数据库学习02–查询
一、基础知识
1.win中启动Mysql命令(本机我命名的mysql57)
C:\Users\Administrator>net start mysql57
MySQL57 服务正在启动 ...
MySQL57 服务已经启动成功。2.只有主键才能给别人当外键(外来的主键)
添加检查约束:
mysql不支持检查约束(不生效),但是oricle会生效
now()是显示当前系统时间,mysql特有的,其他数据库没有
二、查询基本操作DQL
1.查询所有行,所有列====select * from
| 类别 | 详细解释 |
|---|---|
| 基本语法 | select * from 表; |
| 示例 | select * from star; |
| 示例说明 | 查询star表中所有字段中的所有结果 |
2.指定字段查询
| 类别 | 详细解释 |
|---|---|
| 基本语法 | select 字段 from 表; |
| 示例 | select id, name, money from star; |
| 示例说明 | 查询star表中id, username, money字段 |
3.去重(指定字段组合不重复记录)
| 类别 | 详细解释 |
|---|---|
| 基本语法 | select distinct 字段 from 表; |
| 示例 | select distinct age, sex from star; |
| 示例说明 | 查询star表中age和sex组合的不重复结果 |
4.投影和别名select….from…. select ….as….from
注意:别名用as,但是as也可以省略
-- 投影
select stuid,stuname,stusex from tb_student;
-- 别名
select stuid as 学号,stuname as 姓名,stusex as 性别 from tb_student;5.处理查询结果(对数据进行运算处理)
注意 结尾要有end
select stuid as 学号,stuname as 姓名, case stusex
when 1 then '男' else '女' end as 性别 from tb_student;
-- 方法二:用if语句,Mysql特有的,不具有通用性
select stuid as 学号, stuname as 姓名,if(stusex,'男','女') as 性别
from tb_student;
6.合并函数(特有的)
select concat(tname,ttitle) as 全称 from tb_teacher;7.清空表
truncate table 表名 清空表,id会从1开始
delete from table 清空表,id从上次记录的值开始
三、条件查询(筛选) where
筛选可组合多个条件,条件之间可以是and也可以是or的关系
运算符号: <>不等号
1.where
| 类别 | 详细解释 |
|---|---|
| 基本语法 | select 字段 from 表 where 条件; |
| 示例 | select * from star where age=43; |
| 示例说明 | 查询star表中age为43的所有结果 |
选出tb_student中stuid(学号)为1001的所有记录
select * from tb_student where stuid = 1001;
选出tb_student表中stuid(学号)为1001的学生的姓名和籍贯信息
select stuname as 姓名,stuaddr as 籍贯 from tb_student
where stuid=1001;2.where后面可接的条件
| 符号 | 说明 |
|---|---|
| > | 大于 |
| < | 小于 |
= |
大于等于 |
| <= | 小于等于 |
| != 或 <> | 不等于 |
| = | 等于 |
| or | 或者 |
| and | 并且 |
| between and | 在某个闭区间 |
| In / not in | 在/不在指定的集合中 |
| like | 模糊查询 |
示例(1)where…..and和between…..and…..
