深度学习的人脸识别技术发展综述
目录
前言
LFW数据集(Labeled Faces in the Wild)是目前用得最多的人脸图像数据库。该数据库共13,233幅图像,其中5749个人,其中1680人有两幅及以上的图像,4069人只有一幅图像。图像为250*250大小的JPEG格式。绝大多数为彩色图,少数为灰度图。该数据库采集的是自然条件下人脸图片,目的是提高自然条件下人脸识别的精度。该数据集有6中评价标准:
一,Unsupervised;
二,Image-restricted with no outside data;
三,Unrestricted with no outside data;
四,Image-restricted with label-free outside data;
五,Unrestricted with label-free outside data;
六,Unrestricted with labeled outside data。
目前,人工在该数据集上的准确率在0.9427~0.9920。在该数据集的第六种评价标准下(无限制,可以使用外部标注的数据),许多方法已经赶上(超过)人工识别精度,比如face++,DeepID3,FaceNet等。
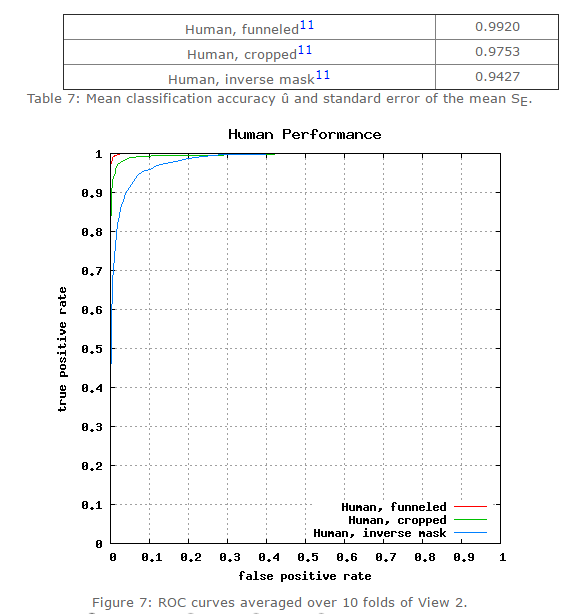
![]()
图一/表一:人类在LFW数据集上的识别精度
表二:第六种标准下,部分模型的识别准确率(详情参见lfw结果)
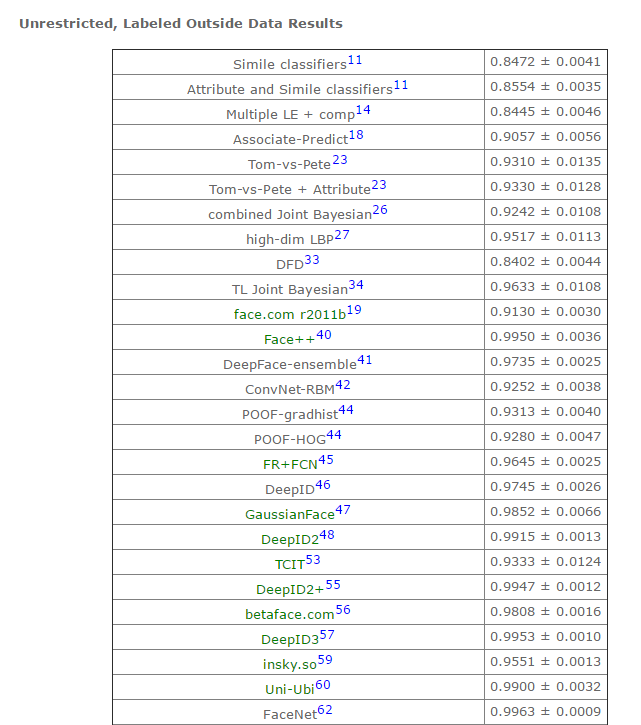
![]()
续上表
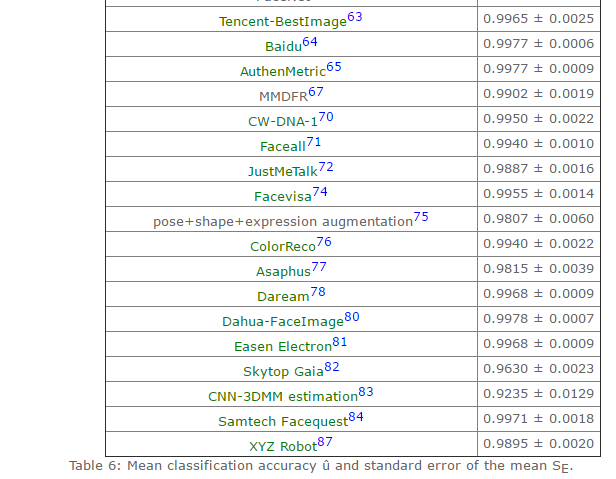
![]()
本文综述的人脸识别方法包括以下几个筛选标准:一,在上表中识别精度超过0.95(超过人类的识别准确度);二,公布了方法(部分结果为商业公司提交,方法并未公布,比如Tencent-BestImage);三,使用深度学习方法(本人是深度学习的追随者);三,近两年的结果。本文综述的方法包括:1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 ,准确率没那么高,但是值得参考)。
人脸识别方法
1,face++(0.9950)
参考文献:Naive-Deep face Recognition: Touching the Limit of LFW Benchmark or Not?
face++从网络上搜集了5million张人脸图片用于训练深度卷积神经网络模型,在LFW数据集上准确率非常高。该篇文章的网路模型很常规(常规深度卷积神经网络模型),但是提出的问题是值得参考的。
