查询数据
完整的查询指令
select select选项 字段列表 from 表名 where 条件 group by 分组 having条件 order by 排序 limit 限制;
-
select 选项
系统该如何对待查询得到的结果
all:默认的,表示保存所有的记录distinct:去重,去除重复(所有字段都相同)的记录,只保留一条 -
字段列表
有的时候需要从多张表中获取数据,在获取数据的时候,可能存在不同表中有同名的字段,需要将同名字段命名为不同名的:别名
alias基本语法:
字段名 [as] 别名
from数据源
from是为前面的查询提供数据:数据源只要是一个符合二维表结构的数据即可。
单表数据
基本语法:
from 表名
多表数据
从多张表获取数据
基本语法:
from 表1,表2...
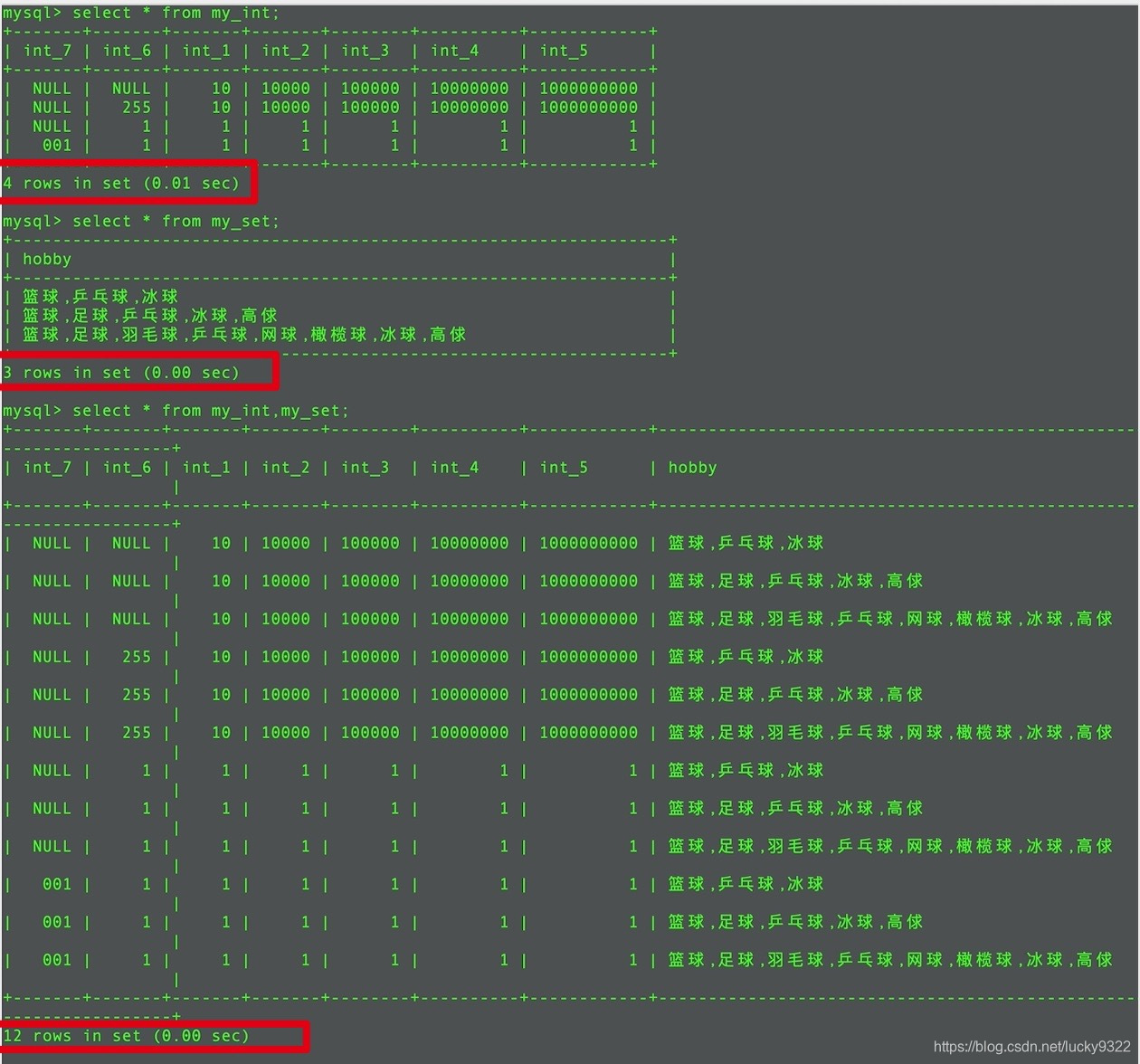
结果:两张表的记录相乘,字段拼接
本质操作:从第一张表取出一条记录,去拼凑第二张表的所有记录,并保留所有结果。得到的结果在数学上称为:笛卡尔积,这个结果除了给数据库造成压力,没有其他意义,所以在实际使用中应该尽量避免出现笛卡尔积。
动态数据
from后面跟的不是实体表,而是一个从表中查询出来得到的二维结果表。
基本语法:
from (select 字段列表 from 表名) [as] 别名;

where子句
where用来从数据表获取数据的时候,进行条件筛选。
数据获取原理:针对表去对应的磁盘处获取所有的记录(一条条),where的作用就是在拿到一条结果就开始进行判断,判断是否符合条件:如果符合条件就保留下来
where本身不能判断,而是通过运算符进行结果比较来判断数据。
group by子句
group by表示分组的含义,根据指定的字段,将数据进行分组:分组的目标是为了统计。
分组统计
基本语法:
group by 字段名
alter table my_student add class_id int;
