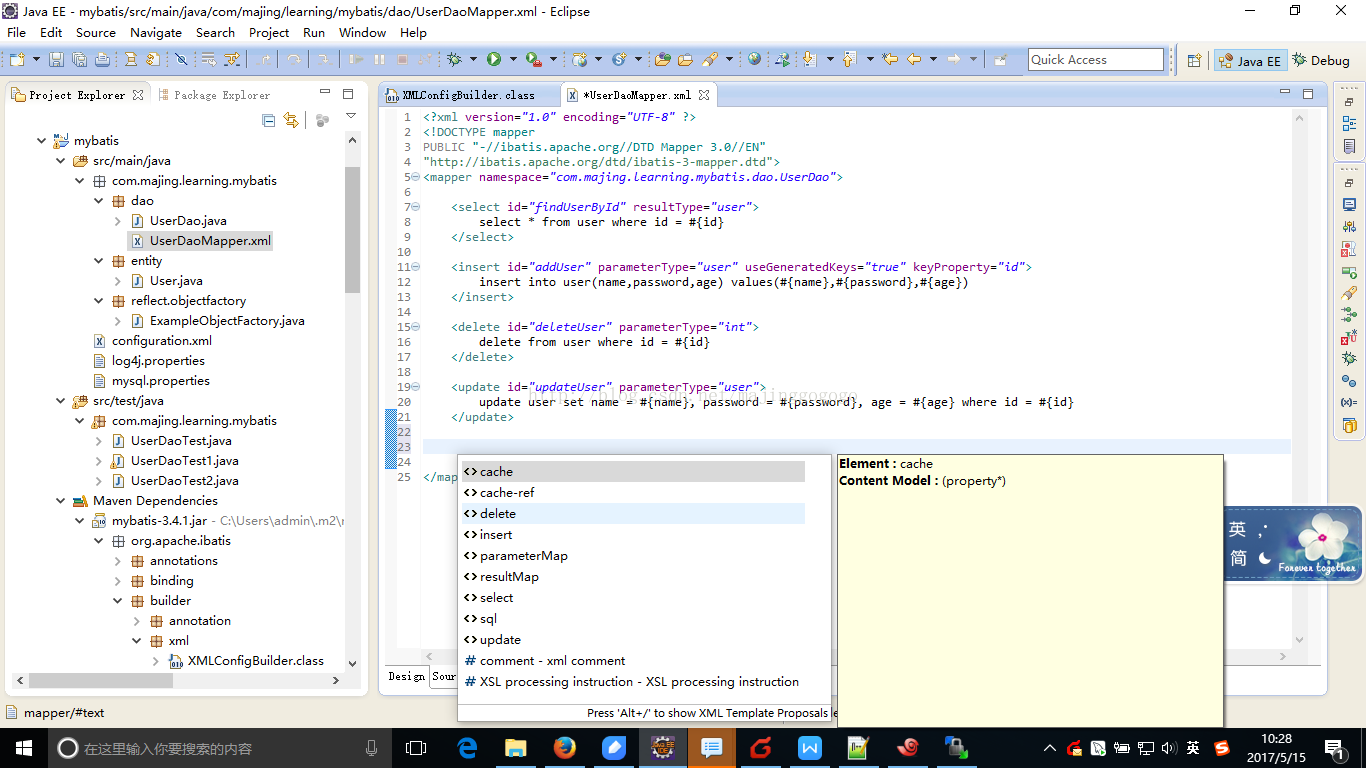
从上图可以看出,映射文件是以<mapper>作为根节点,在根节点中支持9个元素,分别为insert、update、delete、select(增删改查);cache、cache-ref、resultMap、parameterMap、sql。
下文中,我们将首先对增删改进行描述,然后对查进行详细说明,最后对其他五个元素进行简单说明。
(1)insert、update、delete
我们先从配置文件看起:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//ibatis.apache.org//DTD Mapper 3.0//EN"
"http://ibatis.apache.org/dtd/ibatis-3-mapper.dtd">
<!-- mapper 为根元素节点, 一个namespace对应一个dao -->
<mapper namespace="com.dy.dao.UserDao">
<insert
<!-- 1. id (必须配置)
id是命名空间中的唯一标识符,可被用来代表这条语句。
一个命名空间(namespace) 对应一个dao接口,
这个id也应该对应dao里面的某个方法(相当于方法的实现),因此id 应该与方法名一致 -->
id="addUser"
<!-- 2. parameterType (可选配置, 默认为mybatis自动选择处理)
将要传入语句的参数的完全限定类名或别名, 如果不配置,mybatis会通过ParameterHandler 根据参数类型默认选择合适的typeHandler进行处理
parameterType 主要指定参数类型,可以是int, short, long, string等类型,也可以是复杂类型(如对象) -->
parameterType="user"
<!-- 3. flushCache (可选配置,默认配置为true)
将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句) -->
flushCache="true"
<!-- 4. statementType (可选配置,默认配置为PREPARED)
STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 -->
statementType="PREPARED"
<!-- 5. keyProperty (可选配置, 默认为unset)
(仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 -->
keyProperty=""
<!-- 6. keyColumn (可选配置)
(仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 -->
keyColumn=""
<!-- 7. useGeneratedKeys (可选配置, 默认为false)
(仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 -->
useGeneratedKeys="false"
<!-- 8. timeout (可选配置, 默认为unset, 依赖驱动)
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。 -->
timeout="20">
<update
id="updateUser"
parameterType="user"
flushCache="true"
statementType="PREPARED"
timeout="20">
<delete
id="deleteUser"
parameterType="user"
flushCache="true"
statementType="PREPARED"
timeout="20">
</mapper>上面给出了一个比较全面的配置说明,但是在实际使用过程中并不需要都进行配置,可根据自己的需要删除部分配置项。
在这里,我列举出我自己的配置文件,精简之后是这样的:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//ibatis.apache.org//DTD Mapper 3.0//EN"
"http://ibatis.apache.org/dtd/ibatis-3-mapper.dtd">
<mapper namespace="com.majing.learning.mybatis.dao.UserDao">
<insert id="addUser" parameterType="user" useGeneratedKeys="true" keyProperty="id">
insert into user(name,password,age) values(#{name},#{password},#{age})
</insert>
<delete id="deleteUser" parameterType="int">
delete from user where id = #{id}
</delete>
<update id="updateUser" parameterType="user" >