筛选学号大于1001小于2000的学生的姓名和籍贯
select stuname as 姓名,stuaddr as 籍贯 from tb_student
where stuid > 1001 and stuid <2000;
从tb_student表中筛选出学生学号在1002到19920之间的学生的姓名和籍贯
select stuname as 姓名,stuaddr as 籍贯 from tb_student
where stuid between 1002 and 1990;(2).where…or…
select stuname as 姓名,stuaddr as 籍贯 from tb_student
where stuid = 1001 or stuid >=2000; 学号等于1001或者学号大于等于2000得学生| 类型 | 说明 |
|---|---|
| 示例 | select * from star where id<10 and province=’湖北’; |
| 说明 | 查询star表中所有id小于10并且province为湖北 |
| 示例 | select * from star where id between 3 and 10; |
| 说明 | 查询star表中所有id在[3, 10]的闭区间的记录 |
| 示例 | select * from star where id in(3,4,8,10); |
| 说明 | 查询star表中所有id在指定集合中的记录 |
四、模糊查询==like
模糊查询中,筛选条件不能用等号,这里用 like ,同时通配符用%
1.查询开头不限长度
【例1】 查询姓龙或者姓林的名字(不限总字数)==%
select stuid,stuname from tb_student where stuname like
'林%'or stuname like '龙%'2.查询开头,限制数量
【例2】查询姓林的名字共两个字==下划线_
select stuid,stuname from tb_student where stuname like'林_'【例3】查询姓林的名字共三个字==双下划线_ _
select stuid,stuname from tb_student where stuname like'林_ _'【例4】查询三个字,中间字符是林
select stuid,stuname from tb_student where stuname like'_林_'3.查询含有某个字(不限位置)==%字符%
百分号之间不是只差中间,而是任意位置
【例】查询名字中带林的,不分位置
select stuid,stuname from tb_student where stuname like '%林%'五、排序操作==order by
1.order by默认是升序(从小到大),降序在尾部添加desc
| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 order by 字段 排序关键词 |
| 示例 | select id, name, money from star order by money desc; |
| 示例说明 | 查询star表中的id, name, money字段,按照余额进行降序排序 |
| 关键词 | 说明 |
|---|---|
| asc | 升序排列,从小到大(默认) |
| desc | 降序排列,从大到小 |
2.多字段排序
| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 order by 字段1 desc|asc, … ,字段n desc|asc; |
| 示例 | select id, name, money from star order by money desc, age asc; |
| 示例说明 | 查询star表中的id, name, money字段,按照余额进行降序排序,若余额全都一样,则再使用age进行升序排序 |
【例2】按照性别排序降序—->如果性别相同再按照生日排序降序
select * from tb_student order by stusex desc, stubirth desc;3.先筛选再排序(当多个操作结合时采用这个顺序)
【例】筛选90后
从tb_student表中选择所有记录,要求在1990.1.1-1991.12.31之间出生,按照性别升序,按照出生年月降序
select * from tb_student where stubirth between '1990-1-1' and
'1999-12-31' order by stusex asc,stubirth desc;六、聚合函数(统计函数)
| 类型 | 说明 |
|---|---|
| sum | 求和 |
| count | 统计总数 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
选出表中学号的记录总数
select count(stuid) from tb_student;
也可以将新求的变量别名,命名为‘和’
select count(stuid) as 和 from tb_student;
统计性别是女的学号记录数量
select count(stuid) from tb_student where stusex=0;
-- 统计1111这门课程的平均成绩===avg()函数
select avg(score) from tb_score where cid=1111;
统计成绩和
select sum(score) from tb_score where cid=1111;
-- 统计1111这门课程的平最高成绩
select max(score) from tb_score where cid=1111;
-- 统计1111这门课程的平最低成绩
select min(score) from tb_score where cid=1111;