问题一:他们的Megvii Face Recognition System经过训练后,在LFW数据集上达到了0.995的准确率。在真实场景测试中(Chinese ID (CHID)),该系统的假阳性率(![]() )非常低。但是,真阳性率仅为0.66,没有达到真实场景应用要求。其中,年龄差异(包括intra-variation:同一个人,不同年龄照片;以及inter-variation:不同人,不同年龄照片)是影响模型准确率原因之一。而在该测试标准(CHID)下,人类表现的准确率大于0.90.
)非常低。但是,真阳性率仅为0.66,没有达到真实场景应用要求。其中,年龄差异(包括intra-variation:同一个人,不同年龄照片;以及inter-variation:不同人,不同年龄照片)是影响模型准确率原因之一。而在该测试标准(CHID)下,人类表现的准确率大于0.90.

![]()
图1-1:在CHID中出错的样本
问题二:数据采集偏差。基于网络采集的人脸数据集存在偏差。这些偏差表现在:1,个体之间照片数量差异很大;2,大部分采集的照片都是:微笑,化妆,年轻,漂亮的图片。这些和真实场景中差异较大。因此,尽管系统在LFW数据集上有高准确率,在现实场景中准确率很低。
问题三:模型测试加阳性率非常低,但是现实应用中,人们更关注真阳性率。
问题四:人脸图片的角度,光线,闭合(开口、闭口)和年龄等差异相互的作用,导致人脸识别系统现实应用准确率很低。
因此,该文章提出未来进一步研究的方向。方向一:从视频中提取训练数据。视频中人脸画面接近于现实应用场景(变化的角度,光照,表情等);方向二:通过人脸合成方法增加训练数据。因为单个个体不同的照片很困难(比如,难以搜集大量的单个个体不同年龄段的照片,可以采用人脸合成的方法(比如3D人脸重建)生成单个个体不同年龄段的照片)。该文章提出的方向在后续方法介绍中均有体现。
2,DeepFace(0.9735 )
参考文献:Deepface: Closing the gap to humal-level performance in face verification
2.1 简介
常规人脸识别流程是:人脸检测-对齐-表达-分类。本文中,我们通过额外的3d模型改进了人脸对齐的方法。然后,通过基于4million人脸图像(4000个个体)训练的一个9层的人工神经网络来进行人脸特征表达。我们的模型在LFW数据集上取得了0.9735的准确率。该文章的亮点有以下几点:一,基于3d模型的人脸对齐方法;二,大数据训练的人工神经网络。
2.2 人脸对齐方法
文中使用的人脸对齐方法包括以下几步:1,通过6个特征点检测人脸;2,剪切;3,建立Delaunay triangulation;4,参考标准3d模型;5,将3d模型比对到图片上;6,进行仿射变形;7,最终生成正面图像。