update user set name = #{name}, password = #{password}, age = #{age} where id = #{id}
</update>
</mapper>这里的parameterType设置成user是因为如果不设置的情况下,会自动将类名首字母小写后的名称,原来的类名为User。不过,建议大家还是使用typeAlias进行配置吧。唯一需要说明的就是<insert>元素里面的useGeneratedKeys和keyProperties属性,这两个属性是用来获取数据库中的主键的。
在数据库里面经常性的会给数据库表设置一个自增长的列作为主键,如果我们操作数据库后希望能够获取这个主键该怎么弄呢?正如上面所述,如果是支持自增长的数据库,如mysql数据库,那么只需要设置useGeneratedKeys和keyProperties属性便可以了,但是对于不支持自增长的数据库(如oracle)该怎么办呢?
mybatis里面在<insert>元素下面提供了<selectKey>子元素用于帮助解决这个问题。来看下配置:
<selectKey
<!-- selectKey 语句结果应该被设置的目标属性。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 -->
keyProperty="id"
<!-- 结果的类型。MyBatis 通常可以推算出来,但是为了更加确定写上也不会有什么问题。MyBatis 允许任何简单类型用作主键的类型,包括字符串。如果希望作用于多个生成的列,则可以使用一个包含期望属性的 Object 或一个 Map。 -->
resultType="int"
<!-- 这可以被设置为 BEFORE 或 AFTER。如果设置为 BEFORE,那么它会首先选择主键,设置 keyProperty 然后执行插入语句。如果设置为 AFTER,那么先执行插入语句,然后是 selectKey 元素 - 这和像 Oracle 的数据库相似,在插入语句内部可能有嵌入索引调用。 -->
order="BEFORE"
<!-- 与前面相同,MyBatis 支持 STATEMENT,PREPARED 和 CALLABLE 语句的映射类型,分别代表 PreparedStatement 和 CallableStatement 类型。 -->
statementType="PREPARED">
</selectKey>
针对不能使用自增长特性的数据库,可以使用下面的配置来实现相同的功能:
<insert id="insertUser" parameterType="com.dy.entity.User">
<!-- oracle等不支持id自增长的,可根据其id生成策略,先获取id -->
<selectKey resultType="int" order="BEFORE" keyProperty="id">
select seq_user_id.nextval as id from dual
</selectKey>
insert into user(id, name, password, age, deleteFlag)
values(#{id}, #{name}, #{password}, #{age}, #{deleteFlag})
</insert>讲完了insert、update、delete,接下来我们看看用的比较多的select。
(2)select、resultType、resultMap
我们先来看看select元素都有哪些配置可以设置:
<select
<!-- 1. id (必须配置)
id是命名空间中的唯一标识符,可被用来代表这条语句。
一个命名空间(namespace) 对应一个dao接口,
这个id也应该对应dao里面的某个方法(相当于方法的实现),因此id 应该与方法名一致 -->
id="findUserById"
<!-- 2. parameterType (可选配置, 默认为mybatis自动选择处理)
将要传入语句的参数的完全限定类名或别名, 如果不配置,mybatis会通过ParameterHandler 根据参数类型默认选择合适的typeHandler进行处理
parameterType 主要指定参数类型,可以是int, short, long, string等类型,也可以是复杂类型(如对象) -->
parameterType="int"
<!-- 3. resultType (resultType 与 resultMap 二选一配置)
resultType用以指定返回类型,指定的类型可以是基本类型,可以是java容器,也可以是javabean -->
resultType="User"
<!-- 4. resultMap (resultType 与 resultMap 二选一配置)
resultMap用于引用我们通过 resultMap标签定义的映射类型,这也是mybatis组件高级复杂映射的关键 -->
resultMap="userResultMap"
<!-- 5. flushCache (可选配置)
将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false -->
flushCache="false"
<!-- 6. useCache (可选配置)
将其设置为 true,将会导致本条语句的结果被二级缓存,默认值:对 select 元素为 true -->
