10. tf.to_int64()
将张量转换为int64类型。
tf.to_int64(
x, #tensor或sparseTensor
name = 'ToInt64' #名字,可选项,可有可无
)返回:一个tensor或sparseTensor,与x(int 64类型)具有相同形状。
11. tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
- 传入的logits是网络的输出,shape=[batch_size,num_classes]
- 传入的labels是一维向量,长度为batch_size,取值区间[0,num_classes),每个值代表batch中对应样本的类别
这个函数可以分为两步:
第一步:计算softmax:

softmax公式:

第二步:计算交叉熵损失(cross-entropy)
算完网络输出层的softmax结果之后,使用cross-entropy作为损失函数。tf.nn.sparse_softmax_cross_entropy_with_logits()输入的labels是一维向量,首先将其转化为one-hot格式编码,eg:如果该向量的分量值为2,表示属于第2类,对应的one-hot格式为[0,0,1,0..0],然后用这个函数计算loss:
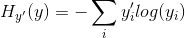
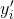
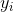
可以看出,分类越准确,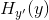
12. tf.summary.scalar()
原型:
def scalar(name, tensor, collections=None, family=None)函数说明:
输出一个含有标量值的Summary protocol buffer,这是一种能够被tensorboard模块解析的【结构化数据格式】用来显示标量信息用来可视化标量信息summary protocol buffer又是一种能够被tensorboard解析并进行可视化的结构化数据格式。我将tf.summary.scalar()函数的功能理解为:将【计算图】中的【标量数据】写入TensorFlow中的【日志文件】,以便为将来tensorboard的可视化做准备
参数说明:
name:一个节点的名字,如下图红色矩形框所示
tensor:要可视化的数据、张量
主要用途:
一般在画loss曲线和accuary曲线时会用到这个函数。
使用方法:
def variable_summaries(var,name):
with tf.name_scope('summaries'):
#【1】通过tf.summary.histogram()
tf.summary.histogram(name,var)
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/'+name,mean)
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('stddev/'+name,stddev)- 函数说明:
生成【变量】的监控信息,并将生成的监控信息写入【日志文件】 参数说明:var:需要【监控】和【记录】运行状态的【张量】name:给出了可视化结果中显示的图表名称

来源:https://www.2cto.com/kf/201805/746214.html
13. tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name=’GradientDescent’)
用途:创建一个梯度下降优化器对象【构造这个函数其实只需要学习率】
参数:
- learning_rate: 要使用的学习率
- use_locking:
- name: 可选,名字
14.optimizer.minimize(loss,global_step=None,var_list=None,gate_gradients=GATE_OP,aggregation_method=None,colocate_gradients_with_ops=False,name=None,grad_loss=None)
是上面tf.train.GradientDescentOptimizer()的一个“子函数”。
作用:通过更新var_list来减小loss,可参考:https://blog.csdn.net/xierhacker/article/details/53174558
15. tf.nn.in_top_k(predictions, targets, k, name=None)
功能:返回一个布尔向量,说明目标值是否存在于预测值之中。
输出数据是一个 targets 长度的布尔向量,如果目标值存在于预测值之中,那么 out[i] = true。targets 是predictions中的索引位,并不是 predictions 中具体的值。
import tensorflow as tf
import numpy as np
input = tf.constant(np.random.rand(3,4), tf.float32)
k = 2 #targets对应的索引是否在最大的前k(2)个数据中
output = tf.nn.in_top_k(input, [3,3,3], k)
with tf.Session() as sess:
print(sess.run(input))
print(sess.run(output))
输出:
>>>[[ 0.43401602 0.29302254 0.40603295 0.21894781]
[ 0.77089119 0.95353228 0.04788217 0.37489092]
[ 0.83710146 0.2505011 0.28791779 0.97788286]]
>>>[False False True]16. tf.cast()
cast(
x,
dtype,
name=None
)功能:将x中的数据格式转化成dtype类型,比如原来是bool型,将其转化成float类型后,就变成01序列了。
17. tf.reduce_sum()
reduce_sum(
input_tensor,
axis = None,
keep_dims = False,
name = None,
reduction_indices = None
)功能:计算一个张量的各维度上元素的总和
18. X.next_batch()
功能:分批次读取数据
19. xrange()
功能:用法与range完全相同,所不同的是生成的不是一个数组,而是一个生成器。
用法:
xrange(stop)
xrange(start, stop[, step])- start: 计数从 start 开始。默认是从 0 开始。例如 xrange(5) 等价于 xrange(0, 5)
- stop: 计数到 stop 结束,但不包括 stop。例如:xrange(0, 5) 是 [0, 1, 2, 3, 4] 没有 5
- step:步长,默认为1。例如:xrange(0, 5) 等价于 xrange(0, 5, 1)
样例:
>>> xrange(8)
xrange(8)
>>> list(xrange(8))
[0, 1, 2, 3, 4, 5, 6, 7]
>>> range(8) # range 使用
[0, 1, 2, 3, 4, 5, 6, 7]
>>> xrange(3, 5)
xrange(3, 5)
>>> list(xrange(3,5))
[3, 4]
>>> range(3,5) # 使用 range
[3, 4]
>>> xrange(0,6,2)
xrange(0, 6, 2) # 步长为 2
>>> list(xrange(0,6,2))
[0, 2, 4]后接:https://blog.csdn.net/Dorothy_Xue/article/details/84979049