选出学生表中出生日期最大值(数学值)
select max(stubirth) from tb_student;
显示结果:1995-08-12七、分组查询==group by
分组只能写分组字段和统计字段,写其它字段报错
1.分组
| 类型 | 说明 |
|---|---|
| 基本语法 | select * from 表 group by 字段 |
| 示例 | select * from star group by province; |
| 示例说明 | 按照province进行分组 |
几个实例
select case stusex when 0 then '女' else '男' end as 性别, count(stusex) as 人数 from tb_student group by stusex;
select case stusex when 0 then '女' else '男' end as 性别, min(stubirth) as 出生日期 from tb_student group by stusex;
-- 统计每门课的平均分
select cid , avg(score) from tb_score group by cid;【例】按学号分组,统计每个学生的平均分,按照平均分降序
select sid, avg(score) as avg from tb_score group by sid order by avg desc ;注意:为了明确数据库位置,可以写成srs.tb_score代表执行src下的tb_score,位置更具体,不容易报datebase不存在错误或者
方法二:上面写上 use srs 代表执行这个数据库
2.结果集过滤===having
| 类型 | 说明 |
|---|---|
| 基本语法 | select * from 表 group by 字段 having 条件 |
| 示例 | select count(province) as result , province from star group by province having result>2; |
| 示例说明 | 对province分组并统计总数,将分组结果中大于2的分组显示出来 |
对分组后的结果集进行过滤,注意不要用where
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。WHERE是跟在表后面的,HAVING 子句可以让我们筛选分组后的各组数据。
select sid, avg(score) as avg from tb_score where sid between 1000 and 1999 group by sid
having avg>=80 order by avg desc ;八、限制和分页查询limit …offset
1.限制查询的结果集
1.limit代表看几条信息
对于查询或者排序后的结果集,如果希望只显示一部分,使用limit关键字对结果集进行数量限制。
【例】 查询年龄最大的3名学生的信息
select * from tb_student order by stubirth limit 3 ; 看3条信息| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 limit 数量; |
| 示例 | select id, name, money from star limit 5; |
| 示例说明 | 显示前5个记录 |
2.限制排序后的结果集
| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 order by 字段 排序规则 limit 数量 |
| 示例 | select id, name, money from star order by money desc limit 5; |
| 示例说明 | 按照money来排序,显示前5个最有钱的记录 |
3.结果集区间选择
offset代表跳过数据读取
-- 跳过前3个再看3个
select * from tb_student order by stubirth limit 3 offset 3;
-- 跳过前6个再看3个
select * from tb_student order by stubirth limit 3 offset 6;【简写方式】前面:偏移量,后面代表拿几条数据(和刚才上方两个运行结果一直),
格式:limit 偏移量,数量
select * from tb_student order by stubirth limit 3 ,3 #
select * from tb_student order by stubirth limit 6 ,3;| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 limit 偏移量,数量 |
| 示例 | select id, name, money from star limit 0,3; |
| 示例说明 | 取从第一条开始的三条记录 |
4.用limit解决分页
第1页为 limit 0,10
第2页为 limit 10,10
第3页为 limit 20,10
依此类推... ...九、子查询(嵌套查询) =、in
子查询就是把一个查询的结果作为另外一个查询的条件
| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 where 字段 in(条件) |
| 示例1 | select * from user where gid in (1,3,4); |
| 示例1说明 | 按照id 查询指定用户 |
| 示例2 | select * from user where gid in (select gid from goods); |
| 示例2说明 | 将购买过商品的用户信息显示出来(in也可以用=) |
【例】 查询年龄最大的学生的姓名(即生日日期最小的)