useCache="true"
<!-- 7. timeout (可选配置)
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)-->
timeout="10000"
<!-- 8. fetchSize (可选配置)
这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为 unset(依赖驱动)-->
fetchSize="256"
<!-- 9. statementType (可选配置)
STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED-->
statementType="PREPARED"
<!-- 10. resultSetType (可选配置)
FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)-->
resultSetType="FORWARD_ONLY">我们还是从具体的示例来看看,
<select id="findUserById" resultType="User">
select * from user where id = #{id}
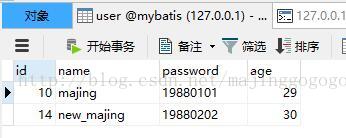
</select>这里我们根据用户id去查询这个用户的信息,resultType=User是一个别名,如果我们接触到的是这种一对一的问题,那么可以简单的定义一个实体,这个实体代表数据库表中的一条记录即可。但是如果我们遇到一对多的问题呢,就拿这里的查询用户信息来说,如果每个用户有各种兴趣,需要维护每个用户的兴趣信息,那么我们可能就存在下面的数据表结构:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
`age` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;
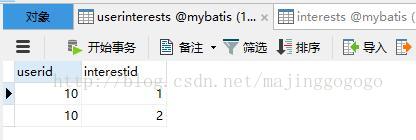
CREATE TABLE `userinterests` (
`userid` int(11) DEFAULT NULL,
`interestid` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
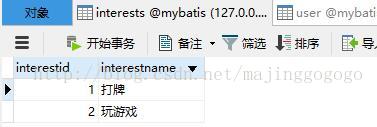
CREATE TABLE `interests` (
`interestid` int(11) NOT NULL,
`interestname` varchar(255) DEFAULT NULL,
PRIMARY KEY (`interestid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;其中user表用于记录用户信息,interests表用于维护所有的兴趣标签,而userinterests用于维护每个用户的兴趣情况。
这时候,如果我们需要根据用户id去查询用户的信息和兴趣信息该怎么做呢?这时候我们就要用到<select>中的另一个重要属性了,那就是resultMap。
在配置查询的返回结果时,resultType和resultMap是二选一的操作。对于比较复杂的查询结果,一般都会设置成resultMap。
resultMap该怎么配置呢?又支持哪些配置呢?我们看看下面:
<resultMap type="" id="">
<!-- id, 唯一性,注意啦,这个id用于标示这个javabean对象的唯一性, 不一定会是数据库的主键(不要把它理解为数据库对应表的主键)
property属性对应javabean的属性名,column对应数据库表的列名
(这样,当javabean的属性与数据库对应表的列名不一致的时候,就能通过指定这个保持正常映射了)
-->
<id property="" column=""/>
<!-- result与id相比, 对应普通属性 -->
<result property="" column=""/>
<!--
constructor对应javabean中的构造方法
-->
<constructor>
<!-- idArg 对应构造方法中的id参数 -->
<idArg column=""/>
<!-- arg 对应构造方法中的普通参数 -->
<arg column=""/>
</constructor>
<!--
collection,对应javabean中容器类型, 是实现一对多的关键
property 为javabean中容器对应字段名
column 为体现在数据库中列名
ofType 就是指定javabean中容器指定的类型
-->
<collection property="" column="" ofType=""></collection>
<!--
association 为关联关系,是实现N对一的关键。
property 为javabean中容器对应字段名
column 为体现在数据库中列名
javaType 指定关联的类型
-->
<association property="" column="" javaType=""></association>
</resultMap>根据上面的说明,我们来看看之前的问题怎么解决?
先截图给出三个表的数据情况:
接着,我们来定义兴趣类,并改写之前的用户实体类
package com.majing.learning.mybatis.entity;
public class Interests {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Interests [id=" + id + ", name=" + name + "]";
}
}package com.majing.learning.mybatis.entity;
import java.util.List;
public class User2 {
private int id;
private String name;
private String password;
private int age;
private List<Interests> interests;
private String author;
public List<Interests> getInterests() {
return interests;
}
public void setInterests(List<Interests> interests) {
this.interests = interests;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User2 [id=" + id + ", name=" + name + ", password=" + password + ", age=" + age + ", interests=" + interests + ", author=" + author + "]";
}
}
紧接着,我们改写Dao接口:
package com.majing.learning.mybatis.dao;
import com.majing.learning.mybatis.entity.User2;
public interface UserDao2 {
/**
* 查询
* @param userId
* @return
*/
User2 findUserById (int userId);
}
然后,我们给相关实体类创建一下别名:
<typeAliases>
<typeAlias alias="UserWithInterests" type="com.majing.learning.mybatis.entity.User2"/>
<typeAlias alias="Interests" type="com.majing.learning.mybatis.entity.Interests"/>
</typeAliases>然后再创建一个对应跟UserDao2对应的Mapper映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//ibatis.apache.org//DTD Mapper 3.0//EN"
"http://ibatis.apache.org/dtd/ibatis-3-mapper.dtd">
<mapper namespace="com.majing.learning.mybatis.dao.UserDao2">
<resultMap type="UserWithInterests" id="UserWithInterestsMap">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="password" column="password"/>
<result property="age" column="age"/>
<collection property="interests" column="interestname" ofType="Interests">
<id property="id" column="interestid"/>
<result property="name" column="interestname"/>
</collection>
</resultMap>
<select id="findUserById" resultMap="UserWithInterestsMap">
select a.*,c.* from user as a right join userinterests as b on a.id = b.userid right join interests as c on b.interestid = c.interestid where id = #{id}
</select>
</mapper>最后将这个映射文件添加到<mappers>元素配置下:
<mappers>
<mapper resource="com\majing\learning\mybatis\dao\UserDaoMapper.xml" />
<mapper resource="com\majing\learning\mybatis\dao\UserDao2Mapper.xml" />
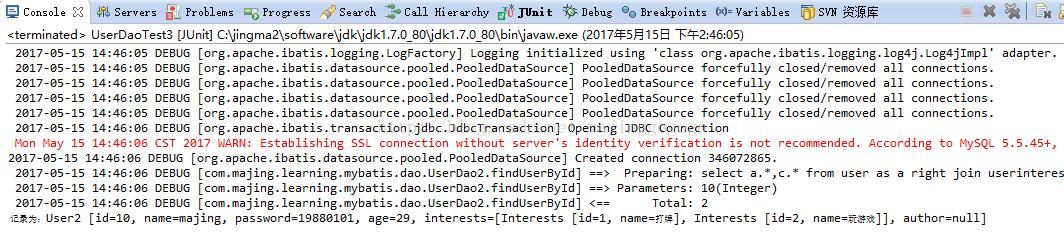
</mappers>下面我们来写个测试代码来测试一下是否可以正常运行:
public class UserDaoTest3 {
@Test
public void testFindUserById(){
SqlSession sqlSession = getSessionFactory().openSession(true);
UserDao2 userMapper = sqlSession.getMapper(UserDao2.class);
User2 user = userMapper.findUserById(10);
System.out.println("记录为:"+user);
}
// Mybatis 通过SqlSessionFactory获取SqlSession, 然后才能通过SqlSession与数据库进行交互
private static SqlSessionFactory getSessionFactory() {
SqlSessionFactory sessionFactory = null;
String resource = "configuration.xml";
try {
sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader(resource));
} catch (IOException e) {
e.printStackTrace();
}
return sessionFactory;
}
}运行代码后,我们可以看到成功啦!
(3)sql
sql元素的意义,在于我们可以定义一串SQL语句,其他的语句可以通过引用它而达到复用它的目的。因为平时用到的也不多,这里就不多介绍了,感兴趣的朋友可以自行查阅资料了解一下。
(4)cache、cache-ref
关于缓存的这块逻辑还没有研究过,后面专门写篇文章针对缓存进行针对性的说明,敬请关注。
至此,关于mapper映射文件的相关配置和使用讲解的便差不多了,希望对大家有所帮助。