补充上篇博客提到的json文件数据转换成csv文件。作为数据分析最常用文件类型json与csv,出于一定情况下,我们需要将json中字典类型的数据,转换为csv存储,这又用到python强大的pandas模块了。我们一步一步来。
json的文件结构
按照我的理解,json像是一个字典文件,整一个文件的数据存储按照字典的格式进行,即key:values,大的数据一般是多层嵌套字典。故,对json的数据提取,就要分别对json的key,values数据进行提取。如下的一个json文件(test_json.json):

json文件的内容如下:

简单来看,就是一个字典数据
使用pandas进行转换提取
按照思路,我们要将json文件的keys数据以及values值提取,如下
import pandas as pd
import json
filename = './files/test_json.json'
with open(filename,'r') as f_ojb:
json_data = json.load(f_ojb,)
print(json_data)
查看读取的结果:
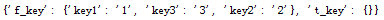
将键f_key内的字典值分别提取出来,存放在json_keys,json_values里:
json_fkey = json_data['f_key']
json_keys = [str(json_) for json_ in json_fkey.keys()]
json_values = [int(j_values) for j_values in json_fkey.values()]
接下来我们就要使用pandas对数据存为csv文件,首先,pandas处理的数据类型是dataframe,而dataframe是由Series数据组合成的,即我们需要将key值与values值先转换成Series类型,如下:
keys = pd.Series(json_keys,name='key') #这里使用pandas的Series方法对数据进行封装,并命名列名
values = pd.Series(json_values,name='values')
接下来对两条series数据合并成dataframe:
df_data = pd.concat([keys,values],axis=1) #concat是将多条series数据合并成dataframe,axis参数决定合并的轴向,1代表从第二维度合并,0代表第一维度。
最后一步,将dataframe数值写到csv文件中:
df_data.to_csv('./files/test_json_to_csv.csv',index=None) #index参数代表不将序列号填入文件,dataframe默认是会生成序列号的
查看结果:

生成了csv文件,查看文件内容:
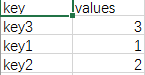
这样就完成了json文件到csv文件的转换