select stuname from td_student where stubirth=(select min(stubirth) from tb_student);【例】学了python学习这门课,考了做高分的学生姓名
select stuname from tb_student where stuid = (select sid from tb_score where score=(select max(score) from tb_score where cid=(select courseid from tb_course where cname='Python程序设计')) and cid=(select courseid from tb_course where cname='Python程序设计'));
这里有几个问题
【bug1】这里不区分大小写,将Python改为小写的python依然可以执行,这是因为编辑数据为ci(大小写不敏感)
– 将其改为utf8 bin 设置方式:右击编辑数据库–》排序规则:utf8_bin(区分大小写)
【补充】创建数据库的时候设置create database SRS default charset utf8后面加上collate utf_bin
– utf8nb4四字节的utf8,例如苹果系统下图片字符;正常utf-8是8bit一个字节,英文1字节,汉字为3字节
【bug2】若有两个学生相同分数,写等号查不出来,报错子查询返回值多余一行’,这里改为in
select stuname from tb_student where stuid in (select sid from tb_score where score=(select max(score) from tb_score where cid=(select courseid from tb_course where cname='Python程序设计')) and cid=(select courseid from tb_course where cname='Python程序设计'));【例】查询选了3门以及以上的课程的学生姓名
思路:用学号分组,统计一下每组有几个学号,由内往外写
select stuname from tb_student where stuid in (select sid from tb_score group by sid having count(sid)>=3);
十、查询顺序
| 类型 | 说明 |
|---|---|
| select | 选择的列 |
| from | 表 |
| where | 查询的条件 |
| group by | 分组属性 having 分组过滤的条件 |
| order by | 排序属性 |
| limit | 起始记录位置,取记录的条数 |
十一、多表联合查询
很多时候在实际的业务中我们不只是查询一张表。如:在电子商务系统中,查询哪些商品没有用户购买。银行中可以查询违规记录,同时查询出用户的基本信息;查询中奖信息,同时查询中奖人员的基本信息。而上述业务中需要多表联合在一起查询,其本质就是表连接。
1.表连接的分类
表连接分为内连接和外连接
(1)内连接
选出两个表中存在连接关系的字段符合连接关系的那些记录。内连接分为显示内连接和隐式内连接
(2)外连接
会选出其他不匹配的记录,外连接分为外左连接和外右连接,全外连接(mysql不支持全外连接)2.内连接
(1)隐式内连接
| 类型 | 说明 |
|---|---|
| 基本语法 | select 表1.字段 [as 别名], 表n.字段 from 表1 [别名], 表n where 条件; |
| 示例 | select username, name from user, goods where user.gid=goods.gid; |
| 示例说明 | 查询用户表中哪些用户购买过商品,并将商品信息显示出来 |
说明:以上方式称为隐式内连接,因为没有出现join关键字
给字段别名用as,也可以不用别名(2)显示内连接
| 类型 | 说明 |
|---|---|
| 基本语法 | select 表1.字段 [as 别名],表n.字段 from 表1 inner join 表2 on 条件; |
| 示例 | select username, name from user inner join goods on user.gid=goods.gid; |
| 示例说明 | 查询用户表中哪些用户购买过商品,并将商品信息显示出来 |
说明:以上方式的inner关键字换成cross同样可以,其实也可以省略,直接用join3.外连接
左:写在前面的表 右:写在后面的表
(1)左连接
| 类型 | 说明 |
|---|---|
| 基本语法 | select 表1.字段 [as 别名], 表n.字段 from 表1 left join 表n on 条件; |
| 示例 | select * from user left join goods on user.gid = goods.gid; |
| 示例说明 | 以左边为主,查询哪些用户购买过商品,并将商品信息显示出来 |
左连接:包含所有的左边表中的记录甚至是右边表中没有和它匹配的记录
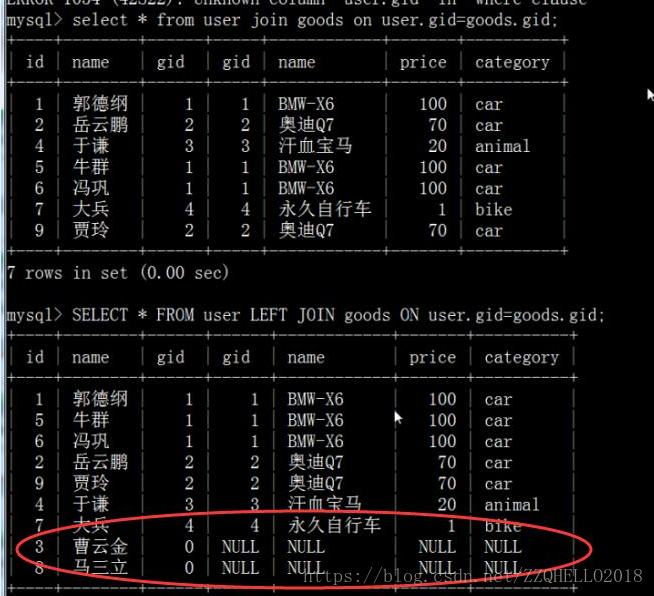
(2)右连接
| 类型 | 说明 |
|---|---|
| 基本语法 | select 表1.字段 [as 别名], 表n.字段 from 表1 right join 表n on 条件; |
| 示例 | select * from user right join goods on user.gid = goods.gid; |
| 示例说明 | 以右边为主,查询哪些商品有用户购买,并将用户信息显示出来 |
右连接:包含所有的右边表中的记录甚至是左边表中没有和它匹配的记录
思考:
1、请选出哪些商品没有被购买过???
2、找出哪那类商品是销量冠军???
3、找出销量冠军产品及价格???【例】查询课程名称、学分、授课老师的名字和职称
-- 方式一:自然连接
-- 不加tid=teacher的条件会形成笛卡尔积1a,2a,3a,1b,2b,3b。。。
select cname ,ccredit, tname,ttitle from tb_course,tb_teacher
where tid=teacherid;方式二===inner join内连接
- 方式二:内连接==inner join
select cname ,ccredit, tname,ttitle from tb_course
inner join tb_teacher on tid=teacherid;
【变式提升】- 查询学生姓名和所在学院名称
【错误写法】两个表中都有collid,会冲突报ambiguous错误—>给表别名(省略as一般)
-- select stuname,collname from tb_student inner join tb_college on collid =collid
select stuname,collname from tb_student t1 inner join
tb_college t2 on t1.collid =t2.collid[变式提升2]查询学生姓名、课程名称以及考试成绩
-- 方式一
select stuname, cname, score from tb_student, tb_course, tb_score where stuid=sid and courseid=cid and score is not null;
-- 方式二:(优化:最后where后面的语句null去除空值)
select stuname ,cname,score from tb_student inner join
tb_score on stuid = sid inner join tb_course on courseid =cid
where score is not null;注意- 和 null作比较时不能使用等号=和不等号<>,要使用is null或者is not null来进行判断
4.记录联合
| 类型 | 说明 |
|---|---|
| 基本语法 | select 语句1 union[all] select 语句2 |
| 示例 | 左连接 union 右连接; |
| 示例说明 | 将商品表中的信息和用户表中的信息组合在一起 |
使用 union 和 union all 关键字,将两个表的数据按照一定的查询条件查询出来后,
将结果合并到一起显示。两者主要的区别是把结果直接合并在一起,
而 union 是将 union all 后的结果进行一次distinct去重,去除重复记录后的结果。
十二、子查询(嵌套查询) =、in
子查询就是把一个查询的结果作为另外一个查询的条件,也是多表联合的一种
| 类型 | 说明 |
|---|---|
| 基本语法 | select 字段 from 表 where 字段 in(条件) |
| 示例1 | select * from user where gid in (1,3,4); |
| 示例1说明 | 按照id 查询指定用户 |
| 示例2 | select * from user where gid in (select gid from goods); |
| 示例2说明 | 将购买过商品的用户信息显示出来(in也可以用=) |
【例】 查询年龄最大的学生的姓名(即生日日期最小的)
select stuname from td_student where stubirth=(select min(stubirth) from tb_student);【例】学了python学习这门课,考了做高分的学生姓名
select stuname from tb_student where stuid = (select sid from tb_score where score=(select max(score) from tb_score where cid=(select courseid from tb_course where cname='Python程序设计')) and cid=(select courseid from tb_course where cname='Python程序设计'));
这里有几个问题
【bug1】这里不区分大小写,将Python改为小写的python依然可以执行,这是因为编辑数据为ci(大小写不敏感)
– 将其改为utf8 bin 设置方式:右击编辑数据库–》排序规则:utf8_bin(区分大小写)
【补充】创建数据库的时候设置create database SRS default charset utf8后面加上collate utf_bin
– utf8nb4四字节的utf8,例如苹果系统下图片字符;正常utf-8是8bit一个字节,英文1字节,汉字为3字节
【bug2】若有两个学生相同分数,写等号查不出来,报错子查询返回值多余一行’,这里改为in
select stuname from tb_student where stuid in (select sid from tb_score where score=(select max(score) from tb_score where cid=(select courseid from tb_course where cname='Python程序设计')) and cid=(select courseid from tb_course where cname='Python程序设计'));【例】查询选了3门以及以上的课程的学生姓名
思路:用学号分组,统计一下每组有几个学号,由内往外写
select stuname from tb_student where stuid in (select sid from tb_score group by sid having count(sid)>=3);
十三、案例:人力系统
-- 关系型数据库的数据完整性
-- 1. 实体完整性 - 没有冗余的记录(每条记录都是独一无二的)
-- 主键 / 唯一索引 / 唯一约束
-- 2. 参照完整性 - 列的数据要参照其他表中的列的数据(主键)
-- 外键
-- 3. 域完整性 - 表中的数据都是有效的数据
-- 数据类型 / 非空约束 / 默认值约束 / 检查约束
-- 创建人力资源管理系统数据库
drop database if exists HRS;
create database HRS default charset utf8 collate utf8_bin;
-- 切换数据库上下文环境
use HRS;
-- 删除表
drop table if exists TbEmp;
drop table if exists TbDept;
-- 创建部门表
create table TbDept
(
deptno tinyint not null comment '部门编号',
dname varchar(10) not null comment '部门名称',
dloc varchar(20) not null comment '部门所在地',
primary key (deptno)
);
-- 添加部门记录
insert into TbDept values (10, '会计部', '北京');
insert into TbDept values (20, '研发部', '成都');
insert into TbDept values (30, '销售部', '重庆');
insert into TbDept values (40, '运维部', '深圳');
-- 创建员工表
create table TbEmp
(
empno int not null comment '员工编号',
ename varchar(20) not null comment '员工姓名',
job varchar(20) not null comment '员工职位',
mgr int comment '主管编号',
sal int not null comment '月薪',
comm int comment '月补贴',
dno tinyint comment '所在部门编号',
primary key (empno)
);
-- 添加外键约束
-- 自参照完整性约束
-- alter table TbEmp add constraint fk_mgr foreign key (mgr) references TbEmp(empno);
alter table TbEmp drop constraint fk_mgr;
alter table TbEmp add constraint fk_dno foreign key (dno) references TbDept(deptno) on delete set null on update cascade;
-- 添加员工记录
insert into TbEmp values (7800, '张三丰', '总裁', null, 9000, 1200, 20);
insert into TbEmp values (2056, '乔峰', '分析师', 7800, 5000, 1500, 20);
insert into TbEmp values (3088, '李莫愁', '设计师', 2056, 3500, 800, 20);
insert into TbEmp values (3211, '张无忌', '程序员', 2056, 3200, null, 20);
insert into TbEmp values (3233, '丘处机', '程序员', 2056, 3400, null, 20);
insert into TbEmp values (3251, '张翠山', '程序员', 2056, 4000, null, 20);
insert into TbEmp values (5566, '宋远桥', '会计师', 7800, 4000, 1000, 10);
insert into TbEmp values (5234, '郭靖', '出纳', 5566, 2000, null, 10);
insert into TbEmp values (3344, '黄蓉', '销售主管', 7800, 3000, 800, 30);
insert into TbEmp values (1359, '胡一刀', '销售员', 3344, 1800, 200, 30);
insert into TbEmp values (4466, '苗人凤', '销售员', 3344, 2500, null, 30);
insert into TbEmp values (3244, '欧阳锋', '程序员', 3088, 3200, null, 20);
insert into TbEmp values (3577, '杨过', '会计', 5566, 2200, null, 10);
insert into TbEmp values (3588, '朱九真', '会计', 5566, 2500, null, 10);
-- 查询薪资最高的员工姓名和工资
select ename, sal from tbemp order by sal desc limit 1;
select ename, sal from tbemp where sal=(select max(sal) from tbemp);
-- 查询员工的姓名和年薪((月薪+补贴)*12)
select ename, (sal+ifnull(comm, 0))*12 as total from tbemp order by total desc;
-- 查询有员工的部门的编号和人数
select dno, count(dno) from tbemp group by dno;
-- 查询所有部门的名称和人数
select dname, ifnull(total, 0) as total from tbdept, (select dno, count(dno) as total from tbemp group by dno) tb_emp where deptno=dno;
select dname, ifnull(total, 0) as total from tbdept left outer join (select dno, count(dno) as total from tbemp group by dno) tb_temp on deptno=dno;
-- 查询薪资最高的员工(Boss除外)的姓名和工资
select ename, sal from tbemp where sal=(select max(sal) from tbemp where mgr is not null);
-- 查询薪水超过平均薪水的员工的姓名和工资
select ename, sal from tbemp where sal>(select avg(sal) from tbemp);
-- 查询薪水超过其所在部门平均薪水的员工的姓名、部门编号和工资
select ename, t1.dno, sal, sal-avgsal from tbemp t1 inner join (select dno, avg(sal) as avgsal from tbemp group by dno) t2 on t1.dno=t2.dno and sal>avgsal;
-- 查询部门中薪水最高的人姓名、工资和所在部门名称
create view vw_max_sal as select ename, sal, dname from tbdept inner join (select ename, sal, t1.dno from tbemp t1 inner join (select dno, max(sal) as maxsal from tbemp group by dno) t2 on t1.dno=t2.dno and sal=maxsal) tb_temp on deptno=dno;
-- 视图是查询结果的快照
select * from vw_max_sal;
-- update vw_max_sal set ename='黄小荣' where ename='黄蓉';
create view vw_emp as select empno, ename, job from tbemp;
select * from vw_emp;
update vw_emp set ename='胡二刀' where empno=1359;
explain select ename, sal, dname from tbemp t1 inner join tbdept t2 on deptno=t1.dno inner join (select dno, max(sal) as maxsal from tbemp group by dno) t3 on deptno=t3.dno and sal=maxsal;
-- 查询主管的姓名和职位
explain select ename, job from tbemp where empno in (select distinct mgr from tbemp where mgr is not null);
-- 推荐使用exists/not exists取代in/not in和distinct
explain select ename, job from tbemp t1 where exists (select 'x' from tbemp t2 where t1.empno=t2.mgr);
-- 查询薪资排名4~6名的员工姓名和工资
select ename, sal from tbemp order by sal desc limit 3,3;
-- 删除名为hellokitty的用户
drop user hellokitty;