![]()
图2-1 人脸对齐的流程
2.3 深度神经网络

![]()
图2-2:深度神经网络
2.4 结果
该模型在LFW数据集上取得了0.9735准确率,在其它数据集比如Social Face Classification (SFC) dataset和YouTube Faces (YTF) dataset也取得了好结果,详情请参见原文。
3,FR+FCN(0.9645 )
参考文献:Recover Canonical-View Faces in the Wild with Deep Neural Networks
3.1 简介
自然条件下,因为角度,光线,occlusions(咬合/张口闭口),低分辨率等原因,使人脸图像在个体之间有很大的差异,影响到人脸识别的广泛应用。本文提出了一种新的深度学习模型,可以学习人脸图像看不见的一面。因此,模型可以在保持个体之间的差异的同时,极大的减少单个个体人脸图像(同一人,不同图片)之间的差异。与当前使用2d环境或者3d信息来进行人脸重建的方法不同,该方法直接从人脸图像之中学习到图像中的规则观察体(canonical view,标准正面人脸图像)。作者开发了一种从个体照片中自动选择/合成canonical-view的方法。在应用方面,该人脸恢复方法已经应用于人脸核实。同时,该方法在LFW数据集上获得了当前最好成绩。该文章的亮点在于:一,新的检测/选择canonical-view的方法;二,训练深度神经网络来重建人脸正面标准图片(canonical-view)。
3.2 canonical view选择方法
我们设计了基于矩阵排序和对称性的人脸正面图像检测方法。如图3-1所示,我们按照以下三个标准来采集个体人脸图片:一,人脸对称性(左右脸的差异)进行升序排列;二,图像锐度进行降序排列;三,一和二的组合。

![]()
图3-1 正面人脸图像检测方法
矩阵![]() 为第i个个体的人脸图像矩阵,
为第i个个体的人脸图像矩阵,![]() 为第i个个体所有人脸图像集合,
为第i个个体所有人脸图像集合,![]() 。正面人脸检测公式为:
。正面人脸检测公式为:![]() 。
。
3.3 人脸重建
我们通过训练深度神经网络来进行人脸重建。loss函数为:![]()
i为第i个个体,k为第i个个体的第k张样本。![]() 和Y为训练图像和目标图像。
和Y为训练图像和目标图像。
如图3-2所示,深度神经网络包含三层。前两层后接上了max pooling;最后一层接上了全连接层。于传统卷积神经网络不同,我们的filters不共享权重(我们认为人脸的不同区域存在不同类型的特征)。第l层卷积层可以表示为:
![]()

![]()
图3-2 深度神经网络
最终,经过训练的深度神经网络生成的canonical view人脸图像如图3-3所示。

![]()
图3-3 canonical view人脸图像
4,DeepID(0.9745 )
参考文献:DeepID3: Face Recognition with Very Deep Neural Networks
4.1 简介
深度学习在人脸识别领域的应用提高了人脸识别准确率。本文中,我们使用了两种深度神经网络框架(VGG net 和GoogleLeNet)来进行人脸识别。两种框架ensemble结果在LFW数据集上可以达到0.9745的准确率。文章获得高准确率主要归功于大量的训练数据,文章的亮点仅在于测试了两种深度卷积神经网络框架。
4.2 深度神经网络框架
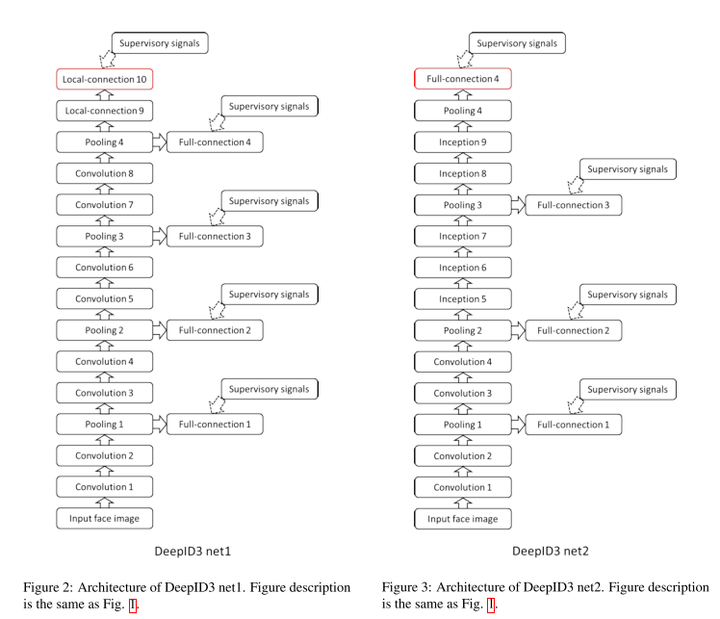
![]()
图4-1 两种深度卷积神经网络框架
5,FaceNet(0.9963)
参考文献:FaceNet: A Unified Embedding for Face Recognition and Clustering
5.1 简介
作者开发了一个新的人脸识别系统:FaceNet,可以直接将人脸图像映射到欧几里得空间,空间的距离代表了人脸图像的相似性。只要该映射空间生成,人脸识别,验证和聚类等任务就可以轻松完成。该方法是基于深度卷积神经网络,在LFW数据集上,准确率为0.9963,在YouTube Faces DB数据集上,准确率为0.9512。FaceNet的核心是百万级的训练数据以及 triplet loss。
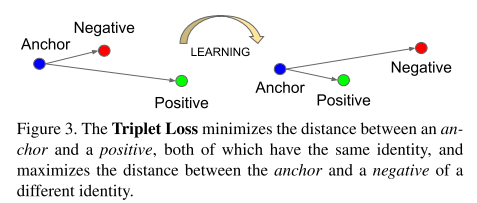
5.2 triplet loss
triplet loss是文章的核心,模型将图像x embedding入d-维的欧几里得空间![]() 。我们希望保证某个个体的图像
。我们希望保证某个个体的图像![]() 和该个体的其它图像
和该个体的其它图像![]() 距离近,与其它个体的图像
距离近,与其它个体的图像![]() 距离远。如图5-1所示:
距离远。如图5-1所示:
![]()
图5-1 triplet loss示意图
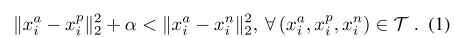
![]()
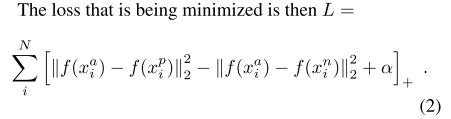
![]()
triplets 的选择对模型的收敛非常重要。如公式1所示,对于![]() ,我们我们需要选择不同个体的图片
,我们我们需要选择不同个体的图片![]() ,使