update my_student set class_id=1 where stu_id in ('stu0001','stu0002');
update my_student set class_id=2 where stu_id in('stu0003','stu0004');
//在MySQL 5.7.5后only_full_group_by成为sql_mode的默认选项之一,这可能导致一些sql语句失效
select * from my_student group by class_id;
MySQL 5.7.5后only_full_group_by成为sql_mode的默认选项之一,这可能导致一些sql语句失效
group by是为了分组后进行数据统计的,如果只是想看数据显示,那么group by没有任何意义:group by将数据按照指定的字段分组之后,只会保留每组的第一条记录(5.7.5支版本之前可以这么操作)
一些统计函数(聚合函数):
count():统计每组中的数量,如果统计目标是字段,那么统计不为空的字段,如果为*代表统计记录avg():求平均值sum():求和max():求最大值min():求最小值
测试案例
数据准备
alter table my_student add stu_age tinyint unsigned;
alter table my_student add stu_height tinyint unsigned;
update my_student set stu_age=18,stu_height=185 where stu_id='stu0001';
update my_student set stu_age=28,stu_height=165 where stu_id='stu0002';
update my_student set stu_age=22,stu_height=187 where stu_id='stu0003';
update my_student set stu_age=25,stu_height=189 where stu_id='stu0004';
测试场景
按照班级,统计每班人数、最大年龄、最低身高、评论年龄
select count(*),max(stu_age),min(stu_height),avg(stu_age) from my_student group by stu_id;

group_concat():是为了将分组中指定的字段进行合并(字符串拼接)
select group_concat(stu_name), count(*),max(stu_age),min(stu_height),avg(stu_age) from my_student group by class_id;

多分组
将数据按照某个字段进行分组之后,对已经分组的数据进行再次分组
基本语法:group by 字段1,字段2//先按照字段1进行分组,然后在按照字段2进行分组
分组排序
MySQL中,分组默认又排序的功能:按照分组字段进行排序,默认是生序
基本语法:
group by 字段1 [asc|desc],字段2 [asc|desc]
回溯统计
当进行多分组之后,往上统计的过程中,需要进行层层上报,将这种层层上报统计的过程称之为回溯统计:每一次分组向上统计的过程都会产生一次新的统计数据,而且当前数据对应的分组字段为NULL
基本语法:group by 字段 [asc|desc] with rollup
having 子句
having本质和where是一样的,是用来进行数据条件筛选,但是也有和where的不同点
-
having是在group by子句之后:可以针对分组数据进行筛选统计,但是where不行查询班级人数大于等于4个以上的班级
