鼻咽癌/鼻咽淋巴瘤数据处理报告
一、 数据处理与数据划分
- 数据介绍与处理:
数据集为三种成像状态下的特征(以其中一种成像状态为例),共计107条数据,每一条数据有186列,前185列为属性列,最后一列为类标签。
数据集中的几条数据,存在部分属性列值缺失,做了补零处理,但是有属性列的原始值也为零,所以补零操作会影响预测准确度。
2.数据划分:
数据集共有107条数据,将数据分成五份,即训练集 : 测试集 = 4 : 1,所以训练集有86条数据,测试集有21条数据(训练集为train.csv,测试集为test.csv)。
二、 选取的工具、模型
使用的工具为TensorFlow(1.12.0)。
使用的模型为深度神经网络即DNN分类器,对数据进行分类并预测。
三、 训练模型的关键代码
- 数据的读入
数据是以 csv 的格式加载进来,前185列属性列数据全部转成float类型,最后一列类标签转换成int类型。
以下代码为从train.csv中读入训练集数据,测试数据的读入类似。


2.使用训练集数据生成模型
将1中读入训练集数据的属性列(185列)放入feature_columns数组中,分类器定义为DNN分类器,传入的参数分别为属性类数组,隐藏层,类标签。其中神经网络的隐藏层设为了3层,每一层的神经元个数分别为10、20、10;类标签的取值个数为2,原始数据中为1、2,已经手动改为了0、1。
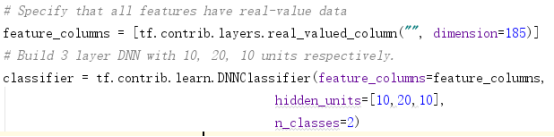
使用训练数据集来训练生成模型,并设置训练次数,实验中使用了1000次与5000次。

3.使用训练好的模型进行测试集的预测
将测试集数据读入,得到使用该模型时,测试集的预测准确度Accuracy、损失函数Loss。

四、 测试结果统计
- 100次测试的平均结果为:Accuracy: 0.544286
其中的五次测试结果:
| Train_steps |
1000 |
1000 |
1000 |
1000 |
1000 |
| Test_steps |
1 |
1 |
1 |
1 |
1 |
| hidden_units |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
| Accuracy |
0.476190 |
0.571429 |
0.523810 |
0.619048 |
0.619048 |
| Loss |
0.894459 |
3117.075928 |
0.767341 |
0.655536 |
0.639962 |
100次测试的平均结果为:Accuracy: 0.553333
其中的五次测试结果:
| Train_steps |
1000 |
1000 |
1000 |
1000 |
1000 |
| Test_steps |
10 |
10 |
10 |
10 |
10 |
| hidden_units |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
| Accuracy |
0.571429 |
0.523810 |
0.523810 |
0.619048 |
0.523810 |
| Loss |
42722.402344 |
0.726201 |
0.726212 |
253.275070 |
0.725999 |
100次测试的平均结果为:Accuracy: 0.566667
其中的五次测试结果:
| Train_steps |
5000 |
5000 |
5000 |
5000 |
5000 |
| Test_steps |
1 |
1 |
1 |
1 |
1 |
| hidden_units |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
| Accuracy |
0.619048 |
0.523810 |
0.523810 |
0.619048 |
0.571429 |
| Loss |
0.651776 |
0.739012 |
0.726212 |
0.650773 |
0.652422 |
100次测试的平均结果为:Accuracy: 0.566191
其中的五次测试结果:
| Train_steps |
5000 |
5000 |
5000 |
5000 |
5000 |
| Test_steps |
10 |
10 |
10 |
10 |
10 |
| hidden_units |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
[10,20,10] |
| Accuracy |
0.523810 |
0.523810 |
0.523810 |
0.619048 |
0.523810 |
| Loss |
0.726211 |
0.726211 |
0.726212 |
0.700954 |
0.726213 |
五、 测试结果分析
- 从四次测试结果可知:
| 训练次数(次) |
1000 |
1000 |
5000 |
5000 |
| 每一次的测试次数(次) |
1 |
10 |
1 |
10 |
| 100次测试的准确度平均值 |
0.544286 |
0.553333 |
0.566667 |
0.566191 |
训练的次数为1000次(或5000次),测试的次数分别为1次、10次时,可知预测准确度提高了不足1%,所以训练生成的模型,修改每一次测试次数对准确度的影响很小。
当每一次的测试次数固定(1次或10次),训练的次数为1000次、5000次时,100次测试的准确度平均值增长大于1%,可知加大训练次数后生成的模型,分类能力增强。
2.四次测试结果中,100次测试的准确度平均值区间为[0.54,0.57],可知训练生成的分类器模型分类能力很差,原因可能为:
1) 数据集的数据过小,数据划分后训练集与数据集的数据差异较大,使得由训练集训练生成的分类模型与测试集贴合度较差。
2) 数据集中每一条数据的属性列有185列,可并不是所有属性列均影响标签列的最终结果,所以需要进行降维处理,选择更合适的属性列进行模型训练。
3) 该DNN分类器的隐藏层设置为了3层,每一层的神经元分别为10,20,10,设置可能并不合理,如隐藏层的层数过低,或每一层的神经元个数太少等,均影响着最终的测试结果。
4) 存在部分属性列值缺失,做了补零处理,但是有属性列的原始值也为零,所以补零操作影响了预测准确度。