,使![]() ;同时,还需要选择同一个体不同图片
;同时,还需要选择同一个体不同图片![]() ,使得
,使得![]() 。
。
5.3 深度卷积神经网络
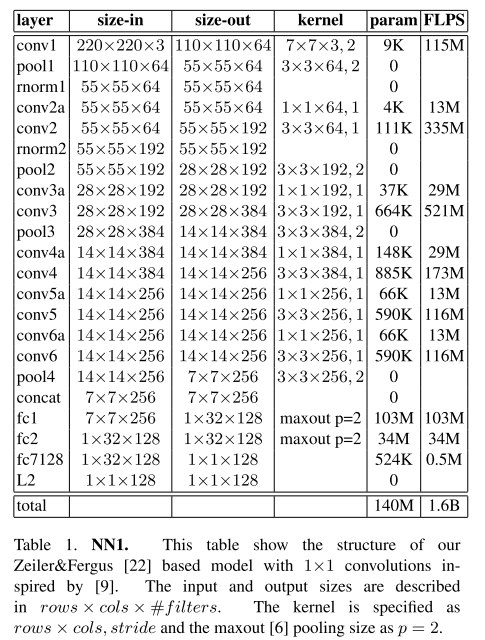
采用adagrad优化器,使用随机梯度下降法训练CNN模型。在cpu集群上训练了1000-2000小时。边界值![]() 设定为0.2。总共实验了两类模型,参数如表5-1和表5-2所示。
设定为0.2。总共实验了两类模型,参数如表5-1和表5-2所示。
表5-1 CNN模型1
![]()
表5-2 CNN模型2
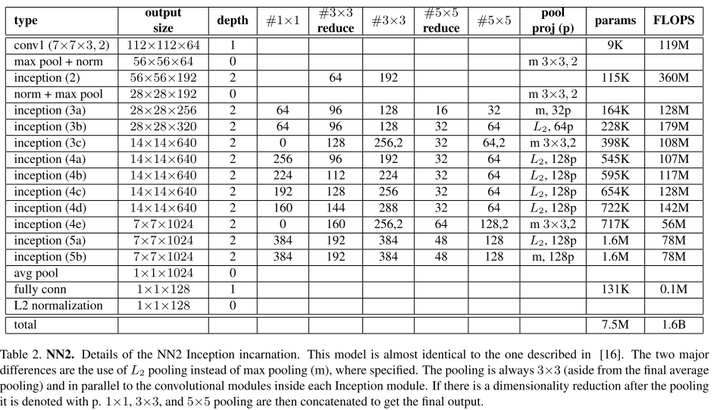
![]()
6,baidu的方法
参考文献:Targeting Ultimate Accuracy : Face Recognition via Deep Embedding
6.1 简介
本文中,作者提出了一种两步学习方法,结合mutil-patch deep CNN和deep metric learning,实现脸部特征提取和识别。通过1.2million(18000个个体)的训练集训练,该方法在LFW数据集上取得了0.9977的成绩。
6.2 multi-patch deep CNN
人脸不同区域通过深度卷积神经网络分别进行特征提取。如图6-1所示。
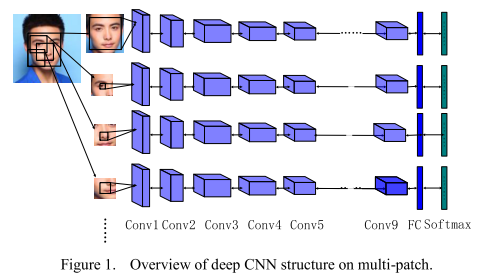
![]()
图6-1 multi-patch示意图
6.3 deep metric learning
深度卷积神经网络提取的特征再经过metric learning将维度降低到128维度,如图7-2所示。
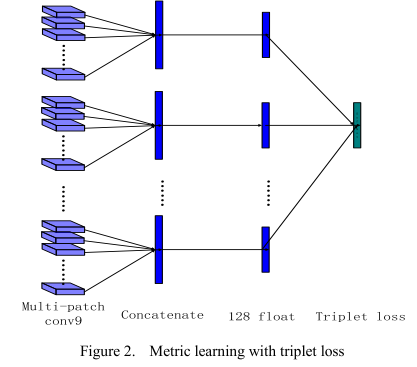
![]()
图6-2 metric learning示意图
7,pose+shape+expression augmentation(0.9807)
参考文章:Do We Really Need to Collect Millions of Faces for Effective Face Recognition
7.1 简介
该文章的主要思路是对数据集进行扩增(data augmentation)。CNN深度学习模型,比如face++,DeepID,FaceNet等需要基于百万级人脸图像的训练才能达到高精度。而搜集百万级人脸数据所耗费的人力,物力,财力是很大的,所以商业公司使用的图像数据库是不公开的。
本文中,采用了新的人脸数据扩增方法。对现有公共数据库人脸图像,从pose,shape和expression三个方面合成新的人脸图像,极大的扩增数据量。在LFW和IJB-A数据集上取得了和百万级人脸数据训练一样好的结果。该文章的思路很好,很适合普通研究者。