insert into my_student values('stu0007','小江',1,17,172,2); select class_id , count(*) as number from my_student group by class_id having number >=4;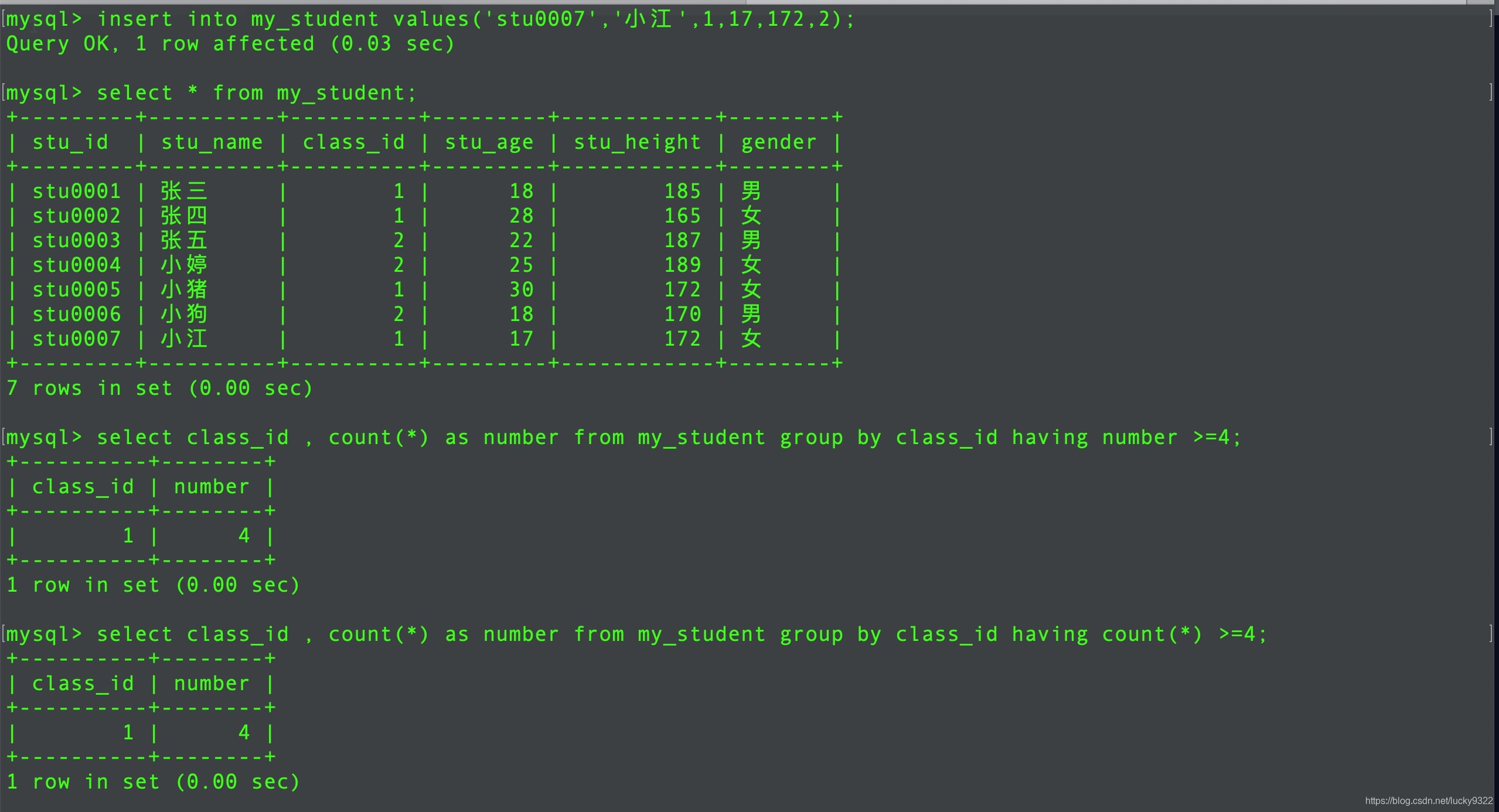
having在group by分组之后,可以使用聚合函数或者别名强调
having是用在group by之后,group by是用在where之后:where的时候表示数据从磁盘拿到内存,where之后的所有操作都是内存操作。
order by子句
order by排序:根据校对规则对数据进行排序
基本语法:
order by 字段 [asc|desc];//默认是asc可以不用写
//按照身高排序
select * from my_student order by stu_height;

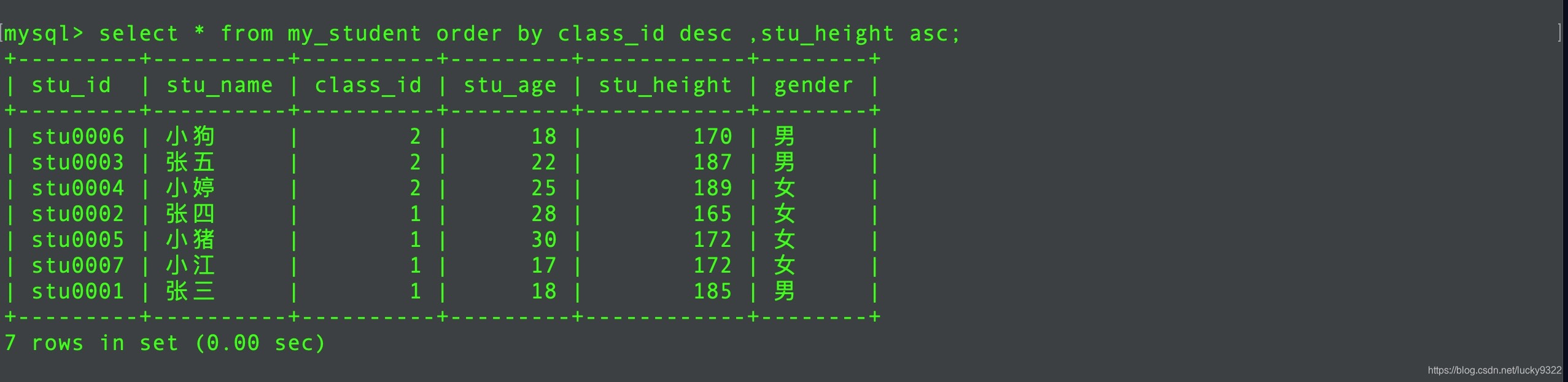
order by也可以像group by一样进行多字段排序:规则就是先按照第一个字段排序,然后在按照后面的字段排序
基本语法:
order by 字段1 [asc|desc] , 字段2 [asc|desc]
// 按照班级以及身高排序
select * from my_student order by class_id desc ,stu_height asc;
limit子句
limit限制子句:主要是用来限制记录数量获取
记录数限制
纯粹的限制获取的数量:从第一条到指定的数量
基本语法:
limit 数量
limit通常在查询的时候如果限定为一条记录的时候,使用的比较多:有时候获取多条记录并不能解决业务问题,但是会增加服务器压力。
分页
利用limit来限制获取指定区间的数据。
基本语法:
limit offset , length//offset 偏移量 length 具体获取几条数据
MySQL中的记录从0开始
limit 0,2获取前两条数据