1. np.loadtxt
代码段1
// An highlighted block
import numpy as np
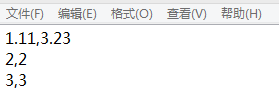
filepath = open('E:/1.txt')
#从文件中读取数据,读取第0列和第1列,要求文件中每一行的列数相等
dataset = np.loadtxt(filepath, delimiter=',',usecols=(0,1))
Xdata = dataset[:, 0]
Ydata = dataset[:, 1]
结果:
>>>dataset
array([[1.11, 3.23],
[2. , 2. ],
[3. , 3. ]])
>>>Xdata
array([1.11, 2. , 3. ])
代码段2(unpack=True)
// An highlighted block
import numpy as np
filepath = open('E:/1.txt')
#从文件中读取数据,读取第0列和第1列,要求文件中每一行的列数相等
dataset = np.loadtxt(filepath, delimiter=',', usecols=(0, 1), unpack=True)
Xdata = dataset[0]
Ydata = dataset[1]
结果:
>>>dataset
array([[1.11, 2. , 3. ],
[3.23, 2. , 3. ]])
>>>Xdata
array([1.11, 2. , 3. ]
2. np.dot, np.std, np.mean
代码段2(unpack=True)
// np.dot就是一般的矩阵乘法,A(m**n),B(n**m),A**B(m**m)
import numpy as np
a = [[1,2,3],[1,3,4]]
b = [[2,1,1],[3,1,1]]
>>>np.dot(a,np.transpose(b))
array([[ 7, 8],
[ 9, 10]])
//np.std求矩阵全局标准差
>>>np.std(a, axis=0)
array([0. , 0.5, 0.5])
//axis=0求矩阵每一列标准差,axis=1求矩阵每一行的标准差
>>>np.std(a)
1.1055415967851334
//np.mean求矩阵均值
>>>np.mean(a, axis=0)
array([1. , 2.5, 3.5])
2. np.add, np.subtract, np.multipy,np.divide
矩阵的点运算,加减乘除
3. np.linspace
// An highlighted block
>>> np.linspace(2.0, 3.0, num=5)
array([ 2. , 2.25, 2.5 , 2.75, 3. ])
>>> np.linspace(2.0, 3.0, num=5, endpoint=False)
array([ 2. , 2.2, 2.4, 2.6, 2.8])
>>> np.linspace(2.0, 3.0, num=5, retstep=True)
(array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
4. np.shape 生成与矩阵a同样大小的矩阵
a = np.array([[1,2,3],[4,5,6]])
b = np.zeros(a.shape)
b
array([[0., 0., 0.],
[0., 0., 0.]])
5. np.logspace
np.logspace()常用于创建等比数列,底数为1,它也有常用的3个参数,第一个参数表示起始点的指数,第二个参数终止点的指数,第三个参数表示数列的个数;
>>>np.logspace(1,10,10)
array([1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07, 1.e+08,
1.e+09, 1.e+10])