7.2 pose+shape+expression扩增方法
一,pose(姿态,文章中为人脸角度,即通过3d人脸模型数据库合成图像看不见的角度,生成新的角度的人脸)。首先,通过人脸特征点检测(facial landmark detector),获取人脸特征点。根据人脸特征点和开放的Basel 3D face set数据库的人脸模板合成3d人脸。如图7-1所示。

![]()
图7-1 pose(角度)生成示意图
二,shape(脸型)。首先,通过Basel 3D face获取10种高质量3d面部扫描数据。再将图像数据与不同3d脸型数据结合,生成同一个人不同脸型的图像。如图7-2所示:
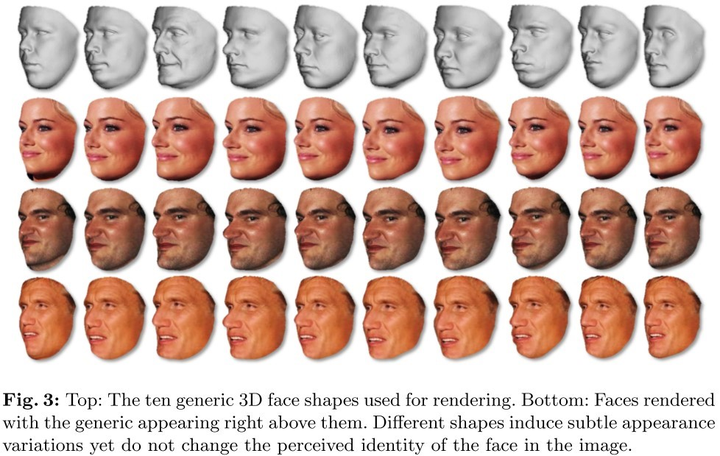
![]()
图7-2 不同脸型生成示意图
三,expression(表情,本文中,将图像的张嘴表情替换为闭口表情)。采用中性嘴型将图像中的开口表情换位闭口表情。如图7--3所示。

![]()
图7-3 不同表情(开口/闭口)生成示意图
7.3 模型及训练方法
文章模型采用的ILSVRC数据集上预训练的VGG-19模型。训练方法是常规梯度下降训练方法。值得提出的地方是,该文章对测试集也进行了augmentation。
8, CNN-3DMM estimation(0.9235)
参考文献:
1,Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network(很优秀的工作,强烈推荐阅读原文)
2,中文解析:使用深度卷积神经网络方法进行3D人脸重建
8.1 简介
当在真实场景中应用3d模拟来增加人脸识别精度,存在两类问题:要么3d模拟不稳定,导致同一个个体的3d模拟差异较大;要么过于泛化,导致大部分合成的图片都类似。因此,作者研究了一种鲁棒的三维可变人脸模型(3D morphable face models (3DMM))生成方法。他们采用了卷积神经网络(CNN)来根据输入照片来调节三维人脸模型的脸型和纹理参数。该方法可以用来生成大量的标记样本。该方法在MICC数据集上进行了测试,精确度为state of the art 。与3d-3d人脸比对流程相结合,作者在LFW,YTF和IJB-A数据集上与当前最好成绩持平。文章的关键点有两个:一,3D重建模型训练数据获取;二,3D重建模型训练 。
8.2 训练数据
作者采用了近期发表的多图像3DMM生成方法(M.Piotraschke 2016)。他们在CASIA WebFace数据集上采用该方法生成3DMM。这些3d人脸模型用于训练CNN的gound truth。多图像3DMM重建包括两步:一,从CASIA数据集选取500K当个图像来估计3DMM参数。二,同一个体不同照片生成的3DMM聚合一起,获取单个个体的3DMM(约10K个体)。
8.2.1 Single image 3DMM fitting
采用两种不同的方法来对每一个训练图片配对上3DMM。对于图像I,我们估计![]() 和
和![]() 来表示与输入图像I类似的图像。采用了目前最好的人脸特征点检测器(CLNF)来检测K=68个人脸特征点
来表示与输入图像I类似的图像。采用了目前最好的人脸特征点检测器(CLNF)来检测K=68个人脸特征点![]() 和置信值
和置信值![]() 。其中,脸部特征点用于在3DMM坐标系中初始化输入人脸的角度。角度表达为6个自由度:角度
。其中,脸部特征点用于在3DMM坐标系中初始化输入人脸的角度。角度表达为6个自由度:角度![]() 和平移
和平移![]() 。然后再对脸型,纹理,角度,光照和色彩进行处理。
。然后再对脸型,纹理,角度,光照和色彩进行处理。
8.2.2 Multi image 3DMM fitting
多图像3DMM生成通过pool 单个个体不同图片生成的3DMM的脸型和纹理参数来实现。![]() 其中
其中![]() ,
,![]() 为CLNF脸部特征检测生成的置信值。
为CLNF脸部特征检测生成的置信值。
8.3 3D重建模型训练
对于数据集中每一个个体,有多张图片以及单个pool的3DMM。我们将该数据用于训练模型,使模型可以根据同一个体不同的图片来生成类似的3DMM特征向量。
如图8-1所示,我们采用了101层的deep ResNet网络来进行人脸识别。神经网络的输出层为198维度的3DMM特征向量![]() 。然后,使用CASIA 图像生成的pooled 3DMM作为目标值对神经网络进行fine-tuned。我们也尝试了使用VGG-16结构,结果比ResNet结构稍微差一点。
。然后,使用CASIA 图像生成的pooled 3DMM作为目标值对神经网络进行fine-tuned。我们也尝试了使用VGG-16结构,结果比ResNet结构稍微差一点。
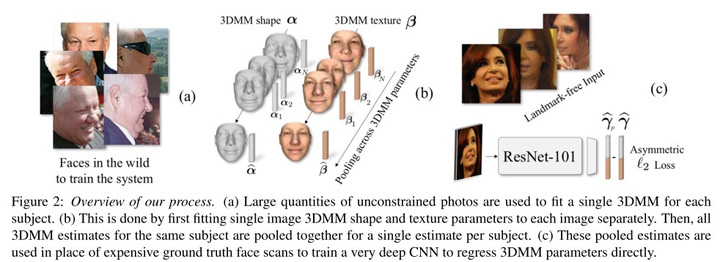
![]()
图8-1 3D重建训练示意图
8.3.1 The asymmetric Euclidean loss
我们在实验中发现,使用Euclidean loss会导致输出3d人脸缺少细节,如图8-2所示。因此,我们引入了asymmetric Euclidean loss。
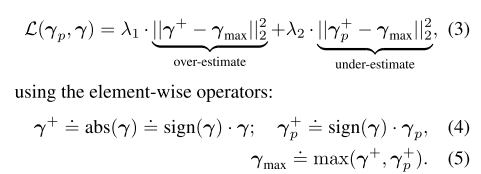
![]()
其中,![]() 为目标pooled 3DMM值,
为目标pooled 3DMM值,![]() 为输入,
为输入,![]() 为平衡over和under estimation errors的值。在实际操作中,我们设定
为平衡over和under estimation errors的值。在实际操作中,我们设定![]() ,来鼓励模型学习更多的细节。
,来鼓励模型学习更多的细节。
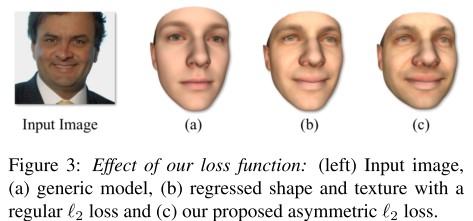
![]()
图8-2 不同loss函数对结果的影响
8.4 实验结果
8.4.1 3D重建结果
MICC数据集包含53个个体的人脸视频和个体的3D模型作为gound truth。这些视频可以用于单张图片和多张图片的3D重建。实验结果如表8-1所示,该重建方法比当前的方法都要好。
表8-1 3D重建实验结果

![]()
8.4.2 人脸识别
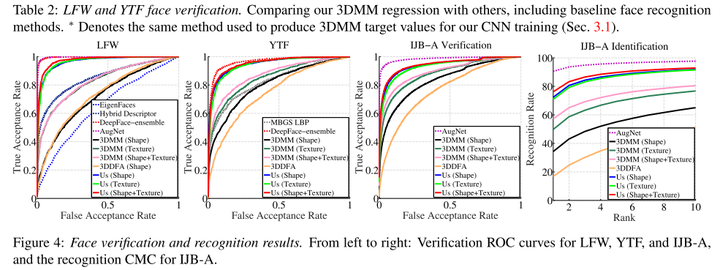
我们研究了同一人不同的照片重建的3DMM是否比不同人的照片重建的3DMM差异更小。我们在LFW,YTF和IJB-A数据集上测试了我们的方法。结果如表8-2和图8-3所示。
表8-2 LFW和YTF测试结果
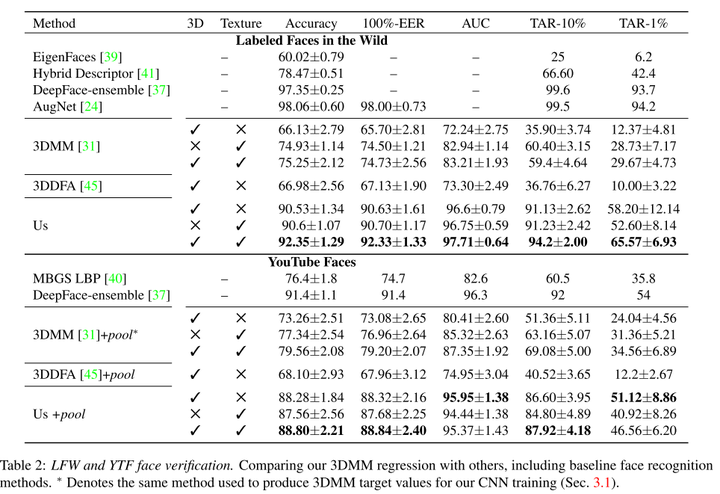
![]()
![]()
图8-3 LFW,YTF和IJB-A测试结果
8.4.3 定性结果
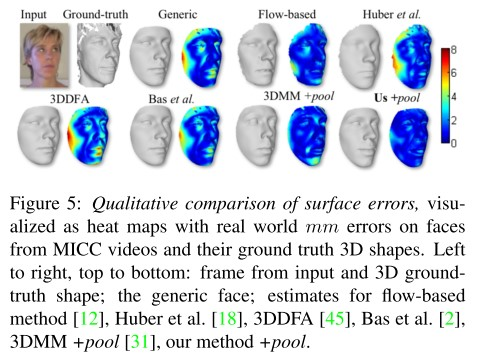
图8-4展示了训练模型生成的3DMM结果。
![]()
图8-4 3DMM生成模型结果
总结
本文综述了8种基于深度学习的人脸识别方法,包括:1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 )。上述方法可以分为两大类:
第一类:face++,DeepFace,DeepID,FaceNet和baidu。他们方法的核心是搜集大数据,通过更多更全的数据集让模型学会去识别人脸的多样性。这类方法适合百度/腾讯/谷歌等大企业,未来可以搜集更多更全的训练数据集。数据集包扩同一个体不同年龄段的照片,不同人种的照片,不同类型(美丑等)。通过更全面的数据,提高模型对现场应用中人脸差异的适应能力。
第二类:FR+FCN,pose+shape+expression augmentation和CNN-3DMM estimation。这类方法采用的是合成的思路,通过3D模型等合成不同类型的人脸,增加数据集。这类方法操作成本更低,更适合推广。其中,特别是CNN-3DMM estimation,作者做了非常出色的工作,同时提供了源码,可以进一步参考和深度研究。