问题1、什么是端到端的深度学习?
https://blog.csdn.net/junjun_zhao/article/details/79184743
端到端深度学习
定义:
相对于传统的一些数据处理系统或者学习系统,它们包含了多个阶段的处理过程,而端到端的深度学习则忽略了这些阶段,用单个神经网络来替代。
语音识别例子:
在少数据集的情况下传统的特征提取方式可能会取得好的效果;如果在有足够的大量数据集情况下,端到端的深度学习会发挥巨大的价值。

优缺点:
优点:
- 端到端学习可以直接让数据“说话”;
- 所需手工设计的组件更少。
缺点:
- 需要大量的数据;
- 排除了可能有用的手工设计组件。
非端到端学习(传统的语音识别系统)
传统的语音识别需要把语音转换成语音特征向量,然后把这组向量通过机器学习,分类到各种音节上(根据语言模型),然后通过音节,还原出最大概率的语音原本要表达的单词,一般包括以下模块:
- 特征提取模块 (Feature Extraction):该模块的主要任务是从输入信号中提取特征,供声学模型处理。一般也包括了一些信号处理技术,尽可能降低环境噪声、说话人等因素对特征造成的影响,把语音变成向量。
- 声学模型 (Acoustic Model): 用于识别语音向量
- 发音词典 (Pronnuciation Dictionary):发音词典包含系统所能处理的词汇集及其发音。发音词典提供了声学模型与语言模型间的联系。
- 语言模型 (Language Model):语言模型对系统所针对的语言进行建模。
- 解码器 (Decoder):任务是对输入的信号,根据声学、语言模型及词典,寻找能够以最大概率输出该信号的词串。
传统的语音识别中的语音模型和语言模型是分别训练的,缺点是不一定能够总体上提高识别率。
例1:
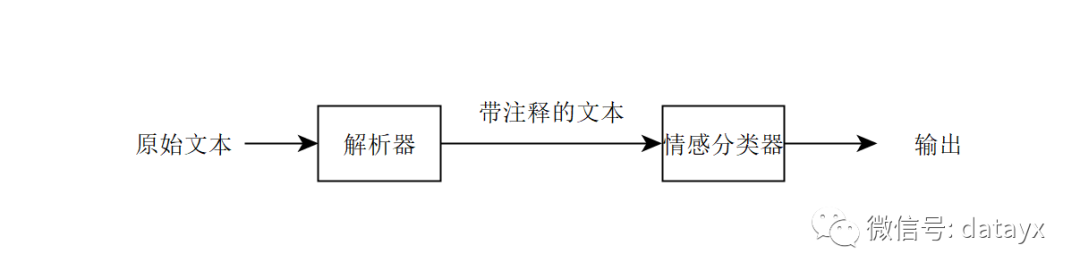
端到端学习算法:

例2:

端到端学习算法:

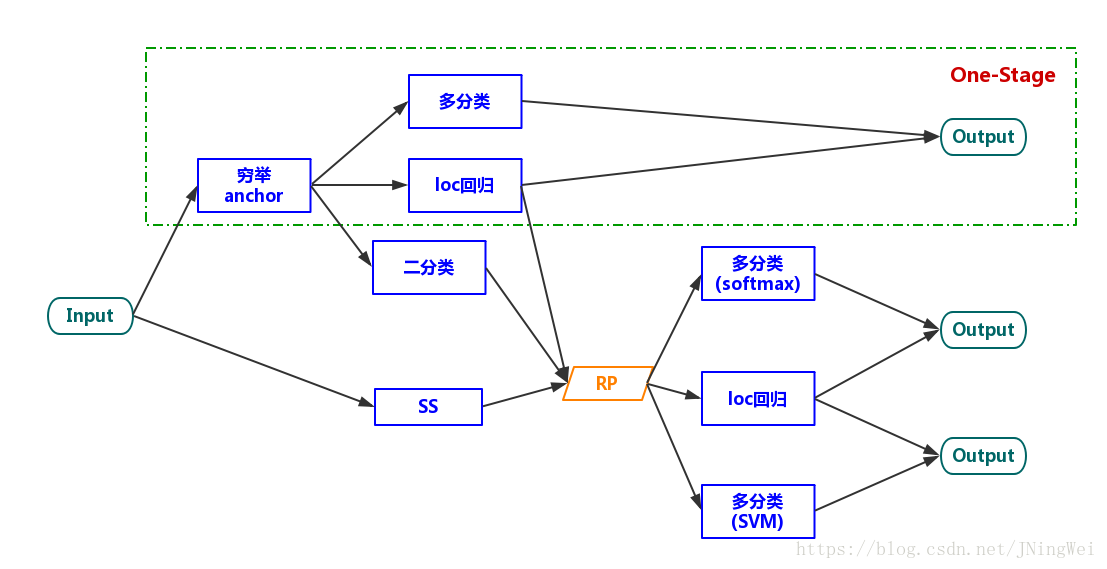
问题2、目标检测算法有哪几类,各有什么特点?
https://blog.csdn.net/JNingWei/article/details/80039079

Detection算法的几个task
-
对于不需要预生成RP的Detection算法而言,算法只需要完成三个任务:
- 特征抽取
- 分类
- 定位回归
-
对于有预生成RP的Detection算法而言,算法要完成的主要有四个任务:
- 特征抽取
- 生成RP
- 分类
- 定位回归
Detection算法的框架套路
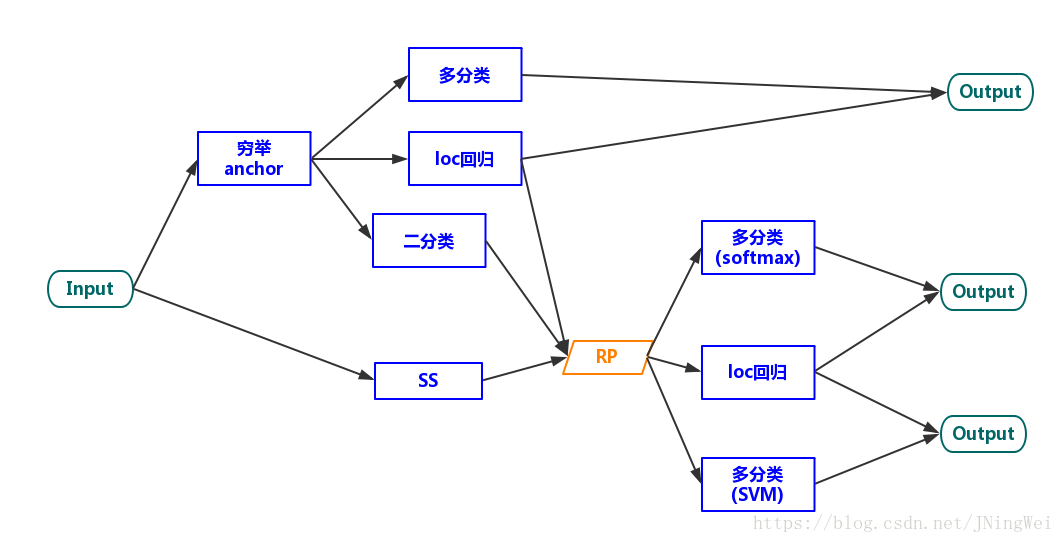
multi-stage 算法
最早期的检测算法 (主要为R-CNN、SPPNet) 都属于multi-stage系。这个时候的Selective Serach、Feature extraction、location regressor、cls SVM是分成多个stage来各自单独train的。故谓之曰“multi-stage”:
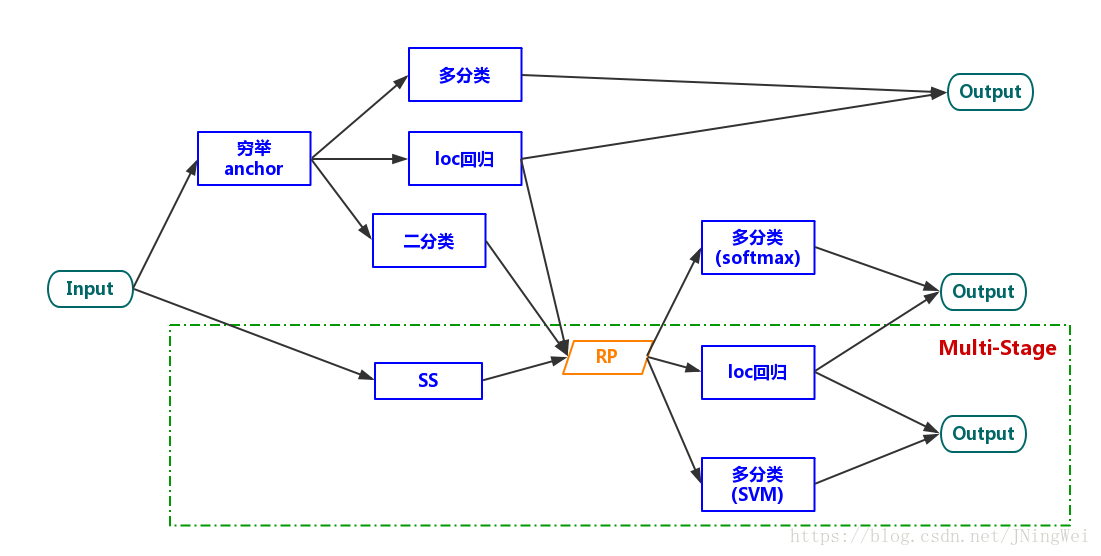
two-stage 算法
到了Fast R-CNN的时候,Feature extraction、location regressor、cls SVM都被整合到了一个network里面,可以实现这三个task一起train了。由于生成RP的task还需要另外train,故谓之曰“two-stage”:
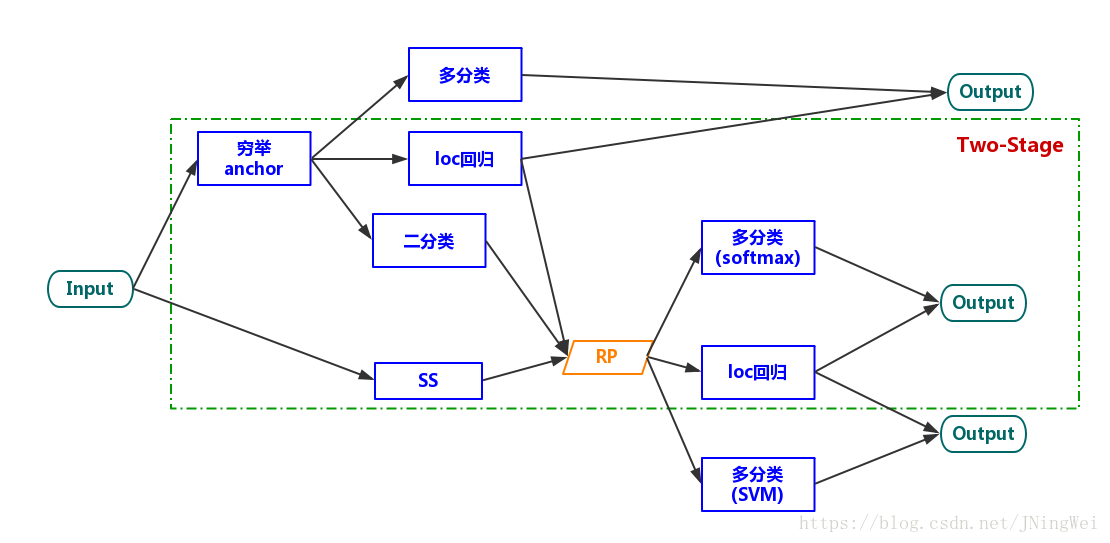
到了Faster R-CNN中,虽然RPN的出现使得四个task可以一起被train,但是依然被归类为“two-stage”。(这个地方我也不是很理解。)
one-stage 算法
在YOLOv1中,“生成RP”这一任务被直接丢弃了。因此,整个算法只剩下了一个stage,故谓之曰“one-stage”